

Ollama GPU支持编译详解
原理、架构与设计思想
info Ollama简介与GPU支持的重要性
Ollama是一个专为本地运行大型语言模型(LLM)设计的开源框架,其核心目标是通过简化模型部署与管理的复杂性,让用户能够高效、灵活地在本地环境中使用大模型。

Ollama图标:羊驼与鲸鱼
GPU支持对Ollama至关重要,因为:
- 大幅提升推理速度,相比CPU可提升数倍至数十倍
- 支持运行更大规模的模型,突破内存限制
- 降低能耗,提高能效比
- 实现更流畅的实时交互体验
architecture Ollama架构设计
Ollama采用经典的客户端-服务端(C/S. ��架构✅,主要由以下组件构成:
客户端(Client)
支持命令行(CLI)、桌面应用(基于Electron框架)或Docker等多种交互方式,负责用户交互和请求发送。
服务端(Server)
包含ollama-http-server(负责处理客户端请求,提供RESTful API接口)和llama.cpp(作为底层推理引擎,负责加载并运行大语言模型)。
通信协议
客户端与服务端、服务端与推理引擎之间均通过HTTP协议交互,确保跨平台兼容性。
存储结构
默认使用$HOME/.ollama文件夹,包括日志文件、密钥文件和模型文件(blobs原始数据文件和manifests元数据文件)。
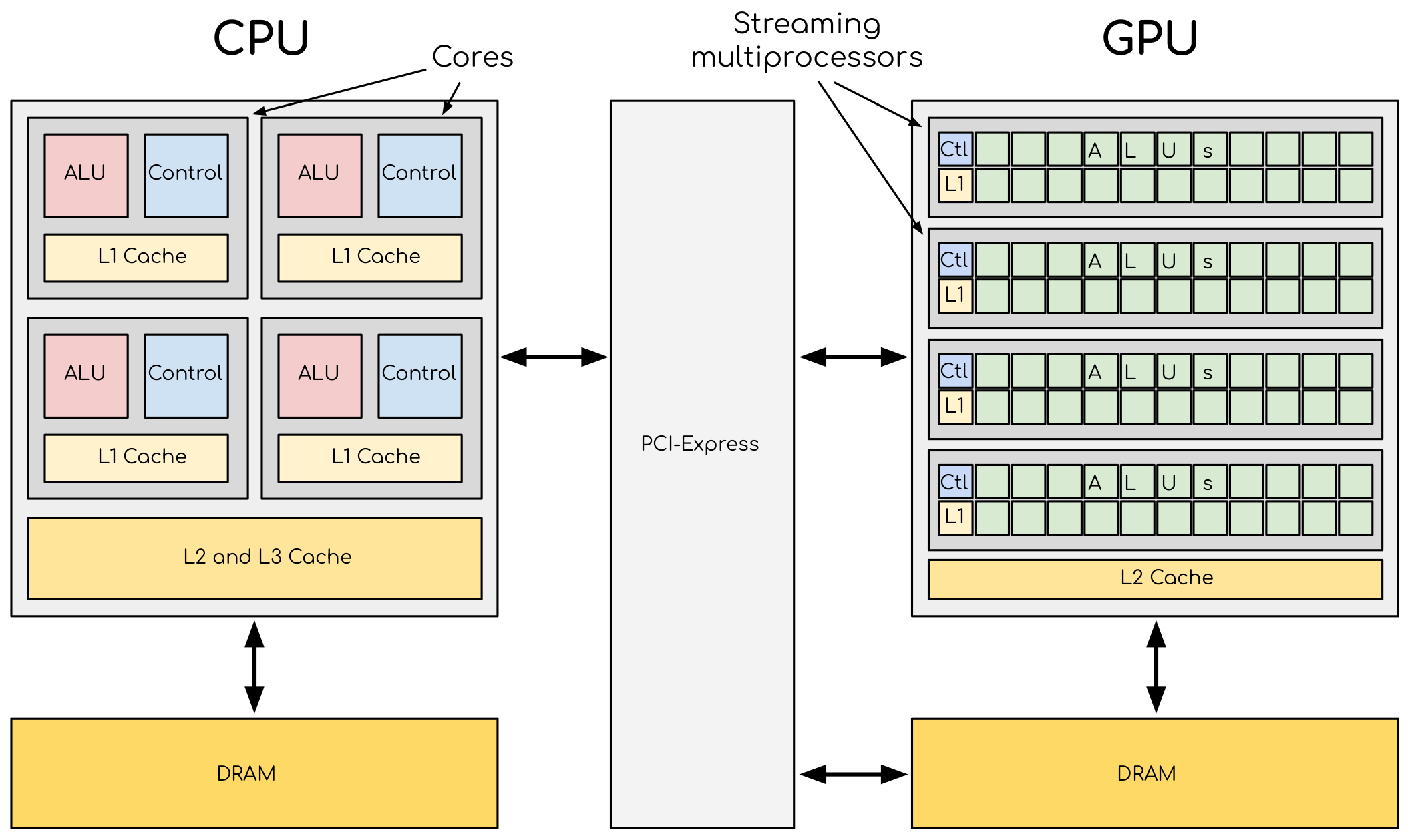
CPU和GPU结构示意图
lightbulb 设计原理
Ollama的核心技术实现包括以下几个方面:
模型优化与推理加速
- 量化技术:通过int8/int4低精度量化,大幅降低模型体积和内存占用,例如13亿参数的DeepSeek Coder模型仅需约800MB。
- 分块处理与缓存优化:将模型计算拆分为多个块处理,减少单次内存需求,同时优化数据缓存策略以提高效率。
- 硬件加速支持:利用SIMD指令集、GPU/TPU加速计算,提升推理速度。
本地化与隐私保护
- 模型和数据完全运行于本地设备,避免依赖云服务,保障数据隐私。
- 默认模型存储路径为$HOME/.ollama,用户可自定义环境变量(如OLLAMA_MODELS)调整存储位置。
灵活扩展性
- Modelfile机制:类似Dockerfile,支持用户自定义模型参数(如温度值、系统提示),并可通过ollama create命令生成定制化模型。
