MarkItDown 技术解析
微软开源的多格式文档转换工具
info 是什么?为什么重要?
想象一下,你有一堆各种格式的文档:Word 报告、PDF 手册、Excel 表格、PPT 演示,还有图片和音频文件等。现在你想让 AI 帮你分析这些内容,但 AI 就像一个只会说英语的外国人,而你的文档都是用」方言」写的。MarkItDown 就是那个翻译官,它能把所有这些」方言」统一翻译成 AI 最爱的」普通话」——Markdown 格式。
为什么选择 Markdown?
Markdown 对 AI 来说就是」统一语言」:
- 简洁明了:没有复杂的格式,AI 读起来不费劲
- 结构清晰:标题、列表、表格一目了然
- 省 Token:在 AI 时代,这意味着省钱省时间
- 天然支持:像 GPT-4 这样的 AI 天生就」会说」 Markdown
settings 技术实现:它是怎么做到的?
1. 聪明的」识别系统」
MarkItDown 首先要搞清楚」这是什么文件」,它用的是 Google 开发的 Magika 技术,就像一个经验丰富的图书管理员,不仅看文件名,还要」翻开看看内容」,准确判断文件类型。
2. 专业的」翻译团队」
对于每种文件格式,MarkItDown 都有专门的」翻译专家」:
- Word文档专家 (mammoth 库):专门理解 Word 的内部结构,重点保留文档的语义,而不是花哨的格式
- Excel 表格专家 (pandas 库):能处理多个工作表,把复杂的表格数据整理成清晰的 Markdown 表格
- PDF 专家 (pdfminer 库):像人一样」读」 PDF,理解文字的排列顺序,特别针对中文的多栏排版做了优化
- 图片专家 (Tesseract OCR):用 AI 识别图片中的文字,支持100多种语言,还能提取照片的拍摄信息
- 音频专家 (SpeechRecognition):把语音转成文字,支持多种音频格式
3. 模块化的设计哲学
整个系统就像乐高积木,每个转换器都是一个独立的积木块:
- 想支持新格式?只需要添加一个新积木
- 某个格式出问题?只需要修复对应的积木
- 用户只需要某些功能?可以只安装需要的积木
4. AI 时代的增强功能
- Azure 智能文档服务:对于特别复杂的文档,可以调用微软的 AI 服务,相当于请来了」专业顾问」
