

在人工智能的浩瀚星海中,大型语言模型如同耀眼的恒星,它们的能力强大而深不可测。然而,这些模型的运作往往需要耗费巨大的计算资源,这也成为了阻碍AI技术广泛应用的一大障碍。今天,让我们一起探索那个改变游戏规则的创新项目——H2O. ��✅
引领潮流的创新:H2O的诞生 🌟
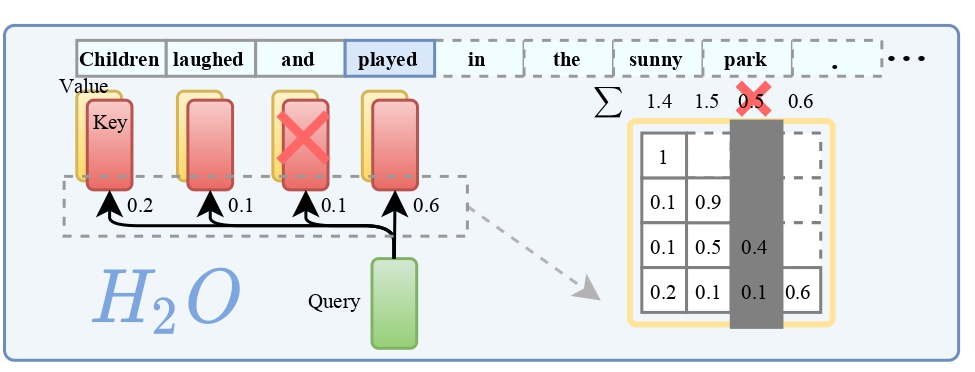
在NeurIPS’23大会上,一项名为H2O的研究引起了广泛关注。这是一种被称作「重点词神器」的技术,它使得大型语言模型的生成变得更加高效。那么,H2O到底是什么呢?
简而言之,H2O是一种优化了的内存管理方案,它通过智能地管理键值(KV)缓存来减轻模型推理过程中的计算负担。KV缓存通常与序列长度和批量大小成线性关系,而H2O能够大幅减少这些缓存的内存占用。
精华所在:重点词的力量 💡
H2O的核心概念在于识别和利用了「重点词」——这些词在计算注意力得分时占有压倒性的重要性。研究者发现,这些词与文本中的频繁共现词强相关,若将它们从模型中移除,性能会大打折扣。H2O正是利用了这一洞察,通过平衡最近词和重点词,优化了KV缓存的管理。
实践证明:H2O的效能 🛠
H2O不仅在理论上前卫,它的实用性也已经在各种任务和不同规模的模型上得到了验证。
实验表明:在保留两成重点词的情况下:
通过H2O优化的大型模型在性能上可以实现高达29倍的吞吐量提升!
这在当前领先的如DeepSpeed Zero-Inference、Hugging Face Accelerate和FlexGen等推理系统中表现尤为突出。
开源精神:与社区共建 🌐
值得庆幸的是,H2O项目已经在GitHub上开源,任何对AI充满热情的开发者和研究者都可以参与其中。无论是想提高你的语言模型生成效率,还是仅仅出于好奇,你都可以在这个平台上找到价值。
结语:跨越技术的鸿沟 ✨
随着H2O的横空出世,那些曾经遥不可及的AI技术现在似乎触手可及。这个项目不仅仅是技术的飞跃,更是开启普通人使用强大AI工具的大门。让我们拭目以待,看看H2O将如何在未来的日子里,继续激起技术革新的波澜!
