引言 🎉
在过去十年中,人工智能(AI)和机器学习(ML)取得了令人瞩目的成就,特别是在自然语言处理、游戏、机器人等领域。然而,尽管深度学习(DL)模型如雨后春笋般涌现,它们在面对持续学习(Continual Learning)时却显得力不从心。本文将探讨深度学习在持续学习环境中可塑性丧失的现象,以及如何通过新的算法来维护这一关键特性。
可塑性:深度学习的隐秘敌人 🔍
可塑性(Plasticity)是指系统在面对新信息时保持学习能力的能力,就像我们的大脑在学习新技能时不断调整自身。深度学习系统通常在两个阶段运行:一个阶段是更新网络的权重,另一个阶段是保持权重不变以进行评估。然而,这种方法在面对不断变化的数据时会遇到瓶颈,从而导致可塑性的丧失。
研究表明,标准的深度学习方法在持续学习设置中逐渐失去可塑性,甚至表现得不如浅层网络。我们通过实验发现,在使用经典数据集如ImageNet和CIFAR-100进行深度学习时,随着任务的增加,深度学习网络的学习能力显著下降,直至最终的表现与线性网络相当。
graph TD;
A[深度学习模型] --> B{是否持续学习?};
B -- 是 --> C[标准深度学习方法];
B -- 否 --> D[冻结权重];
C --> E[逐渐丧失可塑性];
E --> F[学习能力下降];
F --> G[表现不如线性网络];持续学习中的可塑性丧失的实验 🔬
在我们的研究中,我们使用了「持续ImageNet」任务,其中将ImageNet数据集转化为一系列二元分类任务。研究结果显示,采用标准反向传播算法的深度学习网络在前几个任务中表现良好,但随着任务的增加,性能却急剧下降。这种现象在不同的网络架构和学习算法中普遍存在。
例如,在处理2,000个任务后,网络的表现几乎降到线性网络的水平。图表1展示了在不同步长参数下的性能变化,表明可塑性丧失是普遍现象。

维护可塑性的新算法:持续反向传播 🛠️
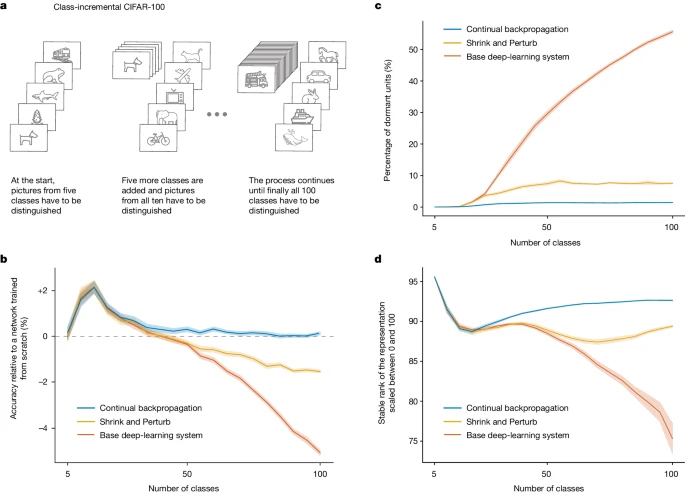
为了应对可塑性丧失问题,我们提出了一种新的算法——持续反向传播(Continual Backpropagation)。该算法通过在每次权重更新时随机重新初始化一小部分使用频率较低的单元来保持网络的多样性。实验结果显示,该方法能够有效维护可塑性,甚至在5000个任务后仍能保持高效果。通过对比不同的算法,如L2正则化和Shrink and Perturb,我们发现持续反向传播在防止可塑性丧失方面表现尤为突出。图表2展示了不同算法在CIFAR-100上的表现,持续反向传播显著优于其他方法。
深度学习的未来:走向持续学习 🌍
随着深度学习在更多应用中的普及,维持其可塑性将是未来研究的重点。我们相信,通过不断注入随机性并保持权重小的算法,深度学习系统将能够更好地适应变化的环境,实现真正的持续学习。
结论 🏁
深度学习在持续学习中的应用面临着可塑性丧失的挑战,但通过新的算法如持续反向传播,我们可以有效地缓解这一问题。这不仅为深度学习的未来打开了新的可能性,也为实现更智能的人工智能系统奠定了基础。
参考文献 📚
1. Dohare, S. et al. 「Loss of plasticity in deep continual learning.」 ✅Nature, 632, 768–774 (2024).
2. Chaudhry, A. et al. 「Riemannian walk for incremental learning: understanding forgetting and intransigence.」 In ✅Proc. 15th European Conference on Computer Vision (ECCV), 532–547 (Springer, 2018).
3. Kirkpatrick, J. et al. 「Overcoming catastrophic forgetting in neural networks.」 ✅Proc. Natl Acad. Sci., 114, 3521–3526 (2017).
4. Lyle, C. et al. 「Understanding and preventing capacity loss in reinforcement learning.」 In ✅Proc. 10th International Conference on Learning Representations (ICLR), 2022.
5. Rusu, A. A. et al. 「Progressive neural networks.」 Preprint at https://arxiv.org/abs/1606.04671 (2017).✅