- GPT 视觉能力:可以让 GPT-4o 来」看图说话」,为图片生成详细的文字描述
code 使用简单到什么程度?
命令行一键转换
Python 几行代码
compare_arrows 优势与局限性
优势
- 统一多种格式为 Markdown
- 模块化设计,易于扩展
- 集成 AI 能力,智能处理
- 开源免费,社区活跃
- 简单易用的 API
局限性
- PDF 解析效果一般,特别是复杂格式
- 图片转换为占位符,非实际内容
- 音频转录对中文支持不佳
- 格式保真度有限
- 依赖多种外部库,安装复杂
MarkItDown 技术实现
深入解析 PDF 解析与多格式文档转换
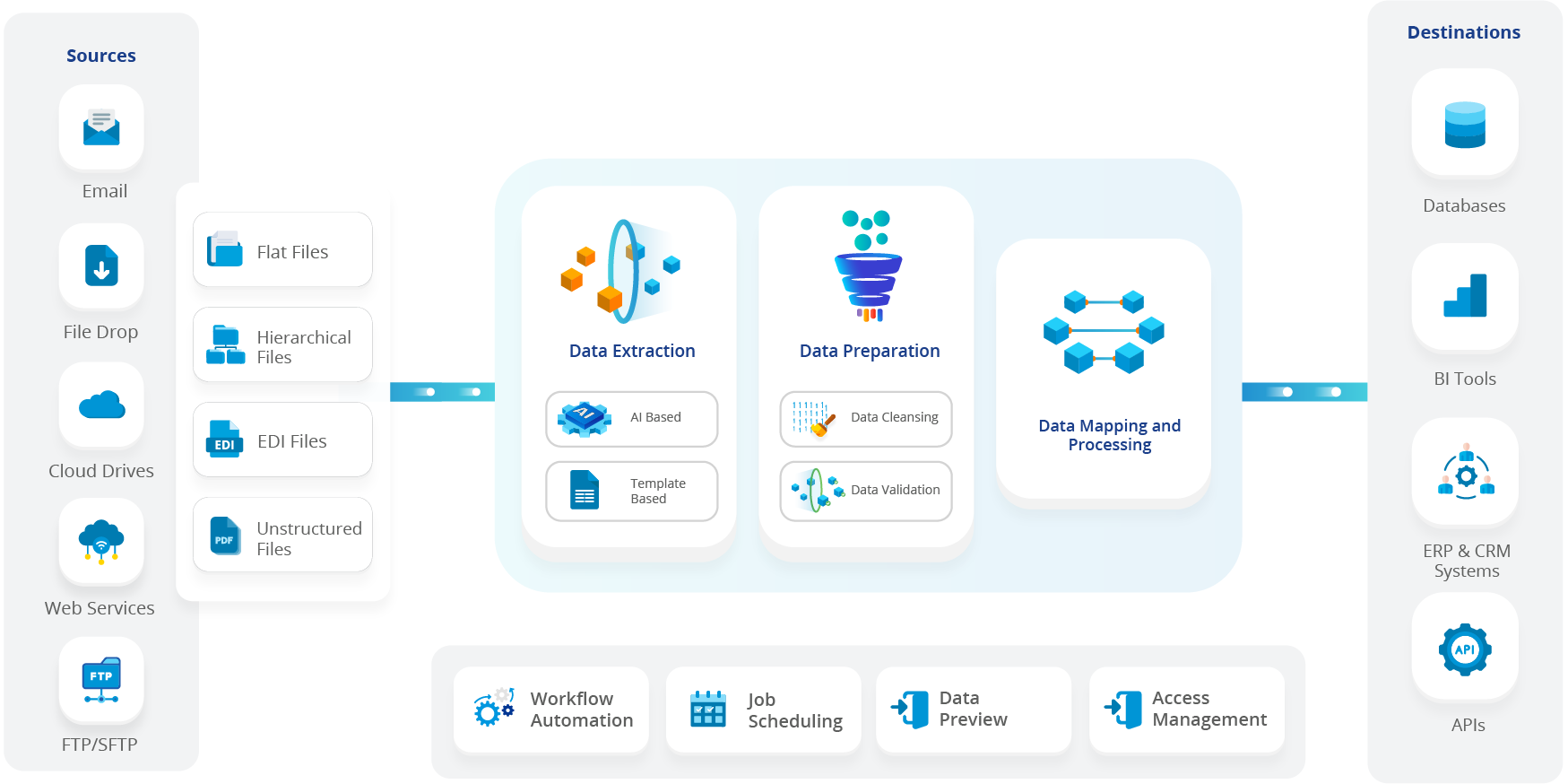
architecture 技术架构概览
MarkItDown 采用模块化设计,每个文件格式都有专门的转换器。这种设计使得系统具有良好的可扩展性和维护性。
hub核心引擎
基于 Python 开发,使用插件化架构,支持动态加载不同格式的转换器。通过 Magika 技术进行文件类型识别,确保准确判断输入文件类型。
settings_suggest转换器管理
每个转换器都是独立的模块,负责特定文件格式的解析和转换。系统根据文件类型自动选择合适的转换器,支持可选依赖安装。
integration_instructionsAI 集成
支持与大型语言模型(如 GPT-4o)集成,用于图像描述和复杂文档处理。通过 Azure Document Intelligence 提供增强的文档理解能力。
api接口设计
提供简洁的命令行工具和 Python API,支持批量处理和管道操作。通过 MCP(模型上下文协议)服务器与 LLM 应用程序集成。
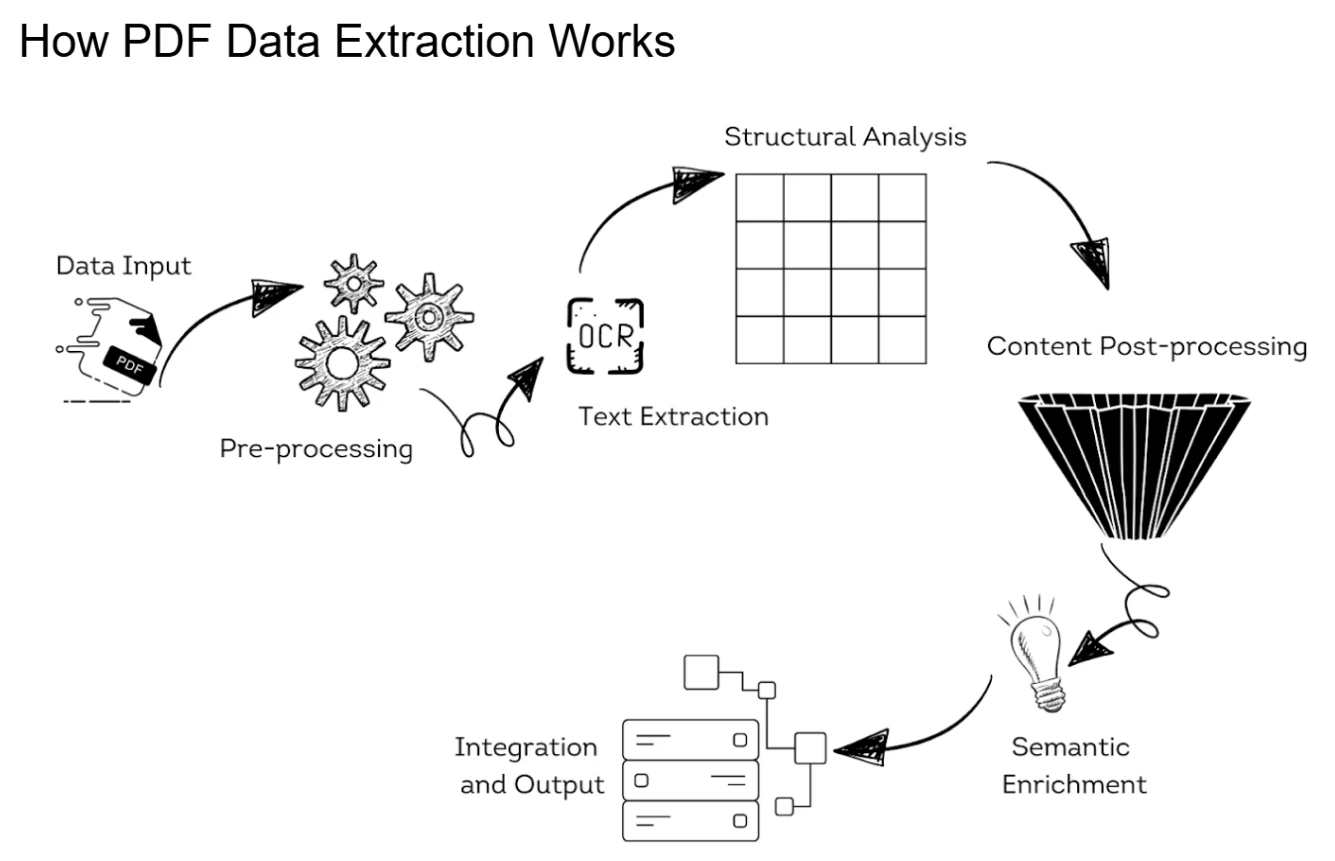
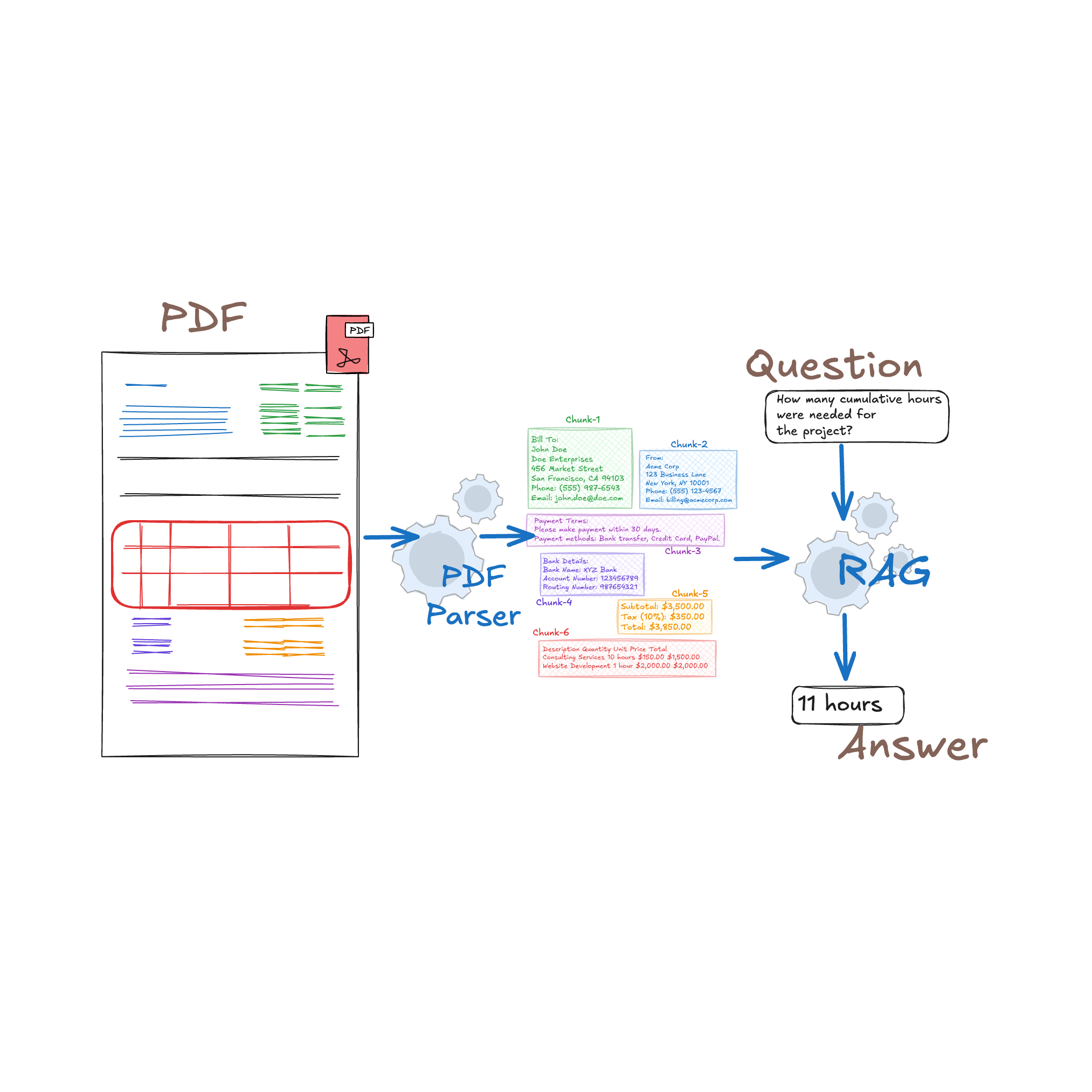
picture_as_pdf PDF 解析实现
MarkItDown 使用 pdfminer.six 库作为 PDF 解析的核心引擎。pdfminer.six 是一个纯 Python 实现的 PDF 解析工具,能够从 PDF 文档中提取文本和元数据。
