🌟 引子:从语音到魔法的旅程
想象一下,你对着设备说:「给我来段粤语版的《Rap God》。」几秒钟后,设备不仅完美复刻了你的语气,还带着地道的粤语腔调唱起了 Eminem 的经典。这听起来像科幻小说里的情节,但 Step-Audio 的诞生让这一切成为了现实。
Step-Audio 是业界首个集语音理解与生成控制为一体的开源实时语音对话系统。它不仅能听懂多语言对话,还能表达情感、模仿方言、甚至唱歌和哼唱。今天,我们就来揭开这个语音魔法师的神秘面纱。
🧠 Step-Audio 的大脑:模型组成
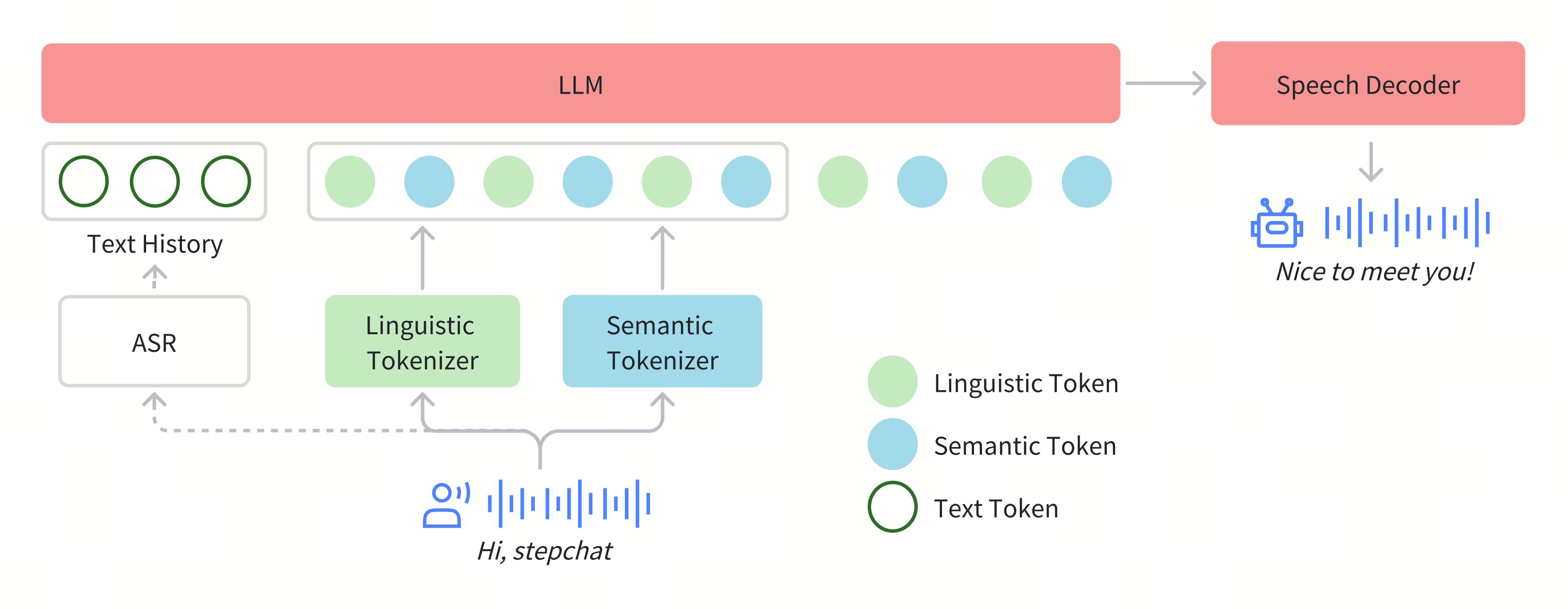
🧩 双码本的交响乐:Tokenizer 的奥秘
在 Step-Audio 的世界里,语音被分解成两种「语言」:Linguistic Tokenizer 和 Semantic Tokenizer。
- Linguistic Tokenizer:像一个语言学家,专注于语音的基础结构,码本大小为 1024,码率为 16.7Hz。
- Semantic Tokenizer:更像一个艺术家,捕捉语音的细腻情感和声学细节,码本大小为 4096,码率为 25Hz。
两者以 2:3 的时序交错策略完美配合,就像一场交响乐中的弦乐与管乐,既分工明确又和谐统一。

🧠 语言模型:1300 亿参数的巨人
Step-Audio 的核心是一个拥有 1300 亿参数的语言模型,称为 Step-1。这个模型通过持续的音频预训练,掌握了跨模态的语音理解能力。它不仅能将语音转化为文本,还能从文本生成自然流畅的语音。
🎶 语音解码器:从符号到声音的魔术
语音解码器是 Step-Audio 的「发声器官」。它将离散的语音标记转化为连续的语音信号。其架构结合了:
- 流匹配模型(Flow Matching Model):确保生成语音的流畅性。
- 梅尔频谱声码器(Mel-to-Wave Vocoder):将频谱信息转化为真实的语音波形。
通过 双码交错训练方法,解码器实现了语义与声学特征的无缝融合,生成的语音既自然又清晰。
⚡ 实时推理管线:语音交互的高速公路
为了实现实时语音交互,Step-Audio 的推理管线经过了精心优化。核心模块包括:
- 语音活动检测(VAD):实时捕捉用户语音的起止点。
- 流式音频分词器:将音频流分解为可处理的片段。
- 上下文管理器:动态维护对话历史,确保对话的连贯性。
这套系统就像一条高速公路,确保语音从输入到输出的每一步都快速且高效。
🚀 魔法的力量:Step-Audio 的核心亮点
🌍 多语言对话:语言不再是障碍
Step-Audio 支持中文、英文、日语等多语言对话。无论你是用粤语聊天,还是用英语讨论学术问题,它都能轻松应对。
🎭 情感与方言:语音的个性化表达
Step-Audio 不仅能模仿情绪(如开心、悲伤、生气),还能生成多种方言(如粤语、四川话)。试想一下,它可以用四川话给你讲段子,用粤语唱《喜帖街》。
🎤 音乐天赋:从 RAP 到哼唱
Step-Audio 的音乐能力令人惊叹。它不仅能 RAP,还能哼唱旋律。更重要的是,这些声音都可以根据用户需求进行细粒度控制,比如语速、音调和韵律风格。
