

引言:LLM的局限性与AGI的曙光
近年来,大型语言模型(LLM)的蓬勃发展,为人工智能领域注入了新的活力,预示着通用人工智能(AGI)的曙光。然而,一些LLM初创公司认为,拥有近乎无限上下文长度的LLM就能实现AGI,这种观点或许过于乐观。本文将深入探讨LLM在实现AGI道路上面临的挑战,并提出一种基于AI原生记忆的AGI实现路径。
无限上下文并非万能解药

当前,许多研究致力于扩展LLM的上下文长度,例如,GPT-4的上下文窗口为32K tokens,而最新的GPT-4-turbo和GPT-4o模型可以处理128K tokens;Gemini 1.5则声称拥有1M或10M tokens的上下文窗口。学术界也探索了对抗长度外推和位置偏差的方法,一些研究甚至声称实现了「无限」的上下文长度。
然而,LLM是否能够有效利用超长甚至无限的上下文,目前尚无定论。我们认为,类似于人类的认知负荷,LLM能够处理的最大内容量可能存在固有限制。
有效上下文长度的局限性
现有的长上下文LLM通常采用「大海捞针」(NIAH)测试来评估其性能,即从大量无关文本中检索特定信息的能力。有效上下文长度则定义为测试LLM相较于强基线模型表现更优的最大长度。
然而,根据最近一项针对长上下文模型的基准测试研究(Hsieh et al., 2024),大多数(如果不是全部)LLM都夸大了其上下文长度。例如,声称拥有128K上下文长度的GPT-4,其有效上下文长度仅为64K. ��而ChatGLM的有效上下文长度仅为4K,远低于其声称的128K。✅
推理能力的瓶颈
为了进一步验证LLM在长上下文场景下的推理能力,我们提出了一种新的评估任务——推理大海捞针,旨在验证LLM在需要同时进行检索和推理时的能力。
我们以Mindverse AI的「第二自我」产品Mebot的真实用户数据为例,构建了8个不同的用户数据堆栈,并设计了6种不同的查询-信息对。实验结果表明,即使是最先进的LLM(如GPT-4o和GPT-4-turbo),在处理长文本和多跳推理时也表现不佳。
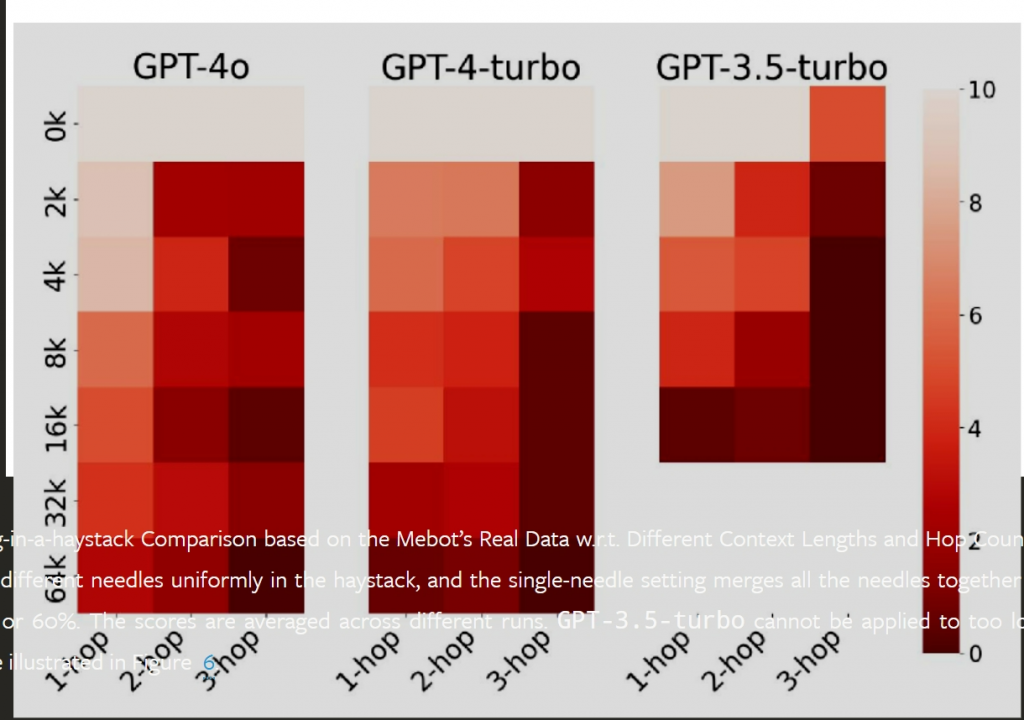
图2:基于Mebot真实数据的推理大海捞针比较
实验结果表明,响应质量与上下文长度和推理步骤数量呈负相关,这意味着LLM在处理长文本和多步推理方面存在困难。
AI原生记忆:通向AGI的关键
我们认为,AGI应该是一个类似于计算机的系统,其中LLM充当处理器,LLM的上下文充当RAM,而记忆则扮演着磁盘存储的角色。
RALM/RAG:记忆的初级形态
检索增强型LLM(RALM)可以通过筛选大量相关上下文来回答查询,可以看作是将记忆定义为仅包含原始数据的特例。然而,记忆不仅仅是原始数据,它还应该包含从原始数据中推理得到的重要结论,并能够被用户直接消费。
什么是AI原生记忆?
