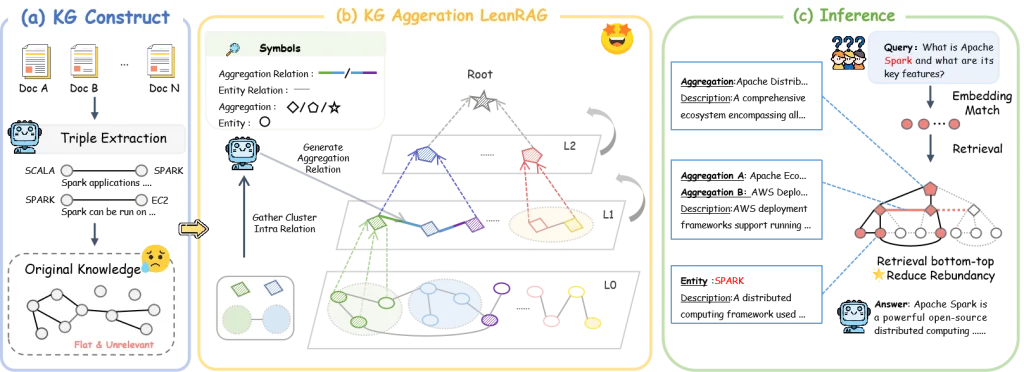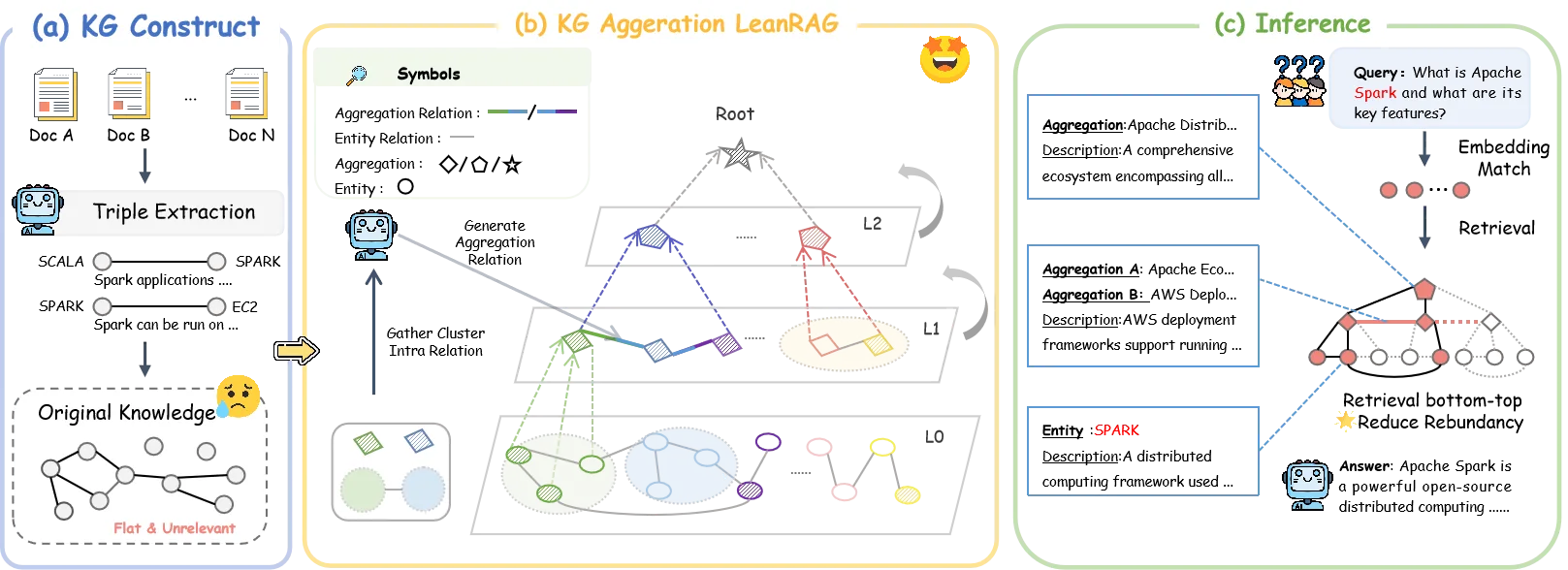
LeanRAG: 基于语义聚合与分层检索的知识图谱生成框架
背景与动机
检索增强生成(RAG)通过利用外部知识来增强大型语言模型,但其有效性常常因检索到上下文有缺陷或不完整的信息而受到影响。为解决这一问题,基于知识图谱的RAG方法已向分层结构发展,将知识组织成多层次摘要。然而,这些方法仍然存在两个关键的未解决挑战:
- 语义孤岛问题:高级概念摘要作为断开的”语义孤岛”存在,缺乏跨社区推理所需的显式关系。
- 结构感知缺失:检索过程本身仍然缺乏结构感知,常常退化为低效的平面搜索,无法利用图谱丰富的拓扑结构。
这些局限性导致现有方法在处理复杂查询时效率低下且检索质量不佳,无法充分利用知识图谱的结构优势。因此,LeanRAG框架应运而生,旨在通过深度协作的知识聚合和检索策略来解决这些问题。
核心创新
LeanRAG框架的核心创新在于其深度协作的设计,结合了知识聚合和检索策略,有效解决了传统RAG和知识图谱RAG中的关键问题。
1. 语义聚合算法
LeanRAG首先采用一种新颖的语义聚合算法,该算法形成实体簇并构建聚合级别摘要之间的新显式关系,创建一个完全可导航的语义网络。这一过程包括:
- 递归语义聚类:利用高斯混合模型(GMM)对实体进行语义聚类,形成语义相关的实体组。
- 聚合实体生成:为每个聚类生成一个更抽象的聚合实体,代表该聚类的集体语义。
- 聚合关系生成:在聚合实体之间创建新的关系,防止在更高层次形成”语义孤岛”。
def semantic_aggregation(graph_layer):
# 步骤1: 语义嵌入
embeddings = {entity: encode(entity.description) for entity in graph_layer.entities}
# 步骤2: 高斯混合聚类
clusters = gmm_clustering(embeddings, num_clusters=m)
# 步骤3: 生成聚合实体
aggregated_entities = []
for cluster in clusters:
relations = get_intra_cluster_relations(cluster)
agg_entity = generate_aggregated_entity(cluster, relations)
aggregated_entities.append(agg_entity)
# 步骤4: 生成聚合关系
aggregated_relations = []
for i, entity_a in enumerate(aggregated_entities):
for j, entity_b in enumerate(aggregated_entities):
if i < j: # 避免重复
inter_cluster_relations = get_inter_cluster_relations(
clusters[i], clusters[j])
if len(inter_cluster_relations) > threshold:
agg_relation = generate_aggregated_relation(