PDF 解析工作流程
- 文件分析:识别 PDF 文件结构,包括页面、对象和流
- 内容提取:从 PDF 对象中提取文本内容和位置信息
- 布局分析:根据文本位置信息重建文档的逻辑结构
- 格式转换:将提取的内容转换为 Markdown 格式
PDF 解析的局限性
尽管 pdfminer.six 是一个强大的工具,但 MarkItDown 在 PDF 解析方面仍存在一些局限性:
- 难以保留复杂的格式和布局结构
- 对多栏文档的处理效果不佳
- 无法直接提取图片内容,只能以占位符形式表示
- 对表格结构的识别和转换有限
compare PDF 解析技术对比
MarkItDown (pdfminer.six)
- 纯 Python 实现,易于集成
- 支持基本文本提取和布局分析
- 对中文等多语言有一定支持
- 转换速度快,资源占用低
- 开源免费,社区支持良好
其他 PDF 解析方案
- PyMuPDF:解析精度高,速度快,但商业使用需付费
- pdfplumber:表格提取能力强,适合结构化数据
- Unstructured:AI 驱动,支持复杂布局,但资源消耗大
- Nougat:深度学习模型,学术文档解析效果好
code 代码示例:PDF 转换
以下是使用 MarkItDown 将 PDF 文件转换为 Markdown 的代码示例:
通过 Azure Document Intelligence,MarkItDown 可以获得更强的 PDF 解析能力,特别是对于复杂布局和表格结构的处理。
MarkItDown 使用方法
轻松将多种格式文档转换为 Markdown
download 安装与配置
MarkItDown 提供了多种安装方式,可以根据需要选择适合的安装方法。
使用 pip 安装(推荐)
安装所有可选依赖(支持所有文件格式):
从源代码安装
选择性安装依赖
如果只需要支持特定格式,可以单独安装相应依赖:
code 基本使用方法
terminal命令行使用
通过命令行快速转换文件:
integration_instructionsPython API 使用
在 Python 代码中使用 MarkItDown:
smart_toy 高级功能
MarkItDown 提供了多种高级功能,包括 AI 集成、批量处理和插件扩展。
