在人工智能的浩瀚星海中,提示(prompt)犹如点燃语言模型潜力的火花。它们决定了模型的回答是否精准、是否符合任务需求。然而,设计一个优秀的提示并非易事。传统的提示设计往往需要人工反复试验,既耗时又需要专业知识。而自动化提示优化(Prompt Optimization, PO)方法虽然有所改进,却依赖于外部参考数据或人工反馈,这在实际应用中常常受限。
那么,有没有一种方法可以摆脱对外部数据的依赖,同时实现高效的提示优化呢?答案是肯定的!今天,我们将深入探讨一项开创性的研究——自我监督提示优化(Self-Supervised Prompt Optimization, SPO),一种无需外部参考的提示优化框架,它不仅高效,还能在封闭式与开放式任务中表现出色。
🌟 提示优化的挑战:从人工到自动化
🛠️ 人工提示设计的困境
在大语言模型(LLMs)如 GPT-4 和 Claude 的时代,提示的设计直接影响模型的推理能力和任务完成的质量。一个好的提示不仅需要清晰地表达任务要求,还要能引导模型沿着正确的逻辑路径进行推理。然而,手工设计提示往往需要:
- 专业知识:设计者需要对任务有深入的理解。
- 反复试验:需要多次调整和测试提示,才能找到最佳方案。
- 高昂成本:时间和人力资源的投入非常大。
🤖 自动化提示优化的局限
为了减少人工设计的负担,研究者们提出了自动化提示优化方法。这些方法通常通过以下步骤实现优化:
- 生成候选提示:通过模型或算法生成多个可能的提示。
- 执行任务:使用候选提示生成模型输出。
- 评估提示质量:通过外部参考(如人工标注数据或人工反馈)评估输出的质量。
- 优化提示:根据评估结果改进提示。
虽然这些方法在一定程度上提高了效率,但它们存在两个主要问题:
- 对外部参考的依赖:大多数方法需要人工标注的「标准答案」或人工反馈来评估提示质量。然而,在开放式任务中,标准答案往往不存在或难以定义。
- 高计算成本:为了获得稳定的评估结果,这些方法通常需要对大量样本进行评估,导致计算资源的消耗巨大。
🧩 SPO 的创新:从模型中寻找优化信号
🔍 核心洞察
SPO 的提出基于两个关键观察:
- 提示质量直接体现在模型输出中:不同提示会显著影响模型的推理路径和输出特征,这意味着我们可以通过比较输出来评估提示的优劣。
- 模型具有评估自身输出的能力:研究表明,大型语言模型可以有效地评估输出是否符合任务要求。
基于以上洞察,SPO 不再依赖外部参考,而是通过模型自身的输出来生成优化信号。这种方法类似于自我监督学习(self-supervised learning),从数据中挖掘训练信号。
⚙️ SPO 的工作机制
SPO 的核心是一个「优化-执行-评估」(Optimize-Execute-Evaluate)的循环,如下所示:
- 优化函数(ϕopt):生成新的候选提示。
- 执行函数(ϕexe):使用候选提示生成模型输出。
- 评估函数(ϕeval):通过模型对输出进行两两比较,选择更优的提示。
这一过程从一个基础提示模板开始,经过多次迭代,不断优化提示,直到达到预定的优化次数或性能目标。
🧪 实验验证:SPO 的卓越表现
📊 性能与成本的双重胜利
