想象一下:你的手机在深夜悄悄醒来,和全球数百万台设备一起开了一个不被任何人监听的「自习室」。它们互相交换照片的「不同角度自拍」,却绝不泄露原图;它们像一群害羞的少年,既想靠近彼此,又死死守着自己的小秘密。这不是科幻电影,而是Christos Louizos等人在2024年ICLR论文里真正实现的故事——《A Mutual Information Perspective on Federated Contrastive Learning》。今天,我们就来一起偷看这场「隐私派对」里到底发生了什么。
🔒 边缘世界的隐私焦虑:为什么我们不能再把数据打包寄给云端大佬了?
还记得十年前吗?那时候我们天真地把所有照片、短信、心率记录一股脑儿上传到云端,换来一个「更聪明」的推荐算法。现在呢?每上传一张自拍,都像在大街上脱衣服——欧洲的GDPR、中国的《个人信息保护法》、加州的CCPA像三把达摩克里斯之剑悬在头顶。
更要命的是,2025年的我们已经生活在「万物皆设备」的世界里:手表在记录心跳,眼镜在拍街景,冰箱在偷看你又买了第六包薯片。这些数据天生就该留在本地,可我们又真的很想要「全局聪明」的AI。这就像想吃蛋糕又想保持身材——经典的人类困境。
🧠 SimCLR:那个让AI自己给自己贴标签的天才发明
在进入联邦学习之前,我们得先认识一个2020年的大明星——SimCLR(A Simple Framework for Contrastive Learning of Visual Representations)。它的核心理念简单得让人拍大腿:
- 拿一张猫图,随便搞两种乱七八糟的增强(随机裁剪+颜色扭曲)
- 让神经网络把这对「双胞胎」拉近,同时把其他199张负样本推远
- 重复几万次后,网络就学会了「猫性」的本质,而不是像素表面的花里胡哨
关键公式(InfoNCE损失)长这样:
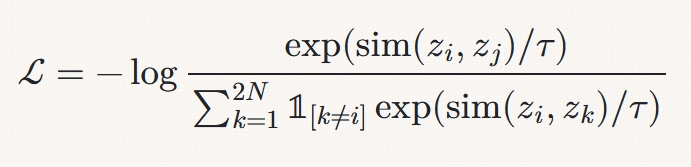
翻译成大白话:我就是要让正样本对的相似度碾压所有负样本!
注解小剧场:这里的$\tau$是温度系数,像麻辣烫的辣度调节器。调小了,模型更挑剔;调大了,就变得「海纳百川」。太多论文直接写0.07、0.5,却不告诉你这其实是「玄学超参数」。
😷 当SimCLR遇上联邦学习:non-i.i.d这个恶棍出现了
好了,现在把SimCLR搬到联邦场景下会发生什么?
想象1000个用户,每个人只拍自己家那只猫(或者狗、仓鼠、乌龟……)。用户A的相册全是橘猫,用户B全是英短蓝猫,用户C甚至只有蜥蜴。数据分布完全non-i.i.d!这时候直接跑全局SimCLR会发生悲剧:
- 负样本里全是别人的猫,我的橘猫特征被稀释成「泛猫性」
- 全局模型学了一堆没用的「用户风格」而不是真正的语义特征
- 准确率哗啦啦往下掉,比本地单独训练还差!
这就像让北京人、上海人、广东人一起学做饭,最后做出来的全是「黑暗料理」——每个人都贡献了自己的调料,但没人吃得下。
💡 Louizos的灵光一闪:把「谁是这个人」也变成有用的信号!
Christos Louizos突然意识到:等等!在non-i.i.d最严重的情况下(比如标签完全按用户分割),用户ID本身就是超级强的监督信号啊!
如果你知道这张照片是「用户42」拍的,而用户42只拍橘猫,那「用户42」这个身份本身就几乎等于「橘猫」标签!
于是他们做了一件很叛逆的事:故意让模型去学习「这个人是谁」!
🎭 用户验证损失:给每个客户端发一个「身份面具」
他们设计了一个全新的损失项——User Verification Loss,本质是一个分类任务:给定一个特征向量$z$,预测它来自哪个客户端(用户ID)。
关键洞察在于:当标签偏斜(label skew)特别严重时,用户ID和标签之间的互信息$I(User; Label)$会变得特别大!这时候让模型去预测用户ID,实际上就是在间接预测标签,是一个超级强的代理任务!