entity_a, entity_b, inter_cluster_relations)
aggregated_relations.append(agg_relation)
return KnowledgeGraph(aggregated_entities, aggregated_relations)
2. 自底向上、结构引导的检索策略
LeanRAG采用自底向上、结构引导的检索策略,将查询锚定到最相关的细粒度实体,然后系统地遍历图谱的语义路径,收集简洁但上下文全面的证据集。这一策略包括:
- 初始实体锚定:在基础层执行密集检索搜索,识别与查询最语义相似的实体。
- LCA路径遍历:利用最低公共祖先(LCA)原则构建连接种子实体的最小子图。
- 上下文收集:收集LCA路径上的所有实体和关系,形成紧凑且连贯的上下文。
def structured_retrieval(query, hierarchical_graph):
# 步骤1: 初始实体锚定
base_layer = hierarchical_graph.get_base_layer()
seed_entities = top_n_entities(base_layer, query, n=10)
# 步骤2: 找到最低公共祖先
lca = find_lowest_common_ancestor(seed_entities, hierarchical_graph)
# 步骤3: 构建LCA路径
retrieval_paths = []
for entity in seed_entities:
path = shortest_path(hierarchical_graph, entity, lca)
retrieval_paths.append(path)
# 步骤4: 收集检索子图
retrieved_entities = set()
retrieved_relations = set()
for path in retrieval_paths:
for node in path.nodes:
retrieved_entities.add(node)
for edge in path.edges:
retrieved_relations.add(edge)
# 添加聚合层间关系
for layer in hierarchical_graph.layers:
for relation in layer.inter_cluster_relations:
if relation.source in retrieved_entities and relation.target in retrieved_entities:
retrieved_relations.add(relation)
# 步骤5: 返回原始文本块
original_chunks = get_original_chunks(retrieved_entities)
return RetrievalResult(retrieved_entities, retrieved_relations, original_chunks)
架构设计
LeanRAG的架构设计紧密协同了知识聚合和检索机制,包括两个核心组件:分层知识图谱聚合和基于最低公共祖先(LCA)的结构化检索。