SPO 的表现如何?研究者在多个数据集上对其进行了测试,包括封闭式任务(如数学问题求解、事实验证)和开放式任务(如写作、角色扮演)。结果显示:
- 性能优越:在多个基准测试中,SPO 的提示优化效果优于现有方法,甚至在某些任务上达到了最优。
- 成本极低:SPO 的优化成本仅为现有方法的 1.1% 至 5.6%,平均每个数据集的成本仅为 $0.15。
以下是 SPO 与其他方法在六个提示优化方法上的性能和成本对比:
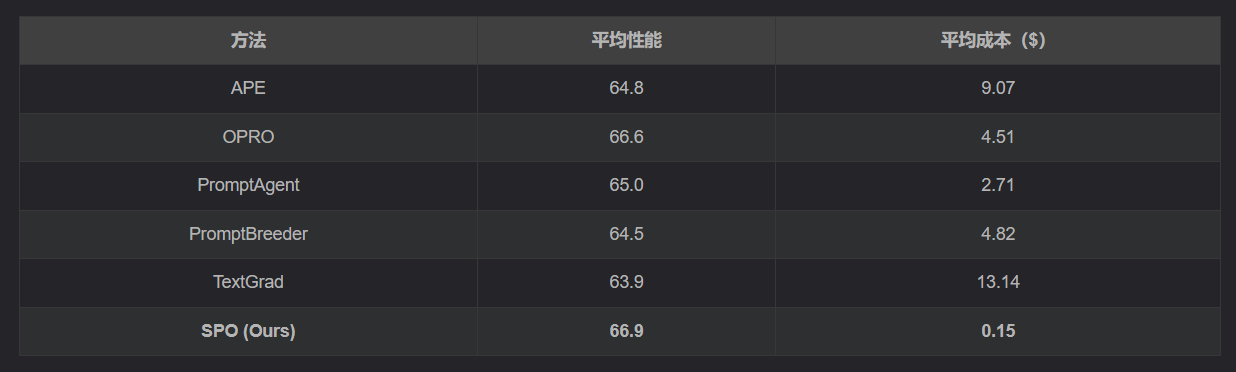
从表中可以看出,SPO 在性能上与最佳方法持平甚至更优,但成本却大幅降低。
🧮 封闭式任务的优化
在数学问题求解(AGIEval-MATH)和事实验证(LIAR)等任务中,SPO 展现了强大的优化能力。例如,在数学任务中,SPO 的优化提示能够显著提高模型的解题准确率,同时减少了对样本数量的需求。
✍️ 开放式任务的表现
在写作、角色扮演等开放式任务中,SPO 同样表现出色。例如,在「为咖啡品牌创作互动推文」的任务中,SPO 优化后的提示能够生成更具创意和互动性的内容,与用户建立更深的情感连接。
🔬 SPO 的理论基础:为什么它有效?
SPO 的成功并非偶然,其理论基础可以归结为以下两点:
- 输出作为优化指导:SPO 的优化信号直接来源于模型对输出质量的理解,而非外部参考。这种方法能够更自然地将提示调整为模型理解的最佳任务解决方案。
- 输出作为评估参考:通过两两比较输出,SPO 能够有效评估提示的相对质量。这种方法避免了对大量样本的依赖,同时提供了清晰的优化方向。
🛠️ 实际应用与未来展望
🌍 现实场景中的应用
SPO 的低成本和高效性使其在实际应用中具有广泛的潜力。例如:
- 教育领域:优化提示以生成更符合学生需求的学习材料。
- 商业场景:为广告文案、社交媒体内容等生成更具吸引力的文本。
- 科学研究:帮助研究者快速生成高质量的实验设计或数据分析提示。
🚀 未来的可能性
尽管 SPO 已经展现了强大的能力,但仍有改进空间。例如:
- 更复杂的任务:探索 SPO 在多轮对话或复杂推理任务中的表现。
- 跨领域优化:研究如何让 SPO 在不同领域间迁移提示优化能力。
- 结合人类反馈:在关键任务中,结合少量人类反馈进一步提升优化效果。
📜 结语:自我监督的力量
SPO 的出现为提示优化开辟了一条全新的道路。它不仅摆脱了对外部参考的依赖,还显著降低了优化成本,为大语言模型的实际应用注入了新的活力。在未来,我们有理由相信,SPO 将成为推动人工智能技术普及的重要工具,让更多人能够轻松驾驭语言模型的强大能力。
📚 参考文献
- Xiang, J. , Zhang, J., Yu, Z., et al. (2025). Self-Supervised Prompt Optimization. arXiv:2502.06855v1.✅
- Wei, J. , et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.✅
- Zheng, L. , et al. (2024). Benchmarking LLMs: A Comprehensive Study on Prompt Optimization.✅