🌌 序章:幻觉的迷宫
在人工智能的世界里,幻觉(Hallucination)就像一只调皮的狐狸,时不时在模型输出中留下虚假的脚印。无论是多模态大型语言模型(MLLMs),还是单模态的LLMs,这一问题都如影随形。尤其在医疗、法律等高风险领域,幻觉不仅仅是「说错话」那么简单,甚至可能引发灾难性的后果。
而DeCo(Dynamic Correction Decoding,动态校正解码)算法的出现,仿佛为这片迷雾点亮了一盏探路灯。它能否带领我们走出幻觉的迷宫?又是否适用于所有类型的语言模型?让我们一探究竟。
🧠 DeCo的诞生:多模态模型的幻觉克星
DeCo算法由Wang等人于2024年提出,最初的目标是解决多模态大型语言模型(MLLMs)在处理图文任务时的幻觉问题。研究发现,虽然MLLMs在早期层能够准确识别视觉对象,但在深层输出时,语言模型的「知识先验」会压制这些视觉信息,导致模型「看见」了却「说错了」。
DeCo的核心思想是:动态选择早期层的视觉信息,并将其按比例整合到最终输出中,校正模型的决策。这一机制无需重新训练模型,可以直接嵌入各种主流解码策略(如贪婪搜索、核采样、束搜索等),实现「即插即用」。
注解:
- 多模态模型(MLLMs):能同时处理文本和图像等多种输入的AI模型。
- 知识先验:模型在训练中学到的「常识」或「偏见」,有时会压制新输入的信息。
🖼️ DeCo在MLLMs上的表现:数据说话
在InstructBLIP、MiniGPT-4、LLaVA、Qwen-VL等主流MLLMs上,DeCo在图像字幕任务中表现亮眼。以CHAIR和POPE等基准测试为例,DeCo平均将幻觉率降低了10.8%。如下表所示:
| 方法 | CHAIRs | CHAIRi |
|---|---|---|
| 基线 | 45.0 | 14.7 |
| DoLa | 47.8 | 13.8 |
| DeCo | 37.8 | 11.1 |
| DoLa+DeCo | 44.2 | 11.9 |
DeCo不仅能单独发挥作用,与其他解码增强方法(如DoLa)结合时,也能进一步提升模型的可靠性。
📚 DeCo能否拯救LLMs?争议与探索
🧩 LLMs的幻觉:与MLLMs有何不同?
LLMs(如GPT-3、Llama等)只处理文本输入。它们的幻觉主要表现为生成虚假事实、逻辑不一致或与输入不符的信息。而MLLMs的幻觉则常常是「看图说瞎话」——描述不存在的视觉内容。
DeCo在MLLMs中依赖于视觉信息的早期层特性,这一机制在LLMs中是否同样有效?目前学界尚无定论。
🔬 实验数据:DeCo在LLMs上的初步尝试
在DeCo GitHub仓库的实验中,研究者将DeCo应用于llama-7b(一个纯文本LLM),并在StrategyQA和GSM8K两个基准测试上进行了对比:
| 方法 | StrategyQA | GSM8K |
|---|---|---|
| 基线 | 59.8 | 10.8 |
| DoLa | 64.1 | 10.5 |
| DeCo | 61.2 | 10.2 |
| DoLa+DeCo | 60.0 | 9.6 |
可以看到,DeCo在StrategyQA上略有提升,但在GSM8K上反而略有下降。更重要的是,这些测试主要衡量问答准确率,而非直接度量幻觉减缓效果。因此,DeCo在LLMs上能否有效减少幻觉,仍需更多实证研究。
注解:
- StrategyQA:考查推理与常识问答能力的基准。
- GSM8K:小学数学题推理基准。
🛠️ LLMs幻觉减缓的主流策略
既然DeCo在LLMs上的效果尚不明朗,业界和学界又有哪些「杀手锏」来对抗幻觉呢?