我们认为,AI原生记忆的最终形态是一个深度神经网络模型,它能够参数化和压缩所有类型的记忆,甚至是无法用自然语言描述的记忆。为了确保与同一个AGI代理交互的不同用户的记忆隐私,我们认为最佳实践是为每个用户维护一个独立的记忆模型。我们将这种介于AGI代理和特定用户之间的记忆模型称为该用户的大型个人模型(LPM)。
LPM记录、组织、索引和排列关于个人的每一个细节,最终为用户提供直接访问记忆的接口,并为下游应用程序(如个性化生成、推荐等)提供有用、完整的上下文。
LPM的实现级别
我们设想LPM的实现可以分为三个级别,复杂度递增:
- L0:原始数据。这种方法类似于直接将RALM/RAG应用于原始数据,将记忆定义为所有原始数据。
- L1:自然语言记忆。指可以用自然语言形式概括的记忆,例如用户的简短个人简介、重要句子或短语列表以及偏好标签。
- L2:AI原生记忆。指不一定需要用自然语言描述的记忆,通过模型参数学习和组织。每个LPM都将是一个神经网络模型。
L1:自然语言记忆
在L1中,记忆将包含一组自然语言描述,例如关键词/标签、短语、句子甚至段落。这与信息提取和知识发现高度相关,包括短语挖掘、实体识别、关系提取、文本摘要、分类法构建等。
L1 LPM的开发者需要指定方案,例如定义各种有用的记忆类型,包括但不限于:
- (简短)个人简介:对用户的概括性描述,通常包含几句话。
- 用户的兴趣主题:可以看作是一组标签的集合(例如,「政治」、「篮球」)。
- 偏好:包括用户对各种事物的偏好。
- 社交关系:包括用户的社交关系,例如提到过谁和哪些组织。
L2:AI原生记忆
在L2中,记忆超越了自然语言形式,成为一个神经网络模型,因此我们将其命名为「AI原生」。该模型旨在编码用户的所有记忆。
L2 LPM可以看作是世界模型的个性化版本,它应该能够根据用户历史预测用户行为。
L2 LPM的挑战和潜在解决方案:
- 训练效率:一种直观但计算复杂的方法是为每个用户微调他们自己的LLM。
- 服务效率:随着越来越多的L2 LPM部署给用户,需要新的基础设施来服务这些模型。
- 冷启动:L2 LPM训练中的一个常见问题。
- 灾难性遗忘和冲突解决:确保学习新记忆的同时防止旧记忆的灾难性遗忘至关重要。
总结与展望
AI原生记忆作为AGI时代(主动)参与、个性化、分发和社交的变革性基础设施,具有巨大的潜力,同时也带来了隐私和安全方面的挑战。
我们相信,在未来,AGI代理将首先与AI原生记忆交互,并查看它是否能够提供必要的信息。如果不是,则由AI原生记忆与真实用户交互以找出更多信息。因此,AI原生记忆将成为用户与AGI代理之间所有交互和个性化的核心。