
想象一下,你有一座堆满书籍的图书馆,但你只有一天时间挑选出最有价值的几本书来学习。面对浩如烟海的知识,你会怎么选?在人工智能(AI)的世界里,训练大型语言模型(LLM)也面临类似的难题:从海量数据中挑选出高质量、多样化的指令数据,才能让模型更聪明地回答问题、解决问题。传统方法要么靠人工精挑细选,要么用简单的规则筛选,效率低且效果有限。现在,一项名为MIG(Maximize Information Gain)的技术横空出世,通过「最大化信息增益」自动挑选数据,让AI在更少的数据上学到更多知识!今天,我们就来聊聊MIG的「选书」魔法,以及它如何为AI的指令微调注入新活力!
📚 AI的「图书馆」难题:数据多不等于学得好
大型语言模型(LLM),如LLaMA或Mistral,堪称知识的「超级图书馆」。它们通过大规模预训练学会了语言的「套路」,但要让它们真正听懂人类指令、解决复杂问题,还需要指令微调(Instruction Tuning)。这就像让一个博学的书呆子学会如何回答考试题目:不仅要知道答案,还要懂怎么推导。
然而,指令微调的关键在于数据质量和多样性,而非数据数量。研究发现,用1000条精心挑选的高质量指令数据,就能让模型达到甚至超过用百万条普通数据训练的效果(比如LIMA模型)。但问题来了:人工挑选数据费时费力,而现有的自动挑选方法往往不够聪明。它们要么只关注数据质量(比如指令的复杂程度),要么用简单的规则保证多样性(比如按类别均匀采样),却忽略了数据的整体信息分布。这就像在图书馆里只挑厚书或只选不同类别的书,很难保证选出的书组合能覆盖最多的知识点。
MIG(Maximize Information Gain)提出了一种全新的思路:通过构建一个「语义标签图」,量化数据的「信息含量」,然后用「最大化信息增益」的策略,挑选出既高质量又多样化的数据子集。这种方法就像一个聪明的图书管理员,不仅挑出好书,还确保书的主题覆盖面广、内容不重复!
🧠 MIG的魔法:用标签图「看透」数据
MIG的核心在于用数学的方式「看透」数据的价值。它把数据集想象成一个巨大的「语义空间」,然后通过以下步骤挑选出最有价值的「知识点」:
- 构建标签图:语义空间的地图
MIG将数据集中的每条指令看作一个「知识点」,并为它打上标签(比如「数学」「编程」「对话」)。这些标签就像图书馆的书籍分类,但MIG更进一步:它不仅记录标签,还分析标签之间的关系。比如,「代数」和「几何」虽然是不同标签,但它们在语义上有关联。MIG用一个标签图(Label Graph)来表示这种关系:
- 标签是图的节点(比如「代数」「几何」)。
- 标签之间的语义相似性是边的权重(比如「代数」和「几何」的相似性可能较高)。 通过计算标签的文本相似性(用E5-Mistral-7B-Instruct模型),MIG构建了一个加权图,边的权重反映了标签的语义关联强度。为了效率,MIG会去掉权重低于阈值(比如0.9)的边,避免图过于复杂。
- 量化信息:质量与多样性的平衡
每条指令数据都有一个质量分数(用DEITA评分,综合考虑指令复杂度和回答质量)和一组关联标签。MIG将数据的「信息」分配到标签图的节点上,质量高的数据贡献更多信息。为了避免信息过于集中在热门标签(比如「对话」),MIG用一个上凸函数(如 $\phi(x) = x^{0.8}$)来计算标签的信息量。这个函数有个巧妙的特点:信息增量随着已有信息增加而递减,鼓励模型优先选择覆盖稀有标签的数据,从而保证多样性。 - 信息传播:捕捉语义关联
标签之间并非完全独立。比如,一条关于「代数」的指令可能也包含「数学思维」的知识。MIG通过信息传播机制,让数据的信息沿着标签图的边流动,调整每个标签的信息量。这种传播就像知识在相关领域之间的「涟漪效应」,确保信息分布更准确。传播强度由参数 $\alpha$ 控制(实验中 $\alpha=1.0$ 效果最佳)。 - 最大化信息增益:贪心挑选数据