🔗 1. 检索增强生成(RAG)
RAG通过实时检索外部知识库,将模型输出锚定在真实、可验证的信息上。例如,企业客服机器人通过RAG可以确保回答基于最新的产品文档,而不是模型记忆中的「旧闻」。
案例:
某电商平台客服机器人,用户问「2025年新款手机支持哪些5G频段?」,RAG会实时检索产品数据库,确保答案准确无误。
🧬 2. 领域特定数据微调
通过在高质量、领域专属的数据集上微调LLM,可以让模型更好地理解专业语境,减少「胡说八道」的概率。例如,医疗领域的LLM经过医学文献微调后,生成的诊断建议更可靠。
🕵️ 3. 后处理与事实验证
生成后,利用自动化事实核查、对抗测试和人工审核等手段,过滤掉幻觉内容。例如,DataRobot的研究显示,后处理机制能显著减少生产环境中的幻觉输出。
🎯 4. 不确定性估计与熵检测
Nature上的最新研究提出,利用「语义熵」检测模型输出的不确定性。当模型对同一问题给出多种含义不同的答案时,说明其「心虚」,此时应警惕幻觉风险。
公式:
其中P(c∣x)P(c| {\boldsymbol{x}})P(c∣x)为生成答案属于语义簇ccc的概率,SE越高,幻觉风险越大。
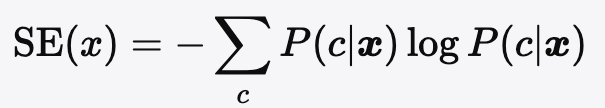
📝 5. 提示工程
通过设计清晰、具体的提示,引导模型聚焦于相关信息,减少「自由发挥」的空间。例如,Lakera的初学者指南强调,明确的任务描述和上下文补充能显著降低幻觉率。
🧭 未来展望:DeCo与LLMs的融合之路
截至2025年5月,DeCo算法在MLLMs上的幻觉减缓效果已被充分验证,但在LLMs上的应用仍处于「摸着石头过河」阶段。部分研究者认为,DeCo的「早期层校正」机制在纯文本模型中可能需要新的实现方式,甚至需要结合RAG、微调等多策略协同。
与此同时,幻觉减缓已成为AI安全与可信赖性的核心议题。无论是DeCo、RAG,还是提示工程,多策略融合、持续评估与人机协作将是未来LLM幻觉治理的主旋律。
📊 附录:DeCo与主流方法对比表
| 方法 | 适用模型类型 | 是否需训练 | 主要机制 | 幻觉减缓效果 | 典型应用场景 |
|---|---|---|---|---|---|
| DeCo | MLLMs(主) | 否 | 动态层校正 | 显著 | 图像字幕、视觉问答 |
| DeCo | LLMs(初探) | 否 | 层校正(待验证) | 不明确 | 文本问答(实验阶段) |
| RAG | LLMs | 否 | 检索增强 | 显著 | 企业知识问答、客服 |
| 微调 | LLMs | 是 | 领域数据训练 | 显著 | 医疗、法律、金融等 |
| 后处理验证 | LLMs/MLLMs | 否 | 自动/人工核查 | 显著 | 生产环境、敏感领域 |
| 提示工程 | LLMs/MLLMs | 否 | 明确任务与上下文 | 显著 | 通用对话、内容生成 |
📚 参考文献与延伸阅读
- MLLM can see? Dynamic Correction Decoding for Hallucination Mitigation
- DeCo GitHub 仓库
- Key Strategies to Minimize LLM Hallucinations: Expert Insights
- 如何减少大型语言模型的幻觉
- 初学者指南:大型语言模型的幻觉
- Detecting hallucinations in large language models using semantic entropy | Nature
- Strategies, Patterns, and Methods to Avoid Hallucination in Large Language Model Responses | Medium
🏁 结语:走出幻觉的迷宫
幻觉,是AI世界里最难缠的「幽灵」。DeCo算法为MLLMs带来了曙光,但在LLMs的幻觉治理上,仍需更多探索与创新。未来,只有多策略协同、持续评估与人机共治,才能让AI真正成为值得信赖的「智慧伙伴」。让我们一起,走出幻觉的迷宫,迎接AI的光明未来!