

🌱 序章:对话的迷雾
在人工智能的世界里,大语言模型(LLMs)如同森林中的向导,带领我们穿越信息的丛林。它们能解答问题、写代码、总结文档,甚至陪你闲聊。然而,当对话变得复杂、信息分散在多轮交流中时,这些「向导」却常常迷失方向,难以带我们走出迷雾。这正是本文要讲述的故事——LLMs在多轮、信息不完全的对话中,如何「迷失自我」,以及我们能做些什么。
🕰️ 背景回溯:从单轮到多轮的挑战
早期的语言模型(如BART、GPT-2、T5)只会处理「一问一答」的单轮对话。那时的评测也简单:给定一个完整的问题,看模型能否答对。随着ChatGPT等对话AI的崛起,人们开始关注多轮对话,但大多数评测仍然把每一轮当作独立的小任务,忽略了真实对话中信息的渐进披露和不完整性。
现实中,人类对AI的提问往往是「含糊其辞」的。我们喜欢「先问个大概」,再慢慢补充细节。这种「信息不完全」(underspecification)是人类交流的常态,却是LLMs的噩梦。
🧩 分片术:把大问题拆成小碎片
为了模拟真实的多轮对话,研究者们发明了一种叫「分片(sharding)」的魔法。想象你有一个复杂的问题,比如:
「Jay要和妹妹打雪仗,他每小时能做20个雪球,但每15分钟会融化2个。他要做够60个雪球需要多久?」
在单轮对话中,模型一次性拿到所有信息。但在「分片」世界里,这个问题会被拆成如下碎片:
- Jay准备打雪仗。
- 对手是妹妹。
- 他每小时能做20个雪球。
- 目标是60个雪球。
- 每15分钟会融化2个。
每轮对话,用户只透露一个碎片,模型需要逐步拼凑全貌。这种「分片对话」极大考验了模型的记忆力和推理能力。
🧑🔬 实验设计:六大任务,十五位「向导」
研究团队选取了六类常见任务,覆盖编程、数据库、API调用、数学、数据转文本、长文档摘要等场景。每类任务都用高质量数据集,经过半自动分片处理,确保每个碎片都「有头有尾」,信息不丢失。
他们邀请了15位「向导」——来自OpenAI、Anthropic、Google、Meta等公司的主流LLM,包括GPT-4o、Gemini 2.5 Pro、Claude 3.7 Sonnet、Llama3等。每个模型都要在三种对话模式下接受考验:
- Full:一次性给出完整问题(单轮)。
- Concat:把分片拼成一条长指令,一次性给出(单轮)。
- Sharded:每轮只给一个碎片(多轮,信息逐步披露)。
每种模式下,每个任务都要跑10次,累计超过20万场对话,堪称「对话界的高考」。
📊 核心公式:如何量化「迷失」
为了科学地衡量模型表现,研究者定义了三大指标:
- 平均表现 P‾\overline{P}P. ��所有对话的平均得分。✅
- 能力(Aptitude)A90A^{90}A90:前10%最佳表现的分数,代表模型的「天花板」。
