Dettmers提出了一种高效的微调方法QLoRA,它能够在保持完整的16位微调任务性能的同时,将内存使用量降低到足以在单个48GB GPU上微调65B参数模型的程度。
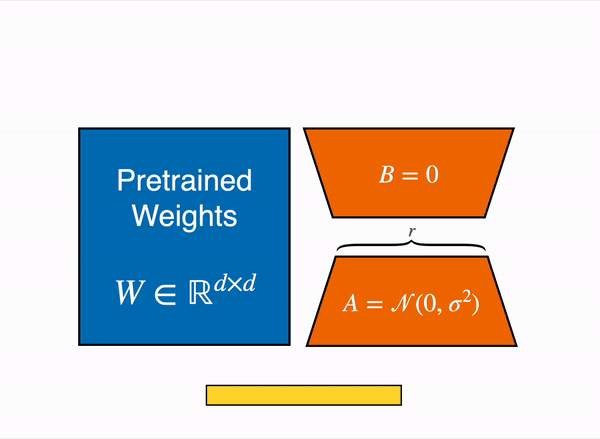
QLoRA通过在低秩适配器(LoRA)中将梯度反向传播到一个冻结的、4位量化的预训练语言模型。我们最优秀的模型家族,我们将其命名为Guanaco,在Vicuna基准测试中胜过之前所有公开发布的模型,达到了ChatGPT性能水平的99.3%,而仅需要在单个GPU上进行24小时的微调。QLoRA在不牺牲性能的前提下采用了许多创新技术来节省内存:
(a)4位NormalFloat(NF4),一种对于正态分布权重来说,从信息理论角度具有最优性的新数据类型;
(b)双重量化,通过量化量化常数来减少平均内存占用;
(c)分页优化器,以管理内存峰值。我们使用QLoRA对超过1000个模型进行微调,在8个指令数据集中,对多种模型类型(LLaMA,T5)以及在常规微调中难以运行的模型规模(例如33B和65B参数模型)进行了详细的指令跟随和聊天机器人性能分析。
结果表明,QLoRA在小型高质量数据集上的微调可以达到最先进的结果,即使使用比之前SoTA更小的模型。我们根据人类评估和GPT-4评估结果,对聊天机器人性能进行了详细分析,结果表明GPT-4评估是一种廉价且合理的人类评估替代方案。此外,当前的聊天机器人基准测试并不可靠,无法准确评估聊天机器人的性能水平。已发布了所有模型和代码,包括用于4位训练的CUDA内核。
artidoro/qlora: QLoRA: Efficient Finetuning of Quantized LLMs (github.com)
https://github.com/huggingface/blog/blob/main/4bit-transformers-bitsandbytes.md
https://github.com/huggingface/blog/blob/main/4bit-transformers-bitsandbytes.md
总结如下:
1. 研究者发布了一种名为QLoRA的新技术,可以高效地微调大型语言模型。
2. QLoRA通过使用4位量化模型和低秩适配器,能够在大大减少内存使用量的同时保持与16位完整模型微调相当的性能。
3. 他们利用QLoRA微调了一个名为Guanaco的最新模型系列,其中最大模型在聊天机器人能力方面接近 ChatGPT。
4. QLoRA 的工作原理是:将预训练模型参数量化到4位,然后在量化模型上使用低秩的可学习适配器参数恢复精度。 通过这种方法,可以实现与16位完整微调相当的性能,同时大幅减少内存使用。
5. Guanaco模型是在Open Assistant数据集上训练的,研究者认为它是目前最先进的开源聊天机器人模型之一,性能接近 ChatGPT。
6. QLoRA 使低成本的研究团队也能够微调大型模型,缩小与大公司的资源差距。长期而言,它可能实现将大型模型部署到手机和其他资源有限的环境。
7. 研究还发现,当前的聊天机器人评估基准存在局限性,人类评估存在主观性,目前未能准确评估聊天机器人的能力。
总结如下:
1. 研究者发布了一种名为QLoRA的新技术,可以高效地微调大型语言模型。
2. QLoRA通过使用4位量化模型和低秩适配器,能够在大大减少内存使用量的同时保持与16位完整模型微调相当的性能。
3. 他们利用QLoRA微调了一个名为Guanaco的最新模型系列,其中最大模型在聊天机器人能力方面接近 ChatGPT。
4. QLoRA 的工作原理是:将预训练模型参数量化到4位,然后在量化模型上使用低秩的可学习适配器参数恢复精度。 通过这种方法,可以实现与16位完整微调相当的性能,同时大幅减少内存使用。
5. Guanaco模型是在Open Assistant数据集上训练的,研究者认为它是目前最先进的开源聊天机器人模型之一,性能接近 ChatGPT。
6. QLoRA 使低成本的研究团队也能够微调大型模型,缩小与大公司的资源差距。长期而言,它可能实现将大型模型部署到手机和其他资源有限的环境。
7. 研究还发现,当前的聊天机器人评估基准存在局限性,人类评估存在主观性,目前未能准确评估聊天机器人的能力。
深度学习与bfloat16(BF16) https://blog.csdn.net/Night_MFC/article/details/107869478
深度学习与bfloat16(BF16) https://blog.csdn.net/Night_MFC/article/details/107869478
使用bitsandbytes、4 位量化和 QLoRA 使 LLM 更易于访问 https://zhuanlan.zhihu.com/p/632287465
使用bitsandbytes、4 位量化和 QLoRA 使 LLM 更易于访问 https://zhuanlan.zhihu.com/p/632287465
https://github.com/TimDettmers/bitsandbytes 8-bit CUDA functions for PyTorch
https://github.com/TimDettmers/bitsandbytes 8-bit CUDA functions for PyTorch
https://github.com/jllllll/bitsandbytes-windows-webui Windows compile of bitsandbytes for use in text-generation-webui.