🧮 互信息的数学魔术:他们到底证明了什么?
论文最硬核的部分来了。他们推导出了一个全新的全局互信息下界:
这个公式美得像艺术品!它告诉我们:
全局互信息 ≥ 局部SimCLR贡献 + 用户验证贡献 + 常数
换句话说:你越会辨认「这是谁的特征」,全局的视图一致性下界就越高!
深度注解:这个下界是紧的吗?不一定。但关键是它把一个原本完全不可优化的全局互信息,拆成了两个可以分别在客户端本地优化的项。这才是真正的黑魔法!
🏆 实验结果:当理论遇上现实的火花
🔥 标签偏斜(Label Skew)场景:联邦SimCLR大获全胜
在最极端设置下(每个客户端只含2个类),联邦SimCLR把准确率从~65%干到~87%,领先第二个方法足足21个点!这已经不是提升,是降维打击。

(原论文Figure 2:可以看到红色柱子(FedSimCLR w/ user verification)几乎屠榜)
😅 协变量偏移(Covariate Shift)场景:翻车现场
但有趣的是,当non-i.i.d来自风格差异而不是标签差异时(比如不同用户用不同滤镜拍同一类物体),用户验证损失反而有害!因为此时$I(User; Label) ≈ 0$,强行让模型学用户身份就是在教它学噪音。
这就像让模特学习辨认摄影师的拍摄习惯——当所有摄影师都拍同一位模特时有用,但当每个摄影师都拍不同模特时就彻底乱套了。
| non-i.i.d 类型 | 用户ID是否有用? | 联邦SimCLR表现 | 最佳策略 |
|---|---|---|---|
| 标签偏斜(Label Skew) | 超级有用! | 屠榜 | 必须加用户验证损失 |
| 协变量偏移(Covariate Shift) | 完全没用 | 变差 | 纯局部SimCLR最好 |
| 数量偏斜(Quantity Skew) | 部分有用 | 小幅提升 | 可加可不加 |
🌟 更深层的哲学思考:隐私与性能的永恒拉锯战
Louizos的工作其实在暗示一个残酷的现实:
数据分布越不均匀,隐私保护的代价就越小,甚至能变成优势!
这太反直觉了!我们一直觉得non-i.i.d是联邦学习的毒瘤,但在这篇论文里,它摇身一变成了「免费的监督信号」。这就像柠檬变柠檬水的神操作。
🚀 未来的路还有多长?
作者自己在结论里谦虚地列了几个方向,但我们这些吃瓜群众可以脑洞更大:
- 自适应用户验证:能不能让模型自己判断当前是label skew还是covariate shift,自动开关用户验证模块?
- 层次化互信息:能不能再加一层「I(Group; Label)」来处理有自然聚类的客户端(比如按地区)?
- 与差分隐私结合:用户验证会不会泄露身份信息?(答案是会的!)如何在最大化$I(z;s)$的同时最小化实际身份泄露?
- 跨模态扩展:文本、语音、传感器数据能不能也用类似的「用户指纹」思想?
🎭 写在最后的彩蛋
下次你的手机在后台默默训练模型时,想象一下:
它可能正在和全球的小伙伴们玩一个超级大的「找同类」游戏;
它可能偷偷记住了「你最爱拍美食滤镜」这个小癖好;
但它发誓,绝不会把你晚餐吃了什么告诉任何人。
这就是2025年的AI:比你更了解你,却比任何时候都更尊重你的隐私。
这才是真正的——温柔的读心术。
参考文献
- Louizos, C. , Reisser, M., & Korzhenkov, D. (2024). ✅A Mutual Information Perspective on Federated Contrastive Learning. In International Conference on Learning Representations (ICLR 2024).
- Chen, T. , Kornblith, S., Noroozi, M., & Hinton, G. (2020). ✅A Simple Framework for Contrastive Learning of Visual Representations. International Conference on Machine Learning (ICML).
- McMahan, H. B., Moore, E., Ramage, D., Hampson, S., & y Arcas, B. A. (2017). ✅Communication-Efficient Learning of Deep Networks from Decentralized Data. AISTATS.
- Kairouz, P. , et al. (2021). ✅Advances and Open Problems in Federated Learning. Foundations and Trends in Machine Learning.
- Yang, Q. , Liu, Y., Chen, T., & Tong, Y. (2019). ✅Federated Machine Learning: Concept and Applications. ACM Transactions on Intelligent Systems and Technology.