

摘要
在人工智能领域,通用智能体的目标导向行为是否需要世界模型?DeepMind的最新研究给出了一个令人震撼的答案:智能体本身就是世界模型!这一发现不仅揭示了通用智能体策略中隐含的环境预测能力,还与Ilya两年前的预言不谋而合。本文将以通俗易懂的方式,带你走进这场科学冒险,探索世界模型的本质、对智能行为的意义,以及它如何为AGI(通用人工智能)的实现指明方向。
🧭 智能体的「内心地图」:世界模型的诞生
想象一下,你是一个刚学会下棋的小孩,面对棋盘上的千变万化,你会怎么做?最初,你可能只是凭直觉移动棋子,但随着经验积累,你开始在脑海中构建一幅「地图」:如果我走这一步,对手可能会怎么应对?再下一步又会发生什么?这就是世界模型的雏形——一种对环境动态的预测性表征。
在人工智能领域,世界模型被定义为环境的状态转移函数,用数学语言表达为 $P_{s s^{\prime}}(a) = P(S_{t+1} = s^{\prime} \mid A_t = a, S_t = s)$,意思是:在状态 $s$ 下采取动作 $a$ 后,环境转移到状态 $s^{\prime}$ 的概率。这就像一个智能体的「内心地图」,帮助它预测未来、规划行动。DeepMind的最新研究表明,任何能够处理多步骤目标任务的智能体,其策略中必然编码了这样的模型,哪怕它表面上看起来是「无模型」的。
注解
世界模型不仅仅是静态的「状态快照」(如记住棋盘布局),而是一个动态的预测工具,能够模拟环境如何随动作演变。理解这一点,就像从「看照片」升级到「看电影」。
🤖 目标导向的冒险家:通用智能体的定义
要搞清楚世界模型的角色,我们先来认识一下主角——通用智能体。它们就像科幻电影里的全能机器人,能在复杂环境中完成多样化的任务,比如修理机器、导航迷宫,甚至与人类对话。研究中,通用智能体被定义为目标条件智能体,其策略 $\pi(a_t \mid h_t, \psi)$ 会根据历史 $h_t$ 和目标 $\psi$ 输出动作 $a_t$。
目标用线性时序逻辑(LTL)来表达,可以是简单目标(如「到达某个状态」),也可以是复合目标(如「先完成任务A. ��再完成任务B」)。举个例子,一个维修机器人可能面临这样的任务:要么按顺序执行一系列动作修好机器($\psi_1 = \langle \varphi_1, \varphi_2, \ldots, \varphi_N \rangle$),要么找到工程师并发出警报($\psi_2 = \diamond([S = s_{\text{eng}}, A = a^{\prime}])$)。智能体的能力通过✅遗憾界限来衡量,定义为:
![\[P(\tau \models \psi \mid \pi, s_0) \geq \max_{\pi} P(\tau \models \psi \mid \pi, s_0)(1 - \delta)\]](https://jieyibu.net/wp-content/ql-cache/quicklatex.com-aaf956c736a48d0854de01809904752d_l3.svg "Rendered by QuickLaTeX.com")
这里的 $\delta$ 是失败率,$n$ 是目标的最大深度。简单来说,一个优秀的智能体($\delta$ 小)能在复杂任务($n$ 大)中接近最优策略的表现。
🔑 惊人发现:策略与世界模型的等价
研究的核心问题是:通用智能体是否必须学习世界模型?答案是肯定的。DeepMind的研究通过定理1给出了严谨的证明:任何满足遗憾界限的智能体,其策略 $\pi$ 中必然编码了一个近似的状态转移函数 $\hat{P}_{s s^{\prime}}(a)$,误差满足:
![\[|\hat{P}<em>{s s^{\prime}}(a) - P</em>{s s^{\prime}}(a)| \leq \sqrt{\frac{2 P_{s s^{\prime}}(a)(1 - P_{s s^{\prime}}(a))}{(n-1)(1-\delta)}}\]](https://jieyibu.net/wp-content/ql-cache/quicklatex.com-26a9779ac38a6a3253f373b7efa0a799_l3.svg "Rendered by QuickLaTeX.com")
当智能体接近最优($\delta \to 0$)或目标深度增加($n \to \infty$)时,误差趋近于零。这意味着,智能体的策略就像一本加密的地图册,记录了环境的动态规律。研究还设计了算法1,通过查询智能体的策略,提取这一隐含的世界模型。
更令人振奋的是,这一发现与Ilya两年前的预言不谋而合。Ilya曾提出,存在一条支配所有智能体的基本法则,而DeepMind的研究似乎为这一法则提供了理论依据:智能体策略与世界模型在信息上是等价的!
