时间序列分析(Time Series Analysis)详解
1. 时间序列分析的定义和用途
数据会随时间变化,能够识别数据可能变化的方式对于对未来数据做出合理预测至关重要。数据整体上是否呈现稳定上升或下降趋势?是否存在定期出现的波动?也许数据中存在与季节或多年商业周期密切相关的可预测波动。
时间序列分析允许检查在特定时间间隔收集或记录的数据点,从而能够识别趋势、模式和季节性变化,这对于在各个行业中做出明智的预测和决策至关重要。它广泛应用于商业、金融、经济学、环境和天气科学、信息科学以及许多其他随时间收集数据的领域。
注意:时间序列分析的核心是通过分析历史数据中的模式和趋势,来预测未来的数据点,从而帮助决策者做出更明智的选择。
2. 时间序列分析的应用领域
时间序列分析用于解决现实世界问题的一些领域包括:
3. 时间序列分析的基本步骤
时间序列分析涉及许多统计和计算技术,以识别模式、做出预测或获得对数据的洞察。时间序列分析的基本步骤紧密遵循数据科学周期,如下所述:
4. 时间序列的定义和特点
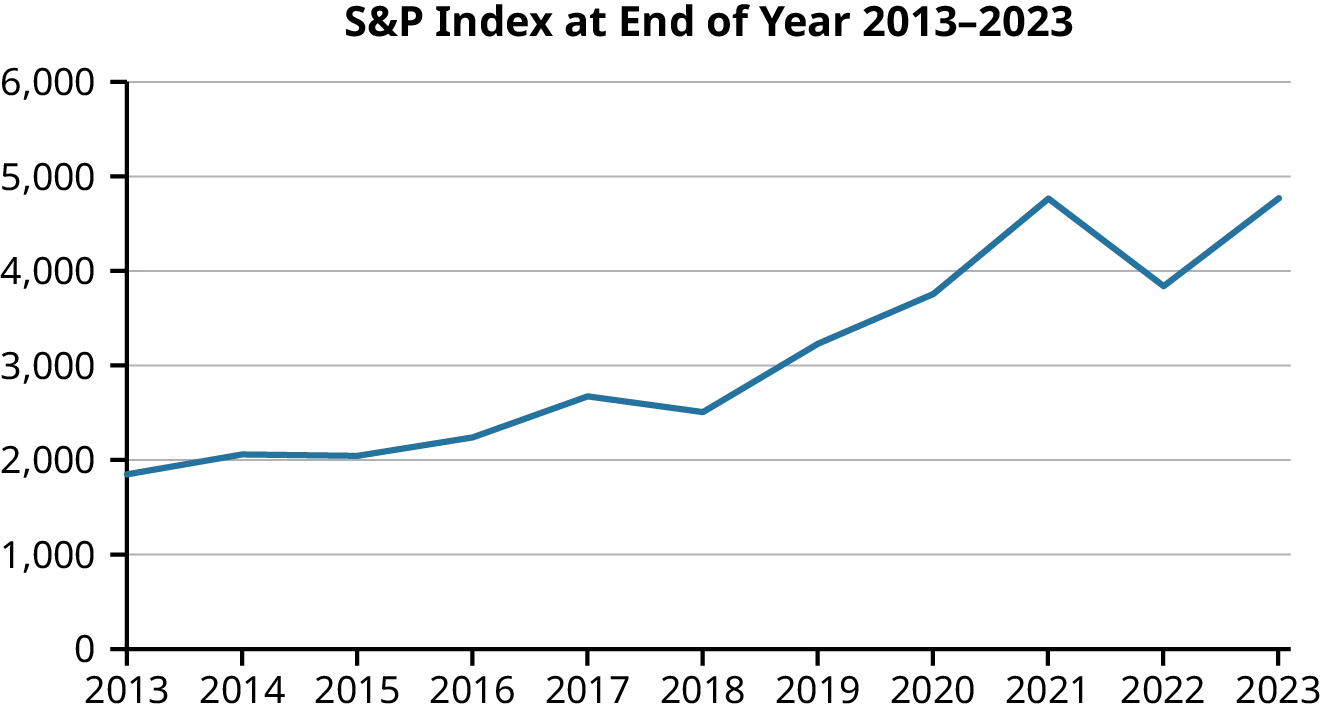
任何由同一变量的数值测量组成的数据集,如果按照规律的时间间隔收集和组织,都可以被视为时间序列数据。例如,下表显示了S&P 500(股市上500家顶级上市公司的综合指数)过去几年的数据。这里,变量是每年最后一个交易日的S&P指数值(时间点数据)。
| 年份 | 年末S&P指数 |
|---|---|
| 2013 | 1848.36 |
| 2014 | 2058.90 |
| 2015 | 2043.94 |
| 2016 | 2238.83 |
| 2017 | 2673.61 |
| 2018 | 2506.85 |
| 2019 | 3230.78 |
| 2020 | 3756.07 |
| 2021 | 4766.18 |
| 2022 | 3839.50 |
| 2023 | 4769.83 |
虽然表格信息丰富,但用它来寻找趋势或做出预测并不特别容易。可视化会更好。下图使用时间序列图(本质上是折线图)显示时间序列数据。注意,虽然总体趋势是上升的,但在2018年和2022年也有下降。
图5.2中显示的示例是一个简单的时间序列,仅跟踪了一个度量(S&P 500指数值)随时间的变化。只要我们记住这些数据代表从2013年开始的S&P 500指数的年度值,将值单独视为有序列表会更有效率。
在数学中,数字的有序列表称为序列。序列的各个值称为项。抽象序列可以表示为(xn)或(xn)1≤n≤N。在这两种表示法中,n表示序列每个值的索引,而后一种表示法还指定了序列的索引值范围(n取从1到N的所有索引值)。即:
我们将使用标准术语"时间序列"来指代时间标记的数据序列,并在讨论时间序列的项作为值的有序列表时使用术语"序列"。
然而,并非每个数据点序列都是时间序列。世界各国当前人口的集合不是时间序列,因为数据不是在不同时间测量的。但是,如果我们专注于一个国家并逐年跟踪其人口,那么这将是一个时间序列。按年份列出的最受欢迎的婴儿名字怎么样?虽然有时间成分,但数据不是数字化的,因此这不会属于时间序列的范畴。另一方面,关于每年有多少婴儿被命名为"Jennifer"的信息将构成时间序列数据。
