🧠 引言:当AI学会反思自己的思维过程
想象一下,你正在解决一道复杂的数学题。开始时,你选择了一条看似合理的解题路径,但几步之后发现自己陷入了死胡同。这时,你会怎么做?大多数人不会固执地继续原来的方法,而是会停下来,反思自己的思路,然后尝试新的策略。这种」思考如何思考」的能力,在认知科学中被称为」元认知」(metacognition)。
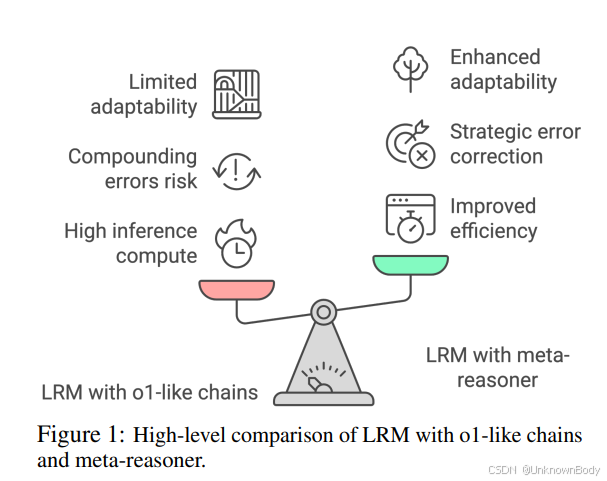
然而,当前最先进的大语言模型(LLMs)在解决复杂问题时,往往缺乏这种能力。它们通常采用」思维链」(Chain-of-Thought,CoT)等方法,一步步推理,但一旦走错路,就很难自我纠正。就像一个没有地图的旅行者,即使意识到自己迷路了,也不知道该如何重新规划路线。
来自新加坡国立大学和耶鲁大学的研究团队最近提出了一个名为」Meta-Reasoner」的创新框架,旨在解决这一问题。这个框架为大语言模型赋予了」思考如何思考」的能力,使其能够在推理过程中动态调整策略,避免在无效路径上浪费计算资源,从而更高效地解决复杂问题。
🔍 现有推理方法的局限性:为什么AI会」钻牛角尖」?
当前的大语言模型在解决复杂问题时,通常依赖于类似o1的长链推理方式,这种方法允许模型在给出最终答案前」长时间思考」。虽然这种方法在数学问题、逻辑推理和科学问题上取得了令人印象深刻的成绩,但它存在两个关键缺陷:
- 计算开销大:试错性质的推理过程往往需要大量计算资源。
- 错误传播:推理链早期的错误会在后续步骤中放大,导致整个推理过程偏离正确轨道。
现有的一些方法,如部分修订或回溯,虽然能在一定程度上解决这些问题,但它们通常只能处理狭窄范围内的推理步骤,缺乏系统性地评估整个推理路径是否可行的能力。因此,模型容易陷入不太有希望的推理轨迹中,持续在无效路径上消耗计算资源,而不是认识到何时需要进行重大的策略转变。
🌟 Meta-Reasoner:AI的」思维导师」
Meta-Reasoner框架的核心理念是将」思考内容」与」思考方式」分离。它引入了一个专门的」元推理器」模块,该模块与大语言模型并行工作,充当其」顾问」,动态评估推理过程,并在进展停滞时提供高层次的指导和策略重定向。
🔄 工作流程:三步循环迭代
Meta-Reasoner的工作流程包括三个循环迭代的步骤:
- 思维链生成:大语言模型基于用户查询和之前的指导生成推理步骤,扩展其思维链。
- 进度报告:将详细的思维链总结为简洁的进度报告,捕捉关键信息。
- 策略生成:元推理器评估进度报告,选择最佳策略指导下一步推理。
这个过程不断重复,直到任务完成或达到最大迭代次数。
🎯 策略选择:上下文多臂赌博机
Meta-Reasoner将策略选择问题建模为上下文多臂赌博机(contextual multi-armed bandit)问题。在这个框架中,每种可能的推理策略(如」从头开始」、」回溯到错误发生点」或」继续并提供具体建议」)被视为一个」赌博机臂」。
元推理器根据当前的推理进度(上下文)选择最有希望的策略(臂),并根据策略执行后的奖励(推理进展)更新其选择策略。这种方法能够平衡」探索」(尝试不同策略以收集信息)和」利用」(选择过去在类似情况下表现良好的策略)。
研究团队考虑了两种设置:
- 固定上下文赌博机:从预定义的策略集中选择。
- 动态上下文赌博机:元推理器本身是基于LLM的代理,可以动态引入或改进新策略。
📊 实验结果:Meta-Reasoner的惊人表现
研究团队在多个具有挑战性的数据集上评估了Meta-Reasoner的性能,包括24点游戏、SciBench(大学水平科学问题)和TheoremQA(定理驱动的数学问题)。
🎮 24点游戏:从4%到94%的飞跃
在24点游戏中,基本的提示策略如CoT和SC-CoT分别只能达到4%和9%的准确率。而Meta-Reasoner与GPT-4o-mini结合使用时,准确率达到了89%,与GPT-4o结合时达到92%,与Gemini-Exp-1206结合时更是达到了94%。这一性能甚至超过了专门设计的o1-mini模型(89%)和o1-preview模型(93%)。
📚 SciBench:数学问题的卓越表现
在SciBench数据集的数学相关子集上,Meta-Reasoner同样表现出色。与GPT-4o-mini结合时,在微积分(Calc)问题上的准确率达到80.23%,与GPT-4o结合时更是达到84.17%,远超基线方法。
📐 TheoremQA:定理推理的突破
在TheoremQA数据集上,Meta-Reasoner与GPT-4o-mini结合使用时,准确率达到84.13%,与Gemini-Exp-1206结合时达到86.32%,显著优于基线方法如CoT(39.46%)和Reflexion(74.32%)。
⚖️ 效率与准确性的平衡
Meta-Reasoner不仅在准确率上表现出色,在推理效率方面也取得了良好的平衡。与其他高级方法(如ToT和MACM)相比,Meta-Reasoner在实现更高准确率的同时,保持了适中的推理成本,使其成为一种可扩展且高效的解决方案。
🧩 Meta-Reasoner的关键组件分析
为了深入了解Meta-Reasoner的工作机制,研究团队进行了消融研究,分析了各个组件的贡献:
- 进度报告的作用:移除进度报告会导致性能适度下降,表明简洁的中间总结有助于元推理器专注于高层次策略,而不是被推理过程的细节所困扰。