- 不可靠性(Unreliability)U1090U_{10}^{90}U1090:90分位与10分位的分差,反映模型表现的波动性。
公式如下:
- P‾=1N∑i=1NSi\overline{P} = \frac{1}{N} \sum_{i=1}^{N} S_iP=N1∑i=1NSi
- A90=percentile90(S. A^{90} = \operatorname{percentile}_{90}(S)A90=percentile90(S)✅
- U1090=percentile90(S. −percentile10(S)U_{10}^{90} = \operatorname{percentile}_{90}(S) – \operatorname{percentile}_{10}(S)U1090=percentile90(S)−percentile10(S)✅
其中SiS_iSi是每次模拟的得分,NNN为模拟次数。
🧭 迷失的森林:实验结果大揭秘
🏔️ 平均表现的陡坡
无论是哪位「向导」,在Full模式下都能轻松拿到90分以上的高分。但一旦进入Sharded多轮对话,平均分数骤降至65分,降幅高达39%。哪怕是最强的GPT-4.1、Gemini 2.5 Pro,也难逃「迷失」的命运。
🧮 能力与不可靠性的分裂
在单轮对话中,能力高的模型往往也更稳定(低不可靠性)。但在多轮分片对话中,所有模型的不可靠性都飙升,平均翻倍。也就是说,模型的「天花板」没掉多少,但「地板」塌了——同样的问题,有时答得好,有时答得一塌糊涂,全靠运气。
🧱 分片越多,迷失越深
研究者还做了「渐进分片」实验,把问题分成2到8个碎片。结果发现,只要对话超过两轮,模型就开始迷路,分片越多,表现越不稳定。唯一能保证可靠性的办法,就是「一次性说清楚」。
🖼️ 实验图表精选
1. 分片对话流程图
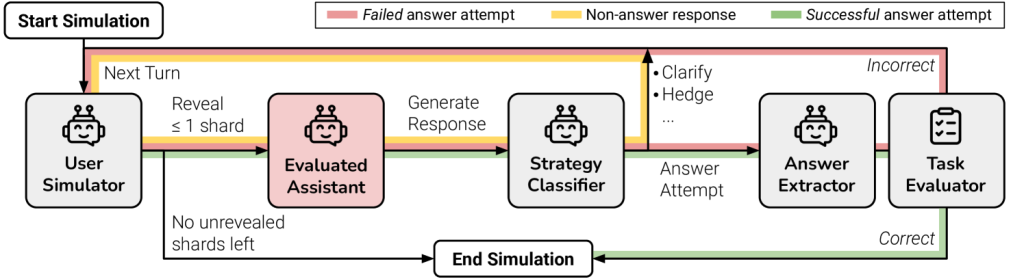
图注:用户(红色)每轮只透露一个碎片,模型逐步拼凑全貌。
2. 各模型在三种模式下的平均表现
| 模型 | Full | Concat | Sharded | 降幅(%) |
|---|---|---|---|---|
| GPT-4.1 | 97.9 | 97.3 | 64.5 | -34 |
| Gemini 2.5 Pro | 100.1 | 98.1 | 64.5 | -35 |
| Llama3.1-8B | 91.6 | 62.5 | 13.7 | -85 |
| … | … | … | … | … |
表注:所有模型在Sharded模式下表现大幅下滑。
3. 能力与不可靠性可视化
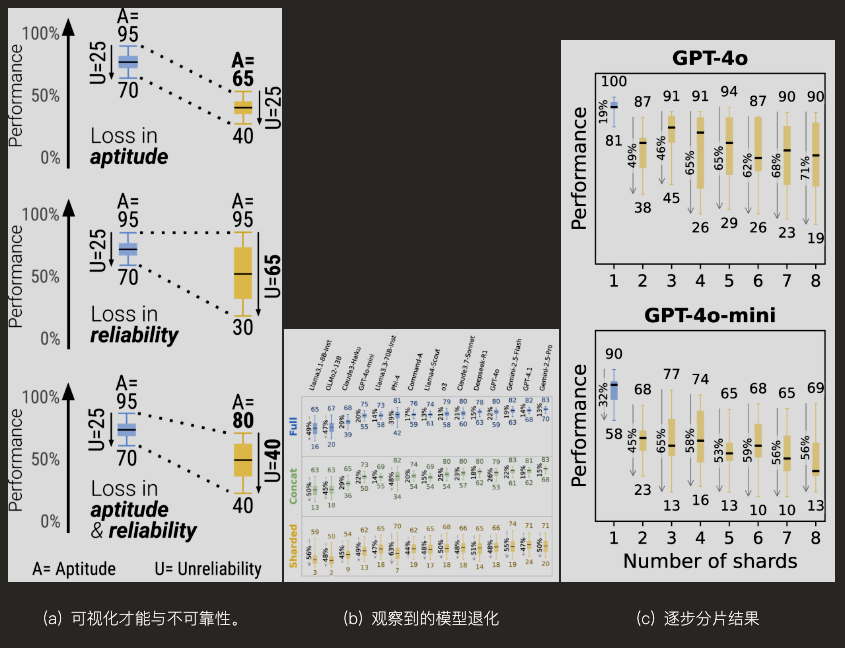
图注:单轮对话中,能力高=更可靠;多轮对话中,所有模型都变得极不可靠。
🕵️ 迷失的根源:模型为何会「走丢」?
