

CAMEL 项目是一个开源社区项目,致力于研究大规模代理系统的行为表现。该项目聚焦于理解多智能体系统中涌现的行为、能力以及潜在风险,并通过多种模块和接口为自动化和协作型 AI 的研究提供工具和数据集。
📜 关键设计原则
• Evolvability(可进化性) – CAMEL 的架构允许代理系统通过生成数据并与环境交互,实现持续进化。无论是通过具有可验证奖励的强化学习,还是通过监督学习,该项目的基础设施都鼓励通过迭代改进来不断优化系统。
• Scalability(可扩展性) – 框架设计支持数以百万计代理系统的协同工作,重点保障高效的协调、通信和资源管理,使研究者能够模拟和分析复杂的多智能体环境。
• Stateful Memory(有状态记忆) – CAMEL 中的代理拥有持久记忆,这让它们能够进行多轮交互,保留历史上下文,并逐步应对复杂任务。
• Code-as-Prompt(代码即提示) – 每一行代码及其注释都充当代理的提示。这种设计确保人类和代理都能清晰理解代码的意图,促进研究工作的透明性和可复现性。
 D. png">✅
D. png">✅
🚀 为什么选择 CAMEL 进行研究?
CAMEL 受到了研究社区的青睐,主要有以下几个原因:
✅ 大规模代理系统:研究者可以模拟多达 100 万个代理,有助于揭示在复杂多智能体环境中涌现的行为和扩展规律。
✅ 动态通信:该框架促进代理之间实时互动,模拟逼近许多现实中协作场景的工作模式。
✅ 有状态记忆与基准评测:通过为代理提供历史上下文和一系列基准测试,CAMEL 能够对代理的性能和协同效率进行严格评价。
✅ 跨领域支持:CAMEL 支持多种代理类型、任务、模型和环境,使其成为跨学科实验的理想工具,从数据生成、任务自动化到完整的世界模拟均可涵盖。
✅ 数据生成与工具集成:CAMEL 自动创建大规模、结构化的数据集,并与多种工具无缝集成,从而简化研究工作流程与合成数据生成。
💻 使用 CAMEL 可以构建什么?
该项目不仅仅停留在理论层面,其 README 中展示了具体的应用模块:
- 数据生成
CAMEL 内置生成链式思维(Chain-of-Thought)数据、自指导数据以及从源数据至合成数据(source2synth)的模块,研究人员可以利用这些工具创建专门的数据集,以训练或微调模型。 - 任务自动化
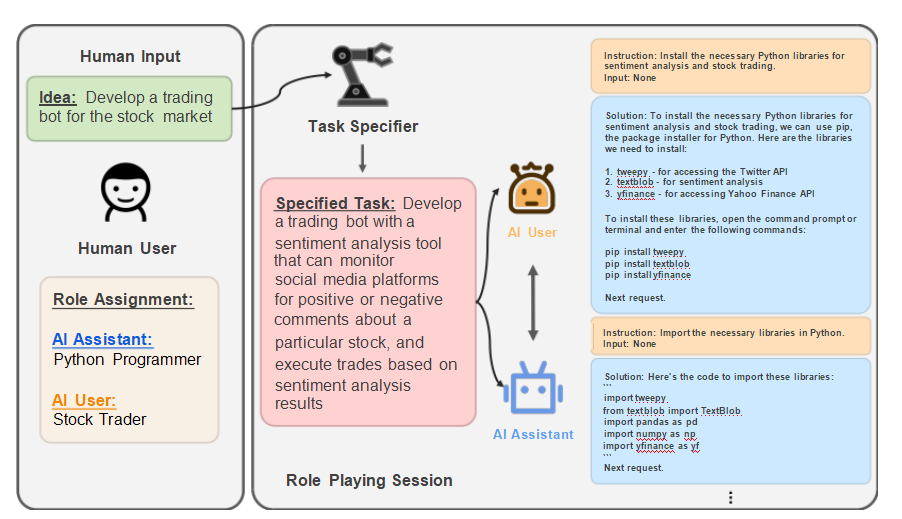
项目提供了角色扮演、劳动力管理以及基于检索增强生成(RAG)流水线的工具,帮助构建支持代理协同工作的系统,例如模拟 Python 程序员与股票交易员合作开发股票交易机器人。 - 世界模拟
像 Oasis 这样的项目展示了 CAMEL 支持的模拟环境,在这些环境中代理能够与动态世界进行交互,这是研究长周期合作与涌现行为的重要工具。
🛠️ 快速入门及技术栈
为了便于使用,CAMEL 已在 PyPI 上发布。只需在终端中运行「pip install camel-ai」命令,就可以获得该项目背后的丰富技术栈,该技术栈包括代理、数据生成、记忆、工具、存储、基准测试等模块。详细的安装说明和配置选项可在 docs.camel-ai.org 上找到。
📚 研究、数据集与社区
CAMEL 拥有一个全球性、社区驱动的研究集体,超过 100 名研究者共同致力于探索代理的扩展规律和相关现象。项目还提供了多个合成数据集(如 AI Society、Code、Math、Physics、Chemistry 以及 Biology),供标准化基准测试和通过 Nomic Atlas 等工具展示指令和任务的详细可视化分析。
此外,CAMEL 积极鼓励通过多种渠道(Discord、微信、X. ��Twitter)、GitHub 以及 Reddit)进行社区互动,研究者和爱好者可以在这些平台上合作、反馈和共同推动多智能体系统研究的前沿。✅
🔗 贡献与引用
该项目完全开源,采用 Apache 2.0 许可证,并在 README 中详细说明了如何贡献代码、报告问题以及参与社区活动。对于学术论文,CAMEL 还提供了标准引用格式,方便研究人员在文献中给予适当致谢。
总之,CAMEL 为探索多智能体系统研究前沿提供了全面的工具包和社区资源。它融合了可扩展的架构、动态通信和有状态设计,并配备了实际模块和数据集,不断邀请研究者探索代理之间如何合作、学习和进化于复杂环境之中。