https://github.com/FMInference/H2O
生成式 大型 语言 模型( llm )因其 在创意 写作 、高 级代 码生 成和
复杂 自 然语 言 处理 任 务方 面 的卓 越 能力 而受 到 关注 [5 ,42 ,49 ]。
这些模 型广泛 部署 在配备 高端 和昂贵 的服 务器级 gp u 的数据
中心中 ,对 我们 的日 常生 活和 工作 实践产 生了 重大 影响 。与
此同时 ,在更 容易 访问的 本地 平台上 运行 llm 的 趋势正 在兴
起,特 别是 带有 消费 级 gp u 的个人电 脑(p c )。这种 演变 是由
增强数 据隐 私[25 ]、 模型 定制[2 2 ]和降低 推理 成本[4 2 ]的需求
驱 动 的 。 与 优 先 考 虑 高 吞 吐 量 的 数 据 中 心 部 署 相 比
[18,37,47 ],本地 部署 侧重于 处理 小批量 时的 低延迟 。
尽管 如此 ,在 消费 级 gp u 上部 署 llm 面临 着巨 大的 挑战 ,因
为 它 们需 要 大 量 的 内 存 。llm ,通常作为自回归的变形器,
按顺 序逐 个符 号生 成文 本, 每个 符号 都需 要访 问由 数千 亿个
参 数组 成 的 整 个模 型 。 因此 , 推 理 过程 从 根 本 上受到 GP U
内存 容量 的限 制。 这种 限制 在本 地部 署中 尤其 严重 ,在 本地
部署 中, 单 个请 求的 处 理(通 常 一次 只 有一 个)[6 ]留 给并 行处
理的机会很 少。
解决这类内存问题的现有方法包括模型压缩和卸载。量
化[1 2 ,46 ]、蒸馏[4 8 ]和剪枝[2 3 ]等压缩技术减少了模型的大
小。 然而 ,即 使是 深度 压缩 的模 型对 于消 费级 gpu 来说 仍然
太大 。例 如,4 位精度 的 OPT-66B 模型仅 加载 其参 数就 需要
大约 4 0 GB 的 内存[2 0 ],甚至 超 过了 N VI DI A RT X 40 90 等高
端 gp u 的容 量。 模型 卸载 , 在 Tra n sfo rm e r 层将模 型划 分为
GP U 和 CP U[3 ,14 ,37 ]。最先进的系统,如 lla ma .cp p [14 ]在
CPU 和 GP U 内存 之间 分配 层, 利用 两者 进行 推理 ,从 而减
少所 需的 GPU 资源 。然 而, 这 种方 法受 到慢速 P CIe 互连和
cpu 有限的计 算能 力的 阻碍 ,导 致较 高的 推理 延迟 。
在本 文中 ,我 们认为 L LM 推 理中 内存 问题 的关 键原 因是
硬 件架 构与 LL M 推理 特 性 之间 的局部性不匹配 。当前 的硬
件架 构设 计了 针对 数据 局部 性优 化的 内存 层次 结构 。理 想情
况下 ,应 该 在 GP U 中 存 储一 个小 的、 经 常访 问的 工作 集,
这样 可以 提供 更高 的内 存带 宽, 但容 量有 限。 相比 之下 ,更
大的 、访 问频 率更 低的 数 据更 适合 c p u ,它提 供更 广泛 的内
存容 量, 但带 宽更 低。 然而 ,每 次 LLM 推理 迭代 所需 的大
量参 数导 致单 个 GP U 的 工作 集太 大, 从 而阻 碍了 有效 的局
部性利用。
在 OPT 模 型中 , 激活 图中 只 有不 到 10 % 的 元素 是非 零 的,
而这些元素在运行时的预测准确率可以达到 93% 以 上[2 1 ]。
值得注意的 是 ,LLM 中的 神经 元 激活 遵循倾斜的幂律分布 :
一小部分神 经 元始 终参 与 各种 输 入(热激活)的 大 多数 激活
(超过 80 % ), 而大 多数 神 经元 参 与剩 余的 激 活, 这些 激 活
是根据运行 时 的输 入(冷激 活 )确定 的 。
在局 部性 见解 的基 础上 ,我 们介 绍 了 PowerInfer,这 是一
个高效的 L LM 推理系统, 使用单个消 费级 GPU 对 本地部署
进行了优化。Po we rInfe r 的关键 思想是利用 L LM 推 理中的局
域性,将少量 的热神经 元分配给 GP U,而 构成大多 数的冷神
经元由 CP U 管理。Po w- e rInfe r 离线预选 和预加载 热激活的
神经元到 GPU 上 ,并在运行 时利用在线 预测器来识 别激活的
神经元。这种方 法允许 GP U 和 CP U 独 立处理各自 的神经元
集,从而最大限度 地减少对昂 贵的 PCI e 数据传 输的需求。
然而 ,有 一些 重大 的挑 战 使 Po we rInf er 的设 计复 杂化 。首
先, 在线 预测 器对 于识别 L LM 层中 的活 动神 经元 至关 重要 ,
通常 位于 G PU 上, 占用 了大 量 的 GPU 内存 。否 则, 这些 内
存 可以 用于 LL M 。为 了 解 决这 个 问 题,Po we rInf e r 引 入了
一种自适应方法,用于为具有较高激活稀疏度和偏度的层
构建较小的预测器。这个迭代过程减少了预测器的大小,
同时 保 持 了它 们 的 准确 性 , 从而 为 L LM 推 理释 放 了 GP U
内存。
Po we rInf e r 的 在 线 推 理 引 擎 是 通 过 添 加 4 200 行 c ++ 和
C U D A 代 码 来扩 展 lla ma .cp p 来实现 的 。它 的离 线 组件 ,包
括一 个 分析 器 和一 个 求 解器 , 建立 在 变压 器 框架 [44 ]上 ,大
约 有 4 00 行 Py th on 代码。p o we re rin f e r 兼 容 各 种 流 行 的
LL M 家 族 , 包 括 OP T (7 B-175 B) , LLa M A (7 B-7 0 B)和
Fa lcon – 40 B, 并 支持 消 费级 gpu , 如 N VI DI A RT X 40 90 和
NVI DI A RTX 2080Ti。