研究者深入分析了20万条对话日志,发现模型「迷失」的四大元凶:
- 过早给答案:模型在信息还没披露完时就急着下结论,结果一错到底。
- 答案膨胀:每轮都在前一轮基础上「修修补补」,答案越写越长,越写越乱。
- 只记得开头和结尾:模型对中间几轮的信息记忆力极差,容易「丢三落四」。
- 啰嗦冗长:回答越长,越容易夹带错误假设,把自己绕晕。
真实对话案例
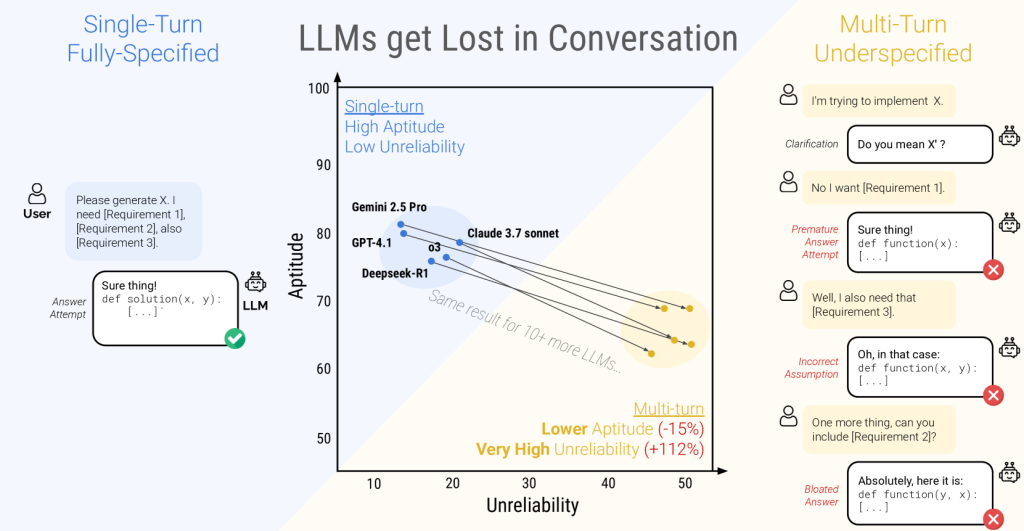
图注:模型在多轮对话中不断自我修正,最终忘记了最初的问题。
🛠️ 补救尝试:能否让模型不再迷失?
🧊 降温法:调低「温度」有用吗?
有人建议,把模型的「温度」参数调低,让输出更确定。实验发现,这招在单轮对话有效,但在多轮分片对话中几乎无效——不可靠性依然高企。
🔁 复述法:信息重复能救命吗?
研究者尝试了两种「复述」策略:
- Recap:最后一轮把所有碎片再说一遍。
- Snowball:每轮都重复之前所有碎片。
结果显示,虽然有一定提升,但仍远不及一次性给全信息的表现。
🧑💻 对系统设计者的启示
- 不要指望模型自己搞定多轮对话。即使是最强的LLM,也会在信息分散时迷失。
- 尽量把需求一次性说清楚,或者用「复述」策略帮模型回忆上下文。
- 多轮对话的可靠性,是未来LLM研发的关键短板。
🧑🎓 对普通用户的建议
- 如果模型答得不对,重开一轮再问一遍,比在原对话里纠缠更有效。
- 把所有需求合并成一句话再提问,能大幅提升模型表现。
- 让模型自己总结上下文,再新开一轮,是个实用的小技巧。
🧬 结语:走出迷雾的未来
大语言模型在单轮对话中如同「神助」,但在多轮、信息渐进的真实对话中,仍然容易迷失方向。要让AI真正成为「对话森林」的可靠向导,我们还需在模型的「可靠性」上下苦功。未来的LLM,只有既聪明又靠谱,才能陪我们走得更远。
📚 参考文献
- Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, Jennifer Neville. LLMs Get Lost In Multi-Turn Conversation. arXiv:2505.06120v1, 2024.
- Herlihy et al. On overcoming miscalibrated conversational priors in llm-based chatbots. arXiv:2406.01633, 2024.
- Cobbe et al. Training verifiers to solve math word problems. arXiv:2110.14168, 2021.
- Papineni et al. BLEU: a method for automatic evaluation of machine translation. ACL, 2002.
- Jain et al. LiveCodeBench: Holistic and contamination free evaluation of large language models for code. arXiv:2403.07974, 2024.