MIG的目标是从数据池中选出 $N$ 条数据,最大化整个子集的信息量。直接计算所有可能的组合太复杂(组合数随数据量指数增长),所以MIG利用信息量函数的亚模性(submodularity),采用贪心算法:每次挑选能带来最大信息增益的数据。具体来说,MIG计算当前标签图的「信息梯度」,然后选择能最大化梯度贡献的数据。这种策略就像在图书馆里每次挑一本能补充最多新知识的书。
下图展示了MIG的流程:
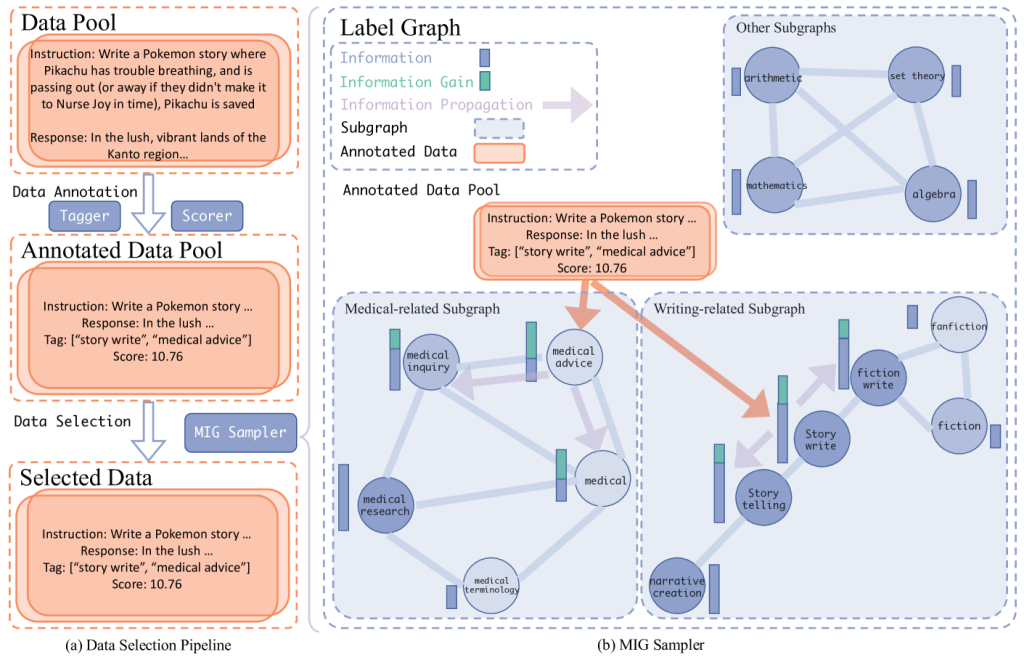
图1:MIG的数据选择流程。先为数据打标签和评分,构建标签图,然后通过最大化信息增益挑选数据,用于模型微调。
📊 MIG的「考试」成绩:少数据,大提升
研究者在三个大型数据集上测试了MIG的实力:Tulu3(百万级混合数据)、Openhermes2.5(百万级多源数据)和$X_{sota}$(30万条高质量对话数据)。他们用LLaMA3.1-8B. ��Mistral-7B和Qwen2.5-7B作为基础模型,并在知识类(ARC、MMLU等)和人类偏好类(AlpacaEval、MTBench等)基准上评估性能。结果令人振奋!✅
Tulu3上的表现:5%数据媲美全量
在Tulu3数据集(939K条)上,MIG从50K条数据(约5%)中挑选子集,训练出的模型在9个基准上的平均得分(Avg)达到55.32%,比全量数据集训练的模型(53.59%)高出1.73%。尤其在人类偏好基准上,MIG提升了4.59%,比如在AlpacaEval上得分14.66%,远超其他方法。如下表所示:
| 方法 | 数据量 | ARC | MMLU | HumanEval | $\text{Avg}_{\text{obj}}$ | AlpacaEval | WildBench | $\text{Avg}_{\text{sub}}$ | Avg |
|---|---|---|---|---|---|---|---|---|---|
| 全量 | 939K | 69.15 | 65.77 | 63.41 | 68.79 | 8.94 | -24.66 | 38.40 | 53.59 |
| Random | 50K | 74.24 | 63.86 | 51.22 | 64.25 | 8.57 | -22.15 | 39.36 | 51.81 |
| DEITA | 50K | 78.98 | 64.00 | 49.39 | 66.15 | 10.19 | -19.95 | 39.50 | 52.83 |
| QDIT | 50K | 79.66 | 65.06 | 53.05 | 65.21 | 15.78 | -20.56 | 41.03 | 53.12 |
| MIG | 50K | 80.00 | 64.44 | 57.93 | 67.64 | 14.66 | -17.77 | 42.99 | 55.32 |
表1:MIG在Tulu3上与基线方法的对比,显示其在知识和偏好基准上的优越性。
跨模型与数据集的通用性
MIG在Mistral-7B和Qwen2.5-7B上也表现出色,平均得分分别提升1.85%和1.31%。在Openhermes2.5和$X_{sota}$数据集上,MIG同样领先,证明了其对不同数据池和模型的通用性。尤其在$X_{sota}$上,MIG缓解了其他方法偏向多轮对话数据的倾向,保持了数学和代码任务的性能。
数据缩放:少即是多
MIG在不同数据量(10K到50K. ��下的表现始终优于基线。如下图所示,用20K条数据,MIG已接近全量数据集的性能,展现了惊人的效率:✅
⚡ MIG的效率秘诀:快如闪电
除了性能优越,MIG在计算效率上也碾压了基于嵌入的方法(比如QDIT和DEITA)。这些方法需要计算高维嵌入的成对距离,耗时长、内存占用大。MIG则在语义标签图上操作,避开了繁重的距离计算。在Tulu3的50K采样任务中,MIG仅用0.45秒,相比QDIT(86.17秒)和DEITA(81.56秒)快了100多倍!如下表:
| 方法 | 时间(秒) | GPU需求 |
|---|---|---|
| Random | 0.09 | 无 |
| DEITA | 81.56 | 是 |
| QDIT | 86.17 | 是 |
| MIG | 0.45 | 是 |
表2:MIG在Tulu3上的采样效率,远超嵌入方法。
🔍 MIG的「魔法配方」:细节决定成败
MIG的成功离不开几个关键设计,研究者通过实验验证了它们的有效性:
- 信息函数:平衡质量与多样性
MIG测试了两种信息函数:$\phi(x) = 1 – e^{-\alpha x}$ 和 $\phi(x) = x^{\alpha}$。结果显示,$\phi(x) = x^{0.8}$ 在知识和偏好基准上表现最佳,因为它能有效鼓励稀有标签的选择,保持多样性。 - 质量评分:DEITA最优
研究比较了三种质量评分:标签数量、IFD分数和DEITA分数。DEITA综合考虑指令复杂度和回答质量,效果最好,成为MIG的默认选择。 - 标签图参数:适度为王
- 节点数量:标签数量(节点)影响覆盖范围。实验发现,4531个标签在Tulu3上效果最佳,过多或过少都会降低性能。
- 边密度:边权重阈值控制图的稀疏性。阈值0.9效果最佳,过密或过稀疏都会引入噪声或丢失关联。
- 信息传播:传播强度 $\alpha=1.0$ 使信息分布更准确,提升了2.76%的平均得分。
⚖ MIG的局限与未来
尽管MIG表现亮眼,但它也有局限:参数(如标签数量、边阈值、传播强度)需要通过网格搜索手动调整,灵活性有限。未来,研究者可以探索以下方向:
- 自适应参数:开发算法自动调整标签图参数,适应不同数据集。
- 动态信息函数:为不同标签定制信息函数,进一步优化质量与多样性的平衡。
- 多模态扩展:将MIG应用于图像、语音等数据,扩展到多模态模型的微调。
🎉 结语:MIG点燃AI的「知识火花」
MIG就像一个聪明的图书管理员,在海量数据中精准挑选出「黄金子集」,让AI用更少的数据学到更多知识。通过标签图、信息传播和最大化信息增益,MIG不仅提升了指令微调的性能,还大幅降低了计算成本。它的成功告诉我们:在AI训练中,聪明的数据选择比盲目堆砌数据更重要。
正如一句老话所说:「少即是多。」MIG用5%的Tulu3数据,达到了甚至超过了全量数据的效果,为AI的未来指明了一条高效之路。让我们期待MIG在更多场景中大放异彩,点燃AI的「知识火花」!
参考文献
- Chen, Y. , et al. (2025). MIG: Automatic Data Selection for Instruction Tuning by Maximizing Information Gain in Semantic Space. arXiv:2504.13835.✅
- Liu, W. , et al. (2024). What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning. ICLR.✅
- Lu, K. , et al. (2024). #InsTag: Instruction Tagging for Analyzing Supervised Fine-Tuning of Large Language Models. ICLR.✅
- Zhou, C. , et al. (2023). LIMA: Less Is More for Alignment. NIPS.✅
- Bukharin, A. , et al. (2024). Data Diversity Matters for Robust Instruction Tuning. EMNLP.✅