LeanRAG将平面知识图谱G0转换为多层、语义丰富的层次结构H. ��这种层次结构允许在不同抽象级别进行检索。我们以自底向上、逐层的方式构建这个层次结构,记为H = {G0, G1, …, Gk}。每一层Gi = (Vi, Ri, D(ver)i, D(rel)i)表示对下面一层Gi-1的更抽象视图。✅
构建过程的核心是一个递归聚合过程,该过程基于语义相似性对节点进行聚类,然后智能地生成新的、更抽象的实体和关系来形成下一层。
分层知识图谱H使得检索策略从根本上比在平面图上搜索更加结构化和高效。我们的方法超越了简单的基于相似性的检索,利用图的拓扑结构来构建一个紧凑且上下文连贯的子图。这个过程包括两个主要阶段:在基础层的初始实体锚定,随后是对层次结构的结构化遍历以收集上下文。
给定用户查询q,第一步是将查询锚定在最具体、最细粒度的事实上。我们通过对原始图的实体(包括初始实体)执行密集检索搜索来实现这一点。然后,我们利用整个层次结构H来定义一个更加聚焦和有意义的上下文。我们的核心思想是构建一个最小子图,通过它们在层次结构中最直接的共享概念来连接种子实体。
实验结果
为了验证LeanRAG的有效性,研究团队在四个不同领域的QA基准测试上进行了广泛的实验,包括Mix、CS、Legal和Agriculture数据集。实验结果表明,LeanRAG在响应质量方面显著优于现有方法,同时减少了46%的检索冗余。
| 数据集 | 评估指标 | LeanRAG | HiRAG (SOTA) | 提升 |
|---|---|---|---|---|
| Mix | 全面性 | 8.89±0.01 | 8.72±0.02 | +0.17 |
| 赋能性 | 8.16±0.02 | 7.86±0.03 | +0.30 | |
| 多样性 | 7.73±0.01 | 7.21±0.02 | +0.52 | |
| 总体 | 8.59±0.01 | 8.08±0.02 | +0.51 | |
| CS | 全面性 | 8.92±0.01 | 8.92±0.01 | 持平 |
| 赋能性 | 8.68±0.02 | 8.66±0.02 | +0.02 | |
| 多样性 | 7.87±0.02 | 7.84±0.02 | +0.03 | |
| 总体 | 8.82±0.02 | 8.77±0.02 | +0.05 |
此外,研究还进行了消融实验,验证了LeanRAG各个组件的有效性:
- 聚合关系有效性分析:当移除关系路径时,LeanRAG的检索多样性显著降低,确认了建立簇间关系可以有效连接孤立实体,从而丰富可用于检索的信息。
- 文本上下文必要性分析:当移除原始文本上下文时,LeanRAG的性能显著下降,确认了分层图谱作为高效语义索引和导航系统的主要功能是精确定位非结构化文本的最关键部分。
结论
LeanRAG通过紧密协同设计其知识聚合和检索机制,解决了基于知识图谱的RAG系统中普遍存在的”语义孤岛”和结构-检索不匹配的关键挑战。该方法的特点包括:
- 一种新颖的语义聚合算法,通过在抽象摘要概念之间生成显式关系,构建一个完全可导航的语义网络。
- 一个互补的自底向上、基于LCA的检索策略,高效地遍历这一结构。
- 在减少信息冗余的同时,实现了最先进的性能。
广泛的实验验证了LeanRAG的设计,证明其在多个具有挑战性的QA任务上实现了最先进的性能,同时显著减少了信息冗余。此外,消融研究确认了摘要信息的生成和原始文本上下文对于产生全面和多样化的答案都是必不可少的。