AI 图像描述
使用大型语言模型为图像生成描述:
文档智能处理
使用 Azure Document Intelligence 增强
批量处理
处理目录中的多个文件:
插件系统
使用第三方插件扩展功能:
tips_and_updates 使用技巧与最佳实践
选择性安装依赖
根据实际需求选择安装依赖,减少不必要的资源占用。例如,如果只需要处理 Office 文档,可以只安装相关依赖。
处理大文件
对于大型文档,考虑分批处理或使用流式处理,避免内存不足问题。
多语言支持
MarkItDown 支持多种语言,但对于非英语文档,可能需要额外配置语言模型以获得更好的 OCR 效果。
后处理优化
转换后的 Markdown 可能需要进一步优化,例如调整格式、修复表格结构或添加元数据。
MarkItDown 优势与局限性
全面分析微软开源文档转换工具的优缺点
balance 优势与局限性对比
thumb_up优势
- 多格式支持:支持 PDF、Office 文档、图片、音频等多种格式统一转换为 Markdown
- 简单易用:提供直观的命令行工具和 Python API,几行代码即可实现转换
- 开源免费:MIT 许可证,可自由使用、修改和分发
- 模块化设计:可根据需要选择性安装依赖,减少资源占用
- AI 集成:支持与大型语言模型集成,实现智能图像描述和文档处理
- 社区活跃:微软背书,社区支持良好,持续更新迭代
thumb_down局限性
- PDF 解析效果一般:难以保留复杂格式和布局结构,特别是多栏文档
- 图片处理有限:只能以占位符形式表示图片,无法直接提取图片内容
- 表格识别不足:对复杂表格结构的识别和转换效果有限
- 多语言支持不均衡:音频转录对中文支持不佳,OCR 效果因语言而异
- 依赖复杂:需要安装多种外部库,可能存在兼容性问题
- 格式保真度有限:转换后的 Markdown 可能无法完全保留原始文档的格式和样式
picture_as_pdf PDF 解析的局限性分析
PDF 解析是 MarkItDown 中最具挑战性的部分,也是用户反馈最多的问题领域。以下是详细的局限性分析:
format_align_left布局与结构问题
- 多栏文档处理效果差,内容顺序混乱
- 无法准确识别标题层级和段落结构
