《H2O. Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models》✅
当我们谈论人工智能尤其是语言模型时,你可能会想象一个强大的机器,它能够写作、聊天,甚至创作诗歌。但这背后的真相是,这些模型的运行需要巨大的计算资源,尤其是在处理长篇内容时。然而,科技的步伐从未停歇,一个名为H2O的新工具出现了,它让大型语言模型的应用变得更加高效和便捷。
迈向更高效的未来:H2O的诞生 🌟
有鉴于大型语言模型(LLMs)在部署时所需成本的不断攀升,特别是在长内容生成如对话系统与故事创作领域,研究者们提出了一种全新的解决方案。这个解决方案的核心在于对所谓的KV缓存的智能管理。KV缓存是一种在GPU内存中存储临时状态信息的机制,其大小与序列长度和批处理大小成线性关系。但H2O通过一种创新的方法大幅度降低了KV缓存的内存占用。
重点词(Heavy Hitters):H2O的核心思想 💡
H2O背后的一个关键发现是,在计算注意力得分时,只有少数的词语(我们称之为重点词,H2)占据了大部分的价值。研究表明,这些重点词的出现与文本中词语的频繁共现强烈相关,一旦去除这些重点词,模型的性能会显著下降。
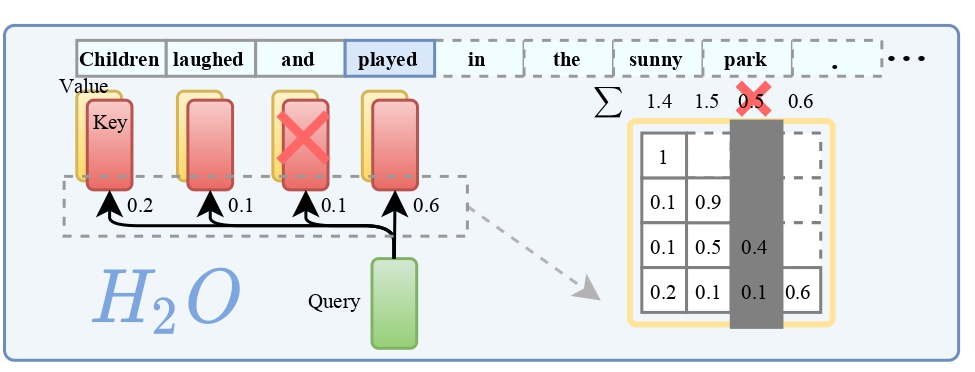
基于这一发现,H2O采用了一种KV缓存淘汰策略,它动态地保留了最近的词和重点词之间的平衡。通过将KV缓存淘汰形式化为一个动态子模块问题,研究者们还为这一算法提供了理论上的保证。
高效实践:H2O的验证与实现 🛠
H2O不仅仅停留在理论上,它的有效性已经在多个任务和不同大小的模型(如OPT和GPT-NeoX)上得到了验证。使用H2O并将重点词的比例设为20%,在OPT-6.7B和OPT-30B上,相比于目前领先的三种推理系统——DeepSpeed Zero-Inference、Hugging Face Accelerate和FlexGen,吞吐量提高了多达29倍。
开源共享:H2O与社区的互动 🌐
H2O项目已在GitHub上开源,任何人都可以访问其代码仓库。项目提供了两种代码实现:
h2o_flexgen:基于FlexGen,用于提升大型语言模型生成的吞吐量。h2o_hf:基于Hugging Face,测试不同基准上的性能,同时提供了模拟代码(掩蔽注意力矩阵)和真实KV淘汰实现。
结语:技术的进步,让创新触手可及 ✨
H2O的出现,不仅是技术的一大步,更是人工智能领域里一个值得纪念的里程碑。它使得原本资源密集的大型语言模型变得更加亲民,让更多的开发者和用户能够享受到AI的好处。
这篇论文介绍了用于高效生成推理的大型语言模型的一种新方法 HO。大型语言模型(LLM)在长内容生成等应用中部署成本过高,比如对话系统和故事写作。通常,大量短暂状态信息(称为 KV 缓存)会存储在 GPU 内存中,除了模型参数外,其大小与序列长度和批量大小成线性关系。在本文中,作者提出了一种新颖的方法来实现 KV 缓存,大大减少了其内存占用。该方法基于一个重要观察:在计算注意力分数时,只有少部分令牌占据了大部分价值。作者将这类令牌称为「重击者」(H)。通过全面的调查,作者发现 (i) H 的出现是自然的,并且与文本中令牌的频繁共现强烈相关;(ii) 移除它们会导致性能显著下降。