通常,我们假设时间序列数据是在相等的时间间隔内采集的,并且没有缺失值。时间序列的项往往以某种方式依赖于先前的项;否则,可能无法对未来项做出任何预测。
5. 时间序列模型的概念
时间序列模型是用于查找、近似或预测给定时间序列值的函数、算法或方法。时间序列模型背后的基本思想是,先前的值应该提供关于未来值如何表现的一些指示。换句话说,存在某种函数,它将时间序列的先前值作为输入,并产生下一个值作为输出:
然而,在除了最理想情况之外的所有情况下,能够以完美准确度预测时间序列下一个值的函数并不存在。随机变异和模型中未考虑的其他因素将产生误差,误差被定义为预测与实际观察值之间的差异程度。因此,我们应该始终将误差项(通常用希腊字母ε表示,称为"epsilon")纳入模型。此外,我们不期望模型精确地产生下一项,而是生成预测值。通常,时间序列的预测值用(x̂n)表示,以区别于实际值(xn)。因此:
6. 时间序列预测的方法
通常,时间序列分析的目标是对时间序列的未来值进行预测或外推,这个过程称为预测。作为一般规则,随着预测进一步推向未来,预测的准确性会降低。当未来的预测不再比抛硬币或掷骰子更准确时,在该点或更远处的预测就变得无效。在实践中,时间序列模型会定期更新以适应新数据。
根据情况和数据的性质,有许多不同的方法来预测未来数据。所有方法中最简单的,称为朴素或平坦预测方法,是使用最近的值作为下一个值的最佳猜测。例如,由于S&P 500在2022年底的价值为3,839.5,可以合理地假设在2023年底的价值将相对接近3,839.5。注意,这将对应于时间序列模型x̂n+1 = xn。朴素方法在实践中只有有限的用途。
不是仅使用最后一个观察值来预测下一个值,更好的方法可能是考虑多个值xn, xn-1, xn-2, ...,来找到估计值x̂n+1。人们可以将最后的T个值平均在一起(对于某些预定义的T值)。这被称为简单移动平均,将在时间序列分析的组成部分中明确定义。现在,让我们直观地说明这个想法。假设我们使用最近的T=3个项的平均值来估计下一项。时间序列模型将是:
基于表5.1中的数据,2023年底S&P指数值的预测将计算如下:
预测的另一种简单方法是将数据拟合到线性回归模型,然后使用回归模型预测未来值。与仅使用最后一个数据点相比,线性回归在捕捉数据的总体方向方面做得更好。另一方面,线性回归将无法模拟数据中更细微的结构,如周期性模式。此外,还有一个隐藏的假设,即数据在我们希望预测的整个时期内或多或少地均匀上升或下降,这通常不是一个有效的假设。
7. 示例分析:使用线性回归模型预测S&P指数
问题
为表5.1中的数据找到一个线性回归模型,并使用它预测2024年底和2025年底的S&P值。
解决方案
为了解决这个问题,我们可以使用Python中的线性回归模型来拟合数据并进行预测。
在这个例子中,我们使用了线性回归模型来拟合S&P指数的历史数据,并预测了2024年和2025年的值。线性回归模型可以帮助我们捕捉数据的总体趋势,但它可能无法捕捉数据中的周期性波动或其他复杂模式。
注意:在本章中,我们将开发更复杂的工具,可以检测平均值或线性模型无法找到的模式,包括自回归模型、移动平均和自回归综合移动平均(ARIMA)模型。然而,为时间序列数据创建花哨的模型只是过程的一部分。过程的一个重要部分是测试和评估你的模型。因此,我们还将探索误差和不确定性的度量,这些可以确定模型有多好以及其预测可能有多准确。