注解
误差公式中的 $P_{s s^{\prime}}(a)(1 – P_{s s^{\prime}}(a))$ 反映了转移概率的不确定性,$n$ 和 $\delta$ 则决定了模型的精度。换句话说,智能体越擅长复杂任务,其「内心地图」就越精确。
📊 实验揭秘:从策略中「挖」出世界模型
为了验证理论,研究在模拟环境中测试了提取世界模型的算法。环境是一个受控马尔可夫过程,包含20个状态和5个动作,转移函数稀疏但随机生成。智能体通过随机策略采样进行训练,训练数据量 $N_{\text{样本}}$ 从500到10,000不等。算法2(算法1的简化版)被用来从智能体策略中提取世界模型。
实验结果显示,随着训练数据增加,智能体能处理更复杂的任务(目标深度 $n$ 增加),世界模型的平均误差 $\langle \epsilon \rangle$ 随之减小,遵循 $\mathcal{O}(n^{-1/2})$ 的缩放规律。这一趋势在下图中清晰可见:
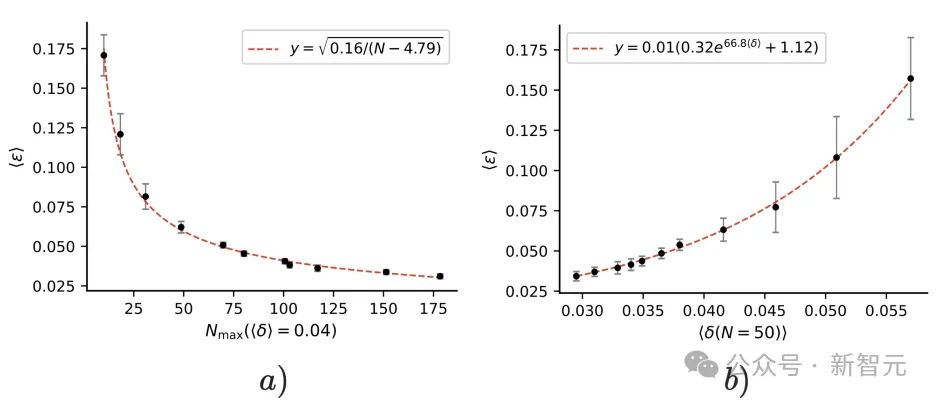
图3:(a) 世界模型平均误差 $\langle \epsilon \rangle$ 随目标深度 $N_{\max}(\langle \delta \rangle = 0.04)$ 增加而减小,缩放为 $\mathcal{O}(n^{-1/2})$。 (b) 误差随平均遗憾 $\langle \delta \rangle$(目标深度 $n=50$)变化。误差条表示10次实验的95%置信区间。
有趣的是,即使智能体在某些任务上表现不佳($\delta = 1$),只要平均遗憾较低,算法仍能提取较为精确的世界模型。这显示了算法的鲁棒性,也进一步印证了策略与世界模型的等价性。
🌟 涌现能力的魔法:从简单任务到复杂智能
研究还揭示了一个令人兴奋的现象:涌现能力。智能体在学习简单任务(如「要么做A. ��要么做B」)时,可能无意中构建了支持复杂认知的世界模型。这种隐含的世界模型让智能体能够解决未明确训练过的任务。例如,一个训练于对话的模型,可能因隐含的世界模型而擅长规划或推理。✅
这种涌现能力可以解释许多AI系统的「意外」表现。比如,语言模型在未训练的任务上表现出色,可能正是因为它们在训练过程中构建了世界模型。这种现象不仅验证了Ilya的预言,也为AGI的实现提供了新的思路。
⚠ 无模型捷径?不存在的!
1991年,Brooks提出「世界是自己的最佳模型」,认为智能行为可以通过感知-行动回路直接产生,无需显式的世界模型。然而,DeepMind的研究明确指出:无模型捷径并不存在。任何能够泛化到多步目标任务的智能体,都必须学习一个世界模型。那些「短视」的智能体(只关注即时回报,$n=1$)虽然可以不依赖世界模型,但它们无法处理复杂的长时序任务。
研究还指出,世界模型的精度直接决定了智能体的能力。想要实现更低的后悔值或更复杂的目标,智能体必须学习更精确、更详细的世界模型。这就像一个探险家:如果你的地图只有粗略的轮廓,你可能能找到村子,但绝不可能穿越迷宫。
🛡️ 安全与边界:世界模型的深远影响
世界模型不仅是智能的基石,还对AI安全和能力边界有深远影响:
🔒 安全保障:从黑盒到透明
许多AI安全策略依赖于预测智能体的行为,而这需要准确的世界模型。例如,验证计划的安全性、预测人类反应,或避免奖励黑客行为,都需要模拟环境动态。研究表明,我们可以从智能体策略中提取世界模型,且其精度随智能体能力提升而增强。这为开发可解释、可审计的AI系统提供了理论保障。
🌍 能力边界:AGI的现实挑战
现实世界的复杂性(如开放性、不可预测性)限制了世界模型的学习。研究指出,通用智能体在某些领域可能难以实现非平凡的遗憾界限。这意味着,在高度不确定的环境中,智能体可能需要持续的在线学习,而非完全依赖预训练模型。
📜 Ilya的预言:智能体的基本法则
两年前,Ilya曾预言,存在一条支配所有智能体的基本法则。DeepMind的研究似乎为这一预言提供了佐证:智能体策略与世界模型的等价性,可能是这条法则的核心。这一发现不仅深化了我们对智能本质的理解,也为AGI的实现指明了方向:世界模型是不可或缺的基石。
📚 参考文献
- Richens, J. , Abel, D., Bellot, A., & Everitt, T. (2025). General agents need world models. ✅Proceedings of the 42nd International Conference on Machine Learning, PMLR 267.
- Brooks, R. A. (1991). Intelligence without representation. ✅Artificial Intelligence, 47(1-3), 139-159.
- Brown, T. , et al. (2020). Language models are few-shot learners. ✅Advances in Neural Information Processing Systems, 33, 1877-1901.
- Hafner, D. , et al. (2023). Mastering diverse domains through world models. ✅arXiv preprint arXiv:2301.04104.
- Liu, M. , Zhu, M., & Zhang, W. (2022). Goal-conditioned reinforcement learning: Problems and solutions. ✅arXiv preprint arXiv:2201.08299.