基于这些洞察,作者提出了重击者预言机(HO),一种动态保留最近和 H 令牌平衡的 KV 缓存替换策略。作者将 KV 缓存替换视为一种动态次模问题,并证明了(在温和的假设下)他们新提出的替换算法的理论保证,有助于指导未来的研究。作者用 OPT、LLaMA 和 GPT-NeoX 在各种任务上验证了他们算法的准确性。将 HO 实现为 20% 的重击者,在 OPT-6.7B 和 OPT-30B 上,超过了 DeepSpeed Zero-Inference、Hugging Face Accelerate 和 FlexGen 等三种领先推理系统的吞吐量,最高可达 29 倍、29 倍和 3 倍。在相同的批量大小下,H2O 最多可以将延迟降低 1.9 倍。代码可在 https://github.com/FMInference/H2O 上找到。
1. 大规模语言模型(LLMs)在自然语言处理任务如内容创作、摘要和对话系统等方面表现出卓越的性能,但部署成本很高。
2. 除了模型规模和注意力层的二次成本外,存储中间注意密钥和值的KV缓存大小问题也变得越来越突出。
3. 一种自然的解决方法是限制其最大大小,就像经典软件或硬件缓存中一样。然而,在LLMs中减少KV缓存内存足迹是具有挑战性的,因为这可能会导致准确性的下降。
4. 虽然存在大量关于稀疏注意力近似的论文,但它们并没有广泛用于缓解KV缓存瓶颈。
5. 大多数现有方法,如Transformer、Flash注意力和Performer,旨在克服注意力机制所需的二次内存,但仍然需要大量的缓存大小。
6. 变种如稀疏Transformer(10)或多查询注意(11,12,5)可以减少缓存大小,但直接应用它们在预训练LLMs上生成结果会导致高丢失率和准确性下降,如图1所示。
7. 最近的一些进展,如gisting tokens(13),可以在生成过程中学习压缩KV缓存,但它们的昂贵删除策略在生成过程中难以部署。
8. 理想的KV缓存应具有(i)较小的缓存大小以减少内存足迹,(ii)低的丢失率以维持LLMs的性能和长内容生成能力,和(iii)低的删除成本以减少生成过程中的墙时钟时间。
9. 然而,存在三个技术挑战。首先,是否可以限制KV缓存的大小不是立即明确的。其次,确定保持生成准确性的最佳删除策略是一个组合问题。最后,即使可以强制实现最佳策略,将其部署在实际应用中也具有不可行的性。
10. 幸运的是,我们初步的探索已经发现了关于LLMs的实证性质的有趣观察。这些发现为设计高效的KV缓存铺平了道路。
11. 对于小缓存大小,我们观察到即使训练密度很高,LLM的注意力矩阵在推理时也超过95%稀疏(如图2所示)。这适用于一系列预训练的LLM。因此,在每个生成步骤中,只需要的KV缓存大小不到5%,这表明可以实现20倍以上的缓存大小减少,而不会导致准确性的下降。
12. 对于低丢失率,我们发现所有注意力块中所有token的累积注意得分遵循 power-law 分布。这表明在生成过程中存在一个小的影响 tokens,称为 heavy-hitters(H2)。H2提供了从组合搜索问题中走出来的机会,确定一个保持准确性的删除策略。