- 复杂排版(如环绕图片的文字)解析困难
- 页眉页脚与正文内容混合,难以区分
format_shapes格式与样式丢失
- 粗体、斜体等文本格式无法保留
- 颜色、字体大小等样式信息丢失
- 超链接转换为纯文本,失去可点击性
- 特殊符号和公式可能无法正确解析
image图像与表格问题
- 图片内容无法提取,仅显示为占位符
- 复杂表格结构识别不准确,格式混乱
- 图文混排文档中图片位置信息丢失
- 图表、流程图等可视化内容无法转换
settings技术限制
- pdfminer.six 库对复杂 PDF 支持有限
- 扫描版 PDF 依赖 OCR,效果不稳定
- 加密或受权限保护的 PDF 无法处理
- 大型 PDF 文件处理速度慢,内存占用高
compare 与其他 PDF 解析工具对比
虽然 MarkItDown 在 PDF 解析方面存在局限性,但与其他工具相比,它仍有其独特优势。以下是与其他主流 PDF 解析工具的对比:
starMarkItDown 的优势
- 一站式解决方案,无需组合多个工具
- 专为 Markdown 输出优化,适合 AI 处理
- 简单易用的 API,降低使用门槛
- 微软支持,持续更新和改进
- 免费开源,无商业使用限制
upgrade替代方案的优势
- PyMuPDF:解析精度高,速度快,但商业使用需付费
- pdfplumber:表格提取能力强,适合结构化数据
- Unstructured:AI 驱动,支持复杂布局,但资源消耗大
- Nougat:深度学习模型,学术文档解析效果好
lightbulb 改进建议与最佳实践
针对 MarkItDown 的局限性,以下是一些改进建议和使用最佳实践:
build技术改进方向
- 集成更强大的 PDF 解析库,如 PyMuPDF
- 增强表格和图像识别能力
- 改进多语言支持,特别是中文处理
- 优化内存使用,支持大型文档处理
- 提供更多格式保留选项,满足不同需求
tips_and_updates使用最佳实践
- 对于复杂 PDF,考虑使用 Azure Document Intelligence
- 转换后进行手动编辑,修复格式问题
- 将大型 PDF 分拆为小文件处理
- 结合其他工具弥补 MarkItDown 的不足
- 参与社区贡献,帮助改进工具