- 多臂赌博机的重要性:移除多臂赌博机会带来更明显的性能下降,特别是当策略选择回退到直接思维链方法时。这验证了元推理器模块在帮助模型保持最优解决方案轨道上的效果。
- 固定vs动态赌博机:动态赌博机方法(能够自适应探索更多策略)比固定策略集(如K=3或K=5)表现更好,突显了灵活分配多样化推理策略的好处。
🔄 累积奖励分析:Meta-Reasoner如何学习
研究团队还分析了不同设置下的累积奖励,比较了基于LinUCB的Meta-Reasoner与直接使用LLM选择策略的基线方法和随机搜索方法。结果表明,基于多臂赌博机的Meta-Reasoner在两个不同任务(24点游戏和TheoremQA)和两种模型规模(GPT-40-mini和Gemini-Exp-1206)上始终优于其他方法。
虽然直接使用LLM可能产生合理的初始性能,随机搜索也几乎不需要设置成本,但这两种方法都无法系统地平衡探索和利用。相比之下,多臂赌博机更新策略利用先前迭代的反馈自适应地改进其行动选择,稳步增加累积奖励。
💡 Meta-Reasoner的启示:AI如何更像人类思考
Meta-Reasoner的成功不仅在于其技术创新,更在于它对人类认知过程的模拟。它借鉴了人类元认知和双重处理理论的见解,将LLM生成CoT步骤的过程类比为」系统1″(快速、自动的思考),将Meta-Reasoner提供高层次战略监督的过程类比为」系统2″(慢速、深思熟虑的思考)。
这种责任分离使框架能够平衡效率与稳健的问题解决能力,其中LLM处理常规推理,而元推理器在需要高层次战略调整时进行干预。这种设计不仅提高了模型的性能,还使其推理过程更加透明和可解释,为构建更加人性化的AI系统提供了新的思路。
🚀 未来展望:Meta-Reasoner的潜力与局限
尽管Meta-Reasoner在提高推理时间推理方面非常有效,但它仍然存在一些关键限制:
- 奖励函数依赖:它依赖于精心设计的奖励函数来指导策略选择。如果奖励信号不能准确反映正确性或进展,元推理器可能会坚持错误的策略。
- 动态策略的不稳定性:虽然动态添加或改进策略增加了元推理器的灵活性,但也可能引入不稳定性。过于复杂或定义不清的新策略可能会造成混乱,而不是增强问题解决能力。
未来的研究方向可能包括:
- 更复杂任务的适应:扩展Meta-Reasoner以处理更主观或复杂的任务,如创意写作或复杂定理证明。
- 多代理协作:将Meta-Reasoner与多代理系统结合,实现更复杂的协作推理。
- 个性化元认知:根据用户偏好或任务特性定制元推理策略。
🌐 结论:思考如何思考的AI新时代
Meta-Reasoner代表了AI推理能力的重要进步,它不仅提高了模型解决复杂问题的能力,还优化了推理时间的效率。通过充当」顾问」,Meta-Reasoner动态评估推理过程并提供高层次的战略指导,解决了类o1推理链的关键限制,如错误累积和推理计算效率低下。
与传统推理方法不同,Meta-Reasoner专注于全局监督而非细粒度的逐步过程,使大语言模型能够避免无效的思路,更好地分配计算资源。实验结果突显了动态推理链克服LLM推理过程固有挑战的潜力,并在更广泛的应用中展示了前景,为推理密集型任务提供了可扩展且适应性强的解决方案。
Meta-Reasoner的出现,标志着AI正在从简单的」思考」向更高级的」思考如何思考」迈进,这一进步不仅提高了AI的问题解决能力,也使其推理过程更加接近人类的认知方式,为构建更加智能、高效的AI系统开辟了新的可能性。
📚 参考文献
- Sui, Y. , He, Y., Cao, T., Han, S., & Hooi, B. (2025). Meta-Reasoner: Dynamic Guidance for Optimized Inference-time Reasoning in Large Language Models. arXiv:2502.19918v1.✅
- Wei, J. , Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., … & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35.✅
- Yao, S. , Yu, D., Zhao, J., Shafran, I., Griffith, T. L., Xu, Y., & Shen, J. (2023). Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601.✅
- Lei, Y. , Peng, B., Xie, Y., Achiam, J., & Jia, R. (2024). MACM: Advancing Complex Reasoning through Multi-Agent Condition Mining. arXiv preprint arXiv:2402.11482.✅
- Li, L. , Chu, W., Langford, J., & Wang, X. (2012). Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms. In Proceedings of the fifth ACM international conference on Web search and data mining.✅