https://github.com/jllllll/bitsandbytes-windows-webui Windows compile of bitsandbytes for use in text-generation-webui.
大型语言模型的量化(Quantization of Large Language Models) 大型语言模型的量化主要关注推理时的量化。为了保持16位语言模型的质量,主要方法集中在处理异常特征(如SmoothQuant 和LLM.int8() )以及使用更复杂的分组方法。有关有损量化方法的研究主要涉及正常舍入的权衡或如何优化舍入决策以提高量化精度。除我们的工作外,SwitchBack层是唯一在超过10亿参数规模上研究量化权重反向传播的工作。
使用适配器进行微调(Finetuning with Adapters) 尽管我们使用了低秩适配器(LoRA),但还有许多其他参数高效微调(PEFT)方法,如提示调优、调整嵌入层输入、调整隐藏状态(IA3)、添加完整层、调整偏置、基于Fisher信息学习权重掩码,以及一些方法的组合。在我们的工作中,我们展示了LoRA适配器能够达到完全的16位微调性能。我们将未来的工作留给其他PEFT方法的权衡研究。
指令微调(Instruction Finetuning) 为了使预训练的语言模型遵循提示中提供的指令,指令微调使用来自各种数据源的输入-输出对来微调预训练的语言模型,以生成给定输入作为提示的输出。
聊天机器人(Chatbots) 许多指令微调模型被设计为基于对话的聊天机器人,通常使用人类反馈的强化学习(RLHF)或使用现有模型生成数据并与AI模型反馈一起训练(RLAIF)。我们没有使用强化学习,但我们的最佳模型Guanaco是在Open Assistant数据集的多轮聊天交互中进行微调的,该数据集被设计用于RLHF训练。为了评估聊天机器人,已经开发了使用GPT-4而不是昂贵的人工注释的方法。我们通过更可靠的评估设置改进了这些方法的重点。
大型语言模型的量化(Quantization of Large Language Models) 大型语言模型的量化主要关注推理时的量化。为了保持16位语言模型的质量,主要方法集中在处理异常特征(如SmoothQuant 和LLM.int8() )以及使用更复杂的分组方法。有关有损量化方法的研究主要涉及正常舍入的权衡或如何优化舍入决策以提高量化精度。除我们的工作外,SwitchBack层是唯一在超过10亿参数规模上研究量化权重反向传播的工作。
使用适配器进行微调(Finetuning with Adapters) 尽管我们使用了低秩适配器(LoRA),但还有许多其他参数高效微调(PEFT)方法,如提示调优、调整嵌入层输入、调整隐藏状态(IA3)、添加完整层、调整偏置、基于Fisher信息学习权重掩码,以及一些方法的组合。在我们的工作中,我们展示了LoRA适配器能够达到完全的16位微调性能。我们将未来的工作留给其他PEFT方法的权衡研究。
指令微调(Instruction Finetuning) 为了使预训练的语言模型遵循提示中提供的指令,指令微调使用来自各种数据源的输入-输出对来微调预训练的语言模型,以生成给定输入作为提示的输出。
聊天机器人(Chatbots) 许多指令微调模型被设计为基于对话的聊天机器人,通常使用人类反馈的强化学习(RLHF)或使用现有模型生成数据并与AI模型反馈一起训练(RLAIF)。我们没有使用强化学习,但我们的最佳模型Guanaco是在Open Assistant数据集的多轮聊天交互中进行微调的,该数据集被设计用于RLHF训练。为了评估聊天机器人,已经开发了使用GPT-4而不是昂贵的人工注释的方法。我们通过更可靠的评估设置改进了这些方法的重点。
越小越好: Q8-Chat,在英特尔至强 CPU 上体验高效的生成式 AI https://github.com/huggingface/blog/blob/main/zh/generative-ai-models-on-intel-cpu.md
越小越好: Q8-Chat,在英特尔至强 CPU 上体验高效的生成式 AI https://github.com/huggingface/blog/blob/main/zh/generative-ai-models-on-intel-cpu.md
https://borrowastep.net/p/bitsandbytes-hzgevsyfz
https://borrowastep.net/p/bitsandbytes-hzgevsyfz
使用qlora对中文大语言模型进行微调
https://github.com/taishan1994/qlora-chinese-LLM
使用qlora对中文大语言模型进行微调
https://github.com/taishan1994/qlora-chinese-LLM