AgentFly
无需更新LLM即可微调代理,支持持续学习
lightbulb核心概念与价值主张
AgentFly是一种创新的AI代理框架,其核心价值在于无需更新底层大语言模型(LLM)即可实现代理的微调和持续学习。这一突破性设计解决了传统AI代理系统中的两大痛点:
- 微调成本高:传统方法需要更新整个LLM,计算资源消耗巨大
- 灾难性遗忘:在学习新任务时容易忘记之前学到的知识
AgentFly通过独特的架构设计,实现了代理行为的灵活调整和知识的持续积累,为AI代理的长期应用提供了全新范式。
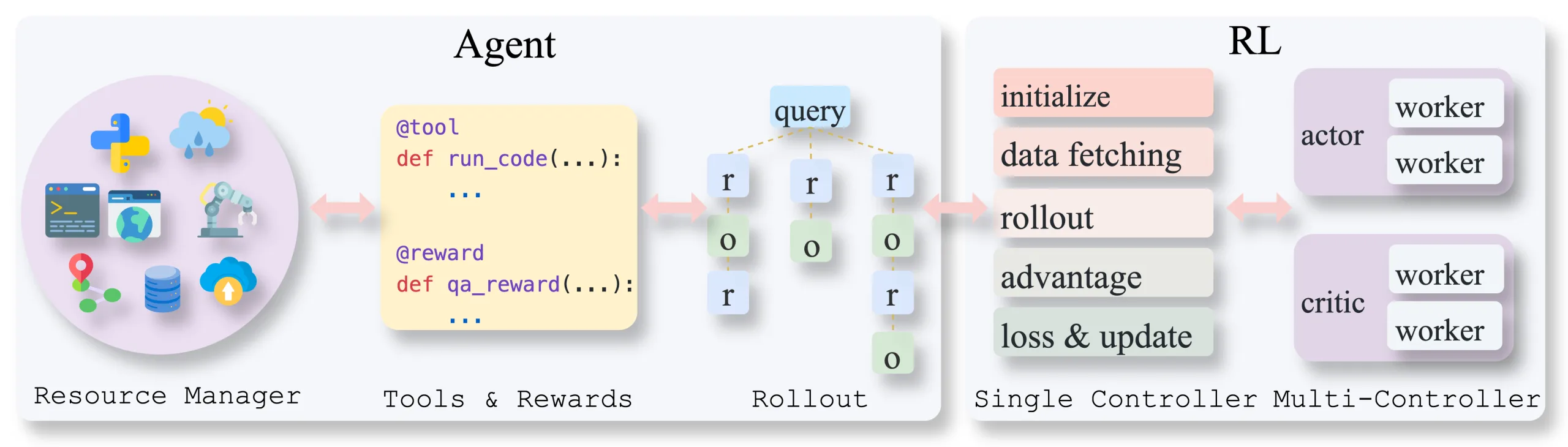
architecture系统架构
AgentFly采用模块化设计,主要由以下三个核心组件构成:
memory记忆模块
负责存储和管理代理的经验和知识,包括:
- 短期记忆:当前任务上下文
- 长期记忆:历史经验和知识
- 向量数据库:高效检索相关信息
build工具模块
提供多样化的工具调用能力,包括:
- API调用:与外部系统交互
- 代码执行:运行自定义逻辑
- 搜索功能:获取最新信息
route规划模块
负责任务分解和执行策略制定:
- 任务分解:将复杂任务拆分为子任务
- 策略选择:选择最优执行路径
- 动态调整:根据反馈实时调整计划
sync_alt适配层
连接LLM与代理行为的桥梁:
- 提示工程:优化输入提示
- 输出解析:结构化LLM输出
- 行为映射:将LLM输出转换为代理行为
school持续学习机制
AgentFly通过创新的设计解决了AI代理中的灾难性遗忘问题,实现了真正的持续学习能力:
def __init__(self):
self.memory_bank = MemoryBank() # 记忆库
self.knowledge_distiller = KnowledgeDistiller() # 知识蒸馏器
self.experience_replay = ExperienceReplay() # 经验回放
def learn(self, new_task):
# 1. 提取新任务知识
new_knowledge = self._extract_knowledge(new_task)
# 2. 知识蒸馏,保留核心知识
distilled_knowledge = self.knowledge_distiller.distill(
self.memory_bank.get_all_knowledge(), new_knowledge)
# 3. 经验回放,防止遗忘
self.experience_replay.replay(distilled_knowledge)
# 4. 更新记忆库
self.memory_bank.update(distilled_knowledge)
AgentFly的持续学习机制主要包括:
- 知识蒸馏:将新旧知识进行融合,提取核心概念
- 经验回放:定期回顾历史经验,强化记忆
- 弹性记忆:根据重要性动态调整记忆保留策略
- 多任务学习:同时处理多个相关任务,促进知识迁移
tune微调技术
AgentFly的核心创新在于其独特的微调技术,无需更新底层LLM即可实现代理行为的精确调整:
def __init__(self, base_llm):
self.base_llm = base_llm # 基础LLM,保持不变
self.adapter_layers = AdapterLayers() # 轻量级适配层
self.prompt_templates = PromptTemplates() # 提示模板库
def fine_tune(self, task_data):
# 1. 优化提示模板
optimized_prompts = self.prompt_templates.optimize(task_data)
# 2. 微调适配层(轻量级参数)
self.adapter_layers.train(task_data, optimized_prompts)
# 3. 行为映射优化
self._optimize_behavior_mapping(task_data)
def inference(self, input_text):
# 1. 应用优化的提示模板
prompt = self.prompt_templates.apply(input_text)
# 2. 通过适配层处理
adapted_prompt = self.adapter_layers.process(prompt)
# 3. 基础LLM推理(不变)
output = self.base_llm.generate(adapted_prompt)
# 4. 行为映射
return self._map_to_behavior(output)
AgentFly的微调技术主要包括:
- 提示工程优化:通过优化输入提示引导LLM产生期望输出
- 轻量级适配层:在LLM外部添加可训练的适配层,不修改原模型
- 行为映射机制:将LLM输出精确映射到代理行为
- 元学习策略:学习如何学习,快速适应新任务
explore应用场景与未来方向
AgentFly的灵活性和持续学习能力使其适用于多种场景:
business_center企业应用
- 智能客服:持续学习产品知识
- 业务流程自动化:适应流程变化
- 知识管理:积累企业专有知识
school教育领域
- 个性化学习助手:适应学生需求
- 智能辅导:持续改进教学方法
- 知识更新:跟进最新教学内容
biotech科研应用
- 文献分析:跟踪最新研究进展
- 实验设计:基于历史经验优化
- 跨学科研究:整合多领域知识
trending_up未来方向
- 多模态学习:整合视觉、听觉等信息
- 群体智能:多Agent协作学习
- 自主进化:自我优化和改进能力