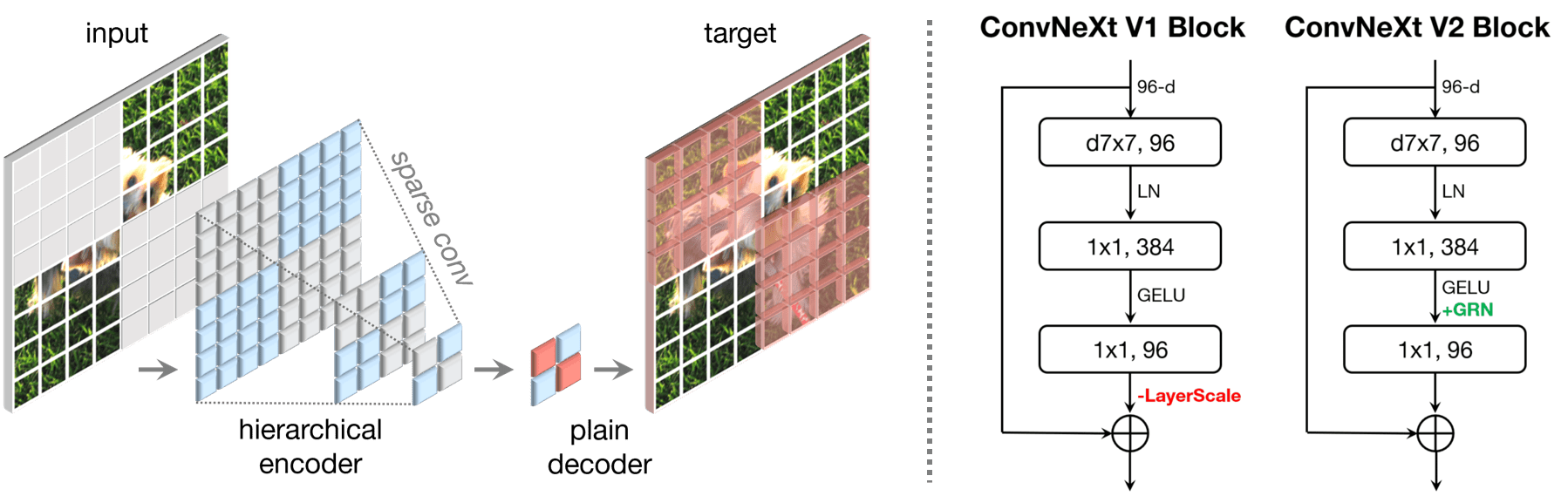
由于改进的架构和更好的表示学习框架的推动,视觉识别领域在 2020 年代初期迅速现代化并提高了性能。例如,现代卷积神经网络(ConvNets),以 ConvNeXt 为代表,在各种场景中表现出强大的性能。尽管这些模型最初是为具有 ImageNet 标签的监督学习设计的,但它们也可能从自监督学习技术(如遮蔽自动编码器(MAE))中受益。然而,我们发现简单地结合这两种方法会导致性能不佳。在本文中,我们提出了一个全卷积遮蔽自动编码器框架和一个新的全局响应归一化(GRN)层,这个层可以添加到 ConvNeXt 架构中以增强通道间特征竞争。这种自监督学习技术和架构改进的共同设计产生了一个名为 ConvNeXt V2 的新模型族,它显著提高了纯粹的 ConvNets 在各种识别基准上的性能,包括 ImageNet 分类、COCO 检测和 ADE20K 分割。我们还提供了各种尺寸的预训练 ConvNeXt V2 模型,从参数数量为 370 万的高效 Atto 模型(在 ImageNet 上的 top-1 准确率为 76.7%),到使用公共训练数据达到最先进的 88.9% 准确率的 6.5 亿参数的 Huge 模型。
[2301.00808] ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders (arxiv.org)
ConvNeXt-V2则是基于ConvNeXt替换使用稀疏卷积, 输入端也是做了类MAE的随机mask处理。
ConvNeXt-V2则是基于ConvNeXt替换使用稀疏卷积, 输入端也是做了类MAE的随机mask处理。
https://github.com/facebookresearch/ConvNeXt-V2
https://github.com/facebookresearch/ConvNeXt-V2