🛠️ 工具调用:复杂任务的得力助手
通过 ToolCall 机制,Step-Audio 可以调用外部工具完成复杂任务。例如,它可以在对话中扮演角色,甚至帮助用户完成一些专业的语音处理任务。
📊 性能对比:Step-Audio 的实力
在多个基准测试中,Step-Audio 的表现令人瞩目。
🗣️ 语音识别
在 Aishell-1 数据集上,Step-Audio 的错误率(WER)仅为 0.87%,远低于其他主流模型。
| 数据集 | Whisper Large-v3 | Qwen2-Audio | Step-Audio |
|---|---|---|---|
| Aishell-1 | 5.14% | 1.53% | 0.87% |
🎶 语音合成
在语音合成任务中,Step-Audio 的内容一致性和音质评分均领先于其他模型。例如,在中文测试集上,其 CER(字符错误率)仅为 1.31%。
| 模型 | CER (%) ↓ | 音质评分 ↑ |
|---|---|---|
| CosyVoice | 3.63 | 0.775 |
| Step-Audio-TTS-3B | 1.31 | 0.733 |
🤖 语音对话
在 StepEval-Audio-360 基准测试中,Step-Audio 的对话得分高达 4.11,远超其他语音对话系统。
| 模型 | 对话得分 ↑ |
|---|---|
| GLM4-Voice | 3.49 |
| Step-Audio-Chat | 4.11 |
🎨 魔法的应用:Step-Audio 的多样化场景
🎧 音频克隆
Step-Audio 可以根据用户提供的音频样本,生成与原声极为相似的语音。例如,它可以模仿名人的声音,用于影视配音或虚拟助手。
🎵 语速与情感控制
用户可以通过简单的指令,调整语音的语速或情感。例如,让它用撒娇的语气说话,或者用慢速复述绕口令。
🌐 多语言支持
Step-Audio 能够在多种语言之间无缝切换。例如,它可以用英语回答问题,用日语打招呼,再用中文继续对话。
🛠️ 如何使用 Step-Audio
📥 模型下载
Step-Audio 的模型可以通过 Huggingface 或 Modelscope 下载。
🔧 安装与运行
安装步骤简单明了:
- 克隆代码库并安装依赖项。
- 下载模型文件并配置路径。
- 运行推理脚本,开始体验 Step-Audio 的强大功能。
🏆 结语:语音交互的未来
Step-Audio 的出现标志着语音交互技术的一个新纪元。从多语言支持到情感控制,从语音克隆到音乐生成,它为我们展示了语音技术的无限可能。或许在不久的将来,Step-Audio 不仅会成为我们的语音助手,还会成为我们的朋友、老师,甚至是艺术创作者。
让我们拭目以待,见证 Step-Audio 如何改变我们的生活!
📚 参考文献
- Step-Audio 团队. Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction. 2025.
- Step-Audio 技术报告.
- Huggingface 模型库.
- Modelscope 模型库.