- 预构建模型库:提供丰富的开源模型(如Llama 3、DeepSeek Coder、Qwen等),用户通过ollama pull即可下载使用。
memory GPU支持编译方法
Ollama支持两种主要的GPU加速方案:NVIDIA CUDA和AMD ROCm。下面分别介绍它们的编译方法:
NVIDIA CUDA支持编译
适用于NVIDIA显卡,通过CUDA实现GPU加速。
- 安装CUDA Toolkit(版本需与显卡兼容)
- 安装编译工具:g++、gcc、cmake
- 安装Golang
- 从GitHub拉取Ollama代码
- 执行编译命令:
make -j64 CUDA_11_PATH=/usr/local/cuda-11.4 CUDA_ARCHITECTURES="30;35;37;50;52" - 设置环境变量并启动Ollama
AMD ROCm支持编译
适用于AMD显卡,通过ROCm实现GPU加速。
- 安装AMD HIP SDK for Windows
- 将HIP SDK添加到环境变量中
- 使用hipinfo命令查看显卡信息,确定gcnArchName
- 修改源码,添加对新显卡的支持(如在gfx1030附近添加gfx1032)
- 执行编译命令:
$env:CGO_ENABLED="1"
powershell -ExecutionPolicy Bypass -File .\scripts\build_windows.ps1 - 替换ROCm库文件并重启Ollama
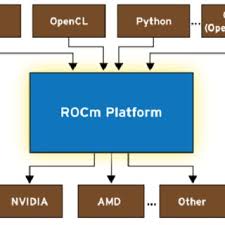
ROCm平台架构图
summarize 总结
Ollama通过整合轻量级推理引擎(llama.cpp)、灵活的模型管理机制和开放的API生态,实现了大语言模型在本地的高效部署与应用。其技术核心在于量化优化、硬件适配和易用性设计,使得开发者无需深入底层细节即可快速构建AI应用。
GPU支持的编译进一步释放了Ollama的潜力,使其能够在本地设备上以更快的速度运行更大规模的模型,为推动AI民主化提供了重要工具。无论是NVIDIA CUDA还是AMD ROCm,通过正确的编译方法,用户都能充分利用GPU加速,获得更流畅的AI体验。
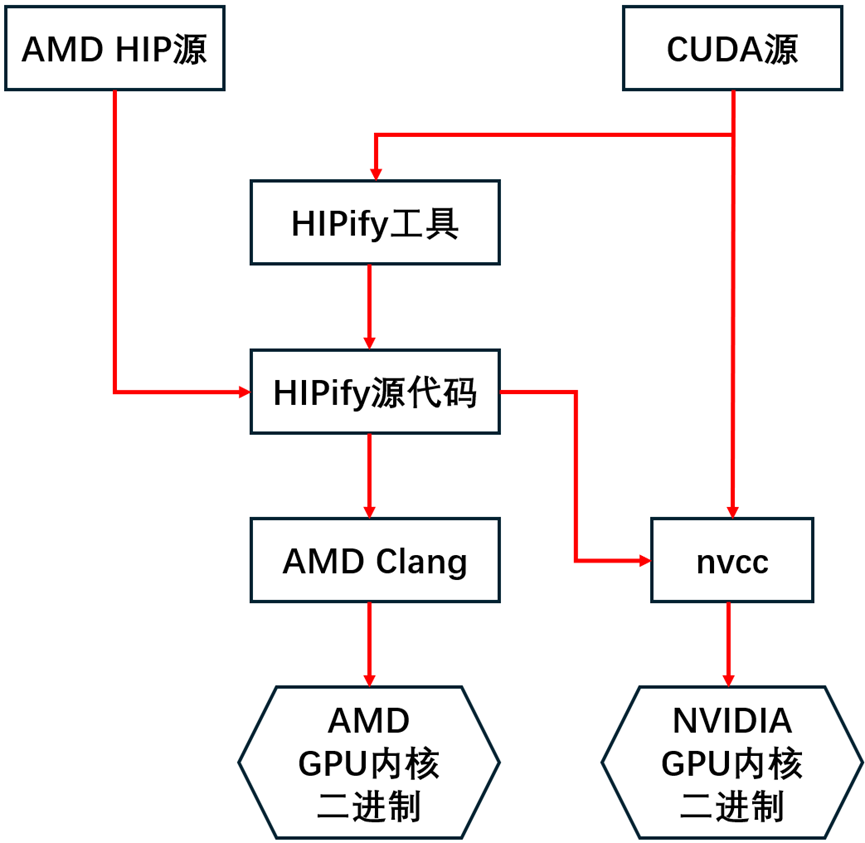
从AMD HIP源到NVIDIA GPU内核二进制的过程