现象概述
Attention sink是大型语言模型中一种普遍现象,指模型将大量注意力(在Llama 405B中高达80%)集中在序列第一个token(通常是<bos>标记)上,尽管该token通常缺乏明显的语义意义。这种看似」浪费」注意力的模式是训练过程中自然形成的,而非人为设计的结果。
理论解释:避免过度混合
作者提出了一个新颖且有说服力的解释:attention sink是Transformer模型避免」过度混合」(over-mixing)的一种自适应机制。
深层Transformer和长上下文处理面临一个固有挑战:随着层数增加和上下文延长,token表示会趋于相似,导致:
- 秩崩溃(rank collapse):重复应用注意力层会将值投影到秩为1的向量空间
- 表示崩溃(representational collapse):在长序列中,Transformer倾向于破坏序列末尾token的信息
- 过度压缩(over-squashing):因果掩码使Transformer对序列前部的token更敏感
作者通过数学证明了秩崩溃是表示崩溃的更强条件,并扩展了over-squashing分析到多头注意力:
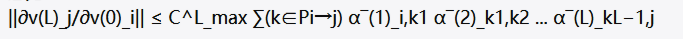
这个公式表明,token间的敏感性受到注意力权重分布的影响。当大量注意力集中在第一个token上时,其他token之间的直接注意力交互减少,从而减缓了信息混合的速度。
实验证据
这一理论得到了多项实验证据的支持:
- Gemma 7B扰动分析:有时扰动影响局部化,无时扰动广泛传播,证明sink能控制扰动传播
- 注意力模式分析:移除导致注意力分布更加平滑,增加了||Jij||值,证明减弱了混合
- 「撇号头」机制解析:的值向量范数最小(~5),撇号的值向量范数最大(~20),揭示了」近似无操作」机制
- 上下文长度实验:上下文长度128几乎没有sink形成(~5%),而上下文长度2048形成显著sink(~40%),验证了更长上下文需要更强的sink
- 模型规模影响:LLaMa 3.1 8B模型sink率为45.97%,70B为73.49%,405B达78.29%,证明更大模型需要更强的sink
- 标记特殊性研究:当在预训练中固定为第一个token时,移除它会消除sink并降低性能;当预训练中没有时,sink仍然形成在第一个token位置
- 「近似无操作」机制: 论文还发现了一个有趣的现象:attention sink可以作为」近似无操作」(approximate no-op)机制。通过分析Gemma 7B中的特定注意力头,研究者发现: – 当满足特定条件时,头会锐利地关注相关token – 否则,它会关注<bos>,其对应的值向量范数最小 这表明注意力头可以通过关注低范数的<bos>值来」关闭」自己,只在特定条件下」激活」,实现类似」if-else」的条件计算。
实际应用影响
技术层面影响
- 模型效率与性能优化:
- KV缓存策略需要保留sink token
- 计算资源可针对sink token优化分配
- 注意力计算可设计专门的算法优化
- 长上下文处理能力:
- Sink是控制过度混合的关键机制,为扩展上下文窗口提供理论基础
- 滑动窗口设计必须确保sink token保留在窗口中
- Sink通过减缓信息混合提高了长序列处理的稳定性
- 模型量化与部署:
- Attention sink导致的极不均匀权重分布对量化构成挑战
- 可为sink相关和非sink相关的权重采用不同的量化精度
- 理解sink机制有助于开发更高效的模型剪枝和压缩技术
- 安全与鲁棒性:
- Sink token可能成为攻击者的目标
- Sink机制提高了模型对输入扰动的鲁棒性
- 理解sink机制有助于设计针对性的防御策略
模型设计改进方向
- 架构层面:
- 设计显式混合控制机制,允许模型直接学习最优的信息混合速率
- 开发自适应深度架构,为每个token动态决定需要经过的层数
- 实现分层注意力设计,将头明确分为」混合控制头」和」信息处理头」
- 训练策略:
- 实施渐进式上下文扩展,训练初期使用较短上下文,逐步增加到目标长度
- 优化数据打包策略,确保训练数据中第一个位置的一致性
- 设计特定的注意力正则化项,鼓励适当的sink形成
- 推理优化:
- 开发智能KV缓存策略,为sink token和非sink token使用不同的缓存策略
- 实现混合精度计算,为sink相关的计算使用更高精度
- 增强扰动鲁棒性,通过针对性的扰动训练强化sink的作用
结论
Attention sink不是一个偶然的现象或设计缺陷,而是Transformer架构应对深度和长上下文挑战的必然适应。它通过控制信息混合速度,使模型能够在深度和上下文长度增加的情况下保持表示的有效性和区分性。
理解这一机制不仅深化了对LLMs内部工作原理的认识,还为开发更高效、更强大的下一代语言模型提供了理论基础和实用指导。这项研究将attention sink从一个需要被缓解的问题,转变为一个可以被理解和利用的有价值机制,为LLMs的进一步发展开辟了新的视角。