

引言
近年来,大型语言模型(LLM)的兴起彻底改变了自然语言处理(NLP)领域。尤其引人注目的是,LLM 的上下文学习能力使其能够作为自然语言生成任务的评估指标,这在低资源场景和时间受限的应用中尤为 advantageous。传统的评估指标,例如 BLEU 或 ROUGE,往往依赖于大量的人工标注数据,而 LLM 则可以通过少量的样本学习到评估文本质量的能力。
然而,尽管已经提出了许多基于提示的 LLM 评估指标,但目前仍然缺乏对不同提示方法进行结构化评估的研究,特别是对于开源模型而言。本文介绍了 PrExMe,一个针对评估指标的大规模提示探索框架。我们评估了超过 720 个提示模板,涵盖了机器翻译(MT)和摘要数据集上的开源 LLM 评估指标,总计超过 660 万次评估。这项广泛的比较 (1) 作为近期开源 LLM 作为评估指标的性能基准,(2) 探索了不同提示策略的稳定性和可变性。
相关工作
基于提示的评估指标
近年来,LLM 在自然语言生成(NLG)评估指标方面取得了显著进展,其主要依赖于上下文学习,即直接从生成的文本中预测质量判断。Li 等人(2024b)和 Gao 等人(2024a)的综述提供了对这些指标的全面概述。除了 BARTSCORE(Yuan 等人,2021 年)和 PRD(Li 等人,2024a),Li 等人(2024b)综述的基于提示的方法都建立在闭源模型之上。相比之下,EVAL4NLP 2023 共享任务(Leiter 等人,2023 年)明确考虑了开源的基于提示的指标,要求参与者仅使用提供的模型来评估机器翻译和摘要,而不能对这些模型进行微调。表现最好的提交甚至能够击败强大的基线,例如机器翻译领域的 GEMBA(Kocmi 和 Federmann,2023b)和摘要领域的 BARTSCORE。
提示技术
近年来,人们提出了许多成功的提示技术(例如,Liu 等人,2023a)。我们的工作主要依赖于已有的方法,如零样本 CoT 和 RAG。此外,Li 等人(2023 年)提出了情绪诱导提示,以提高 LLM 的性能。据我们所知,我们是第一个分析这种技术在评估指标中的应用的。受此启发,我们还提出了一种新颖的情绪-CoT 模式(见第 3 节)。Kocmi 和 Federmann(2023b)对基于提示的指标的输出格式进行了先前的评估,我们通过更广泛的评估对其进行了扩展。其他工作也使用分层模板来构建提示(例如 Fu 等人,2023 年),LangChain(Chase,2022 年)和 DSPy(Khattab 等人,2023 年)等工具也支持这种实现。我们使用分层模板作为结构化比较不同提示模式的一种手段。
提示鲁棒性
由于我们对不同的提示、数据集和任务进行了网格搜索,因此我们的工作建立在 LLM 如何响应提示扰动的研究基础之上,并对其进行了扩展。Webson 和 Pavlick(2022 年)、Leidinger 等人(2023 年)、Weber 等人(2023 年)以及 Sclar 等人(2023 年)发现,自然语言推理和情感分类的性能存在很大差异。作为解决方案,Sclar 等人(2023 年)建议提供不同提示扰动下的所有结果。Voronov 等人(2024 年)和 Mizrahi 等人(2024 年)认为,目前 LLM 的评估基准存在问题,因为它们通常每个任务只提供一个提示模板。这可以通过提供多个模板并评估其集合来解决。据我们所知,我们是第一个探索这些鲁棒性问题在多大程度上影响开源的基于 LLM 的指标,以及如何为其选择最佳提示的。此外,通过使用多个提示来提示 LLM,我们遵循了 Mizrahi 等人(2024 年)的做法,实现了对 LLM 的稳定和公平的评估。
研究方法
为了系统地研究不同提示方法对 LLM 评估指标的影响,我们构建了一个名为 PrExMe 的大规模提示探索框架。
提示模板
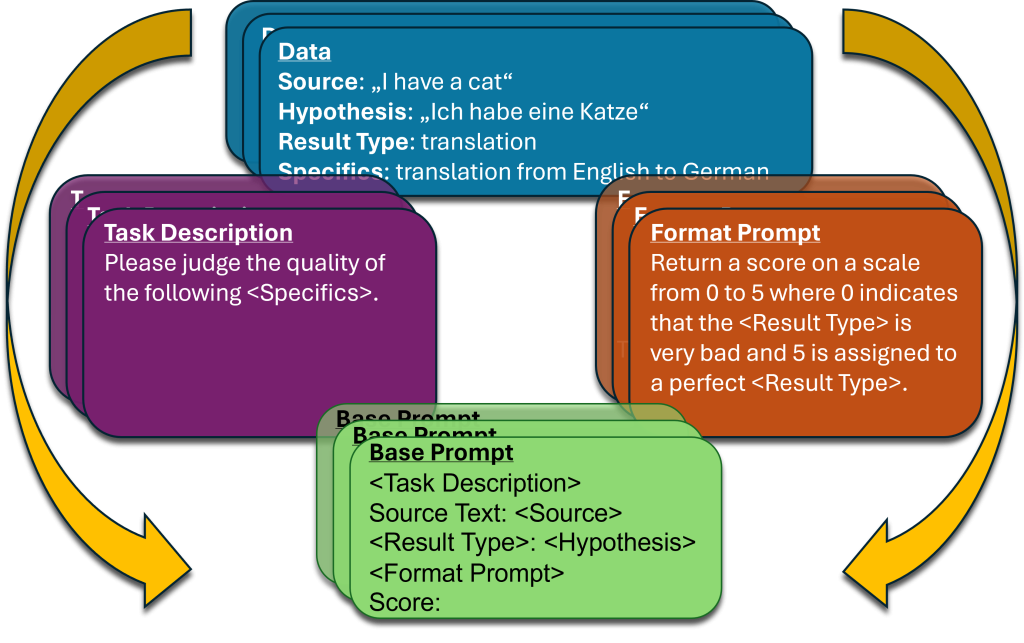
我们的提示被构建成分层模板(见图 1),即一个大的模板由多个小的模板构成。每个提示都由以下部分构成:(1) 需要评分的源文本和生成的假设文本,(2) 基本提示,(3) 任务描述,(4) 格式要求,以及 (5) 可选的单样本演示。表 1 展示了 (2)、(3)、(4) 和 (5) 的例子。
基本提示
基本提示是我们提示层次结构的顶层,它包含了其他组件。具体来说,我们测试了三个零样本(ZS)和相应的单样本(OS)基本提示:(1) 普通 ZS/OS (PZS/POS),(2) ZS/OS-COT,以及 (3) ZS/OS-CoT-Emotion (ZS/OS-COT-EM)。PZS 简单地呈现了用换行符分隔的任务描述、源文本、假设文本和格式要求。ZS-COT (KOJIMA ET AL.,2022) 另外要求模型在返回输出之前逐步思考。最后,ZS-COT-EM 要求模型在 ZS-CoT 提示之前描述其「情绪」。我们之所以包含 CoT,是因为它提高了基于提示的闭源指标(如 AUTOMQM Fernandes 等人(2023 年)和 GEMBA(Kocmi 和 Federmann,2023a))的性能。ZS-COT-EM 探索了在提示 LLM 描述其输出中的情绪时,LLM 性能的变化。这是由我们对情绪提示对指标性能的探索所推动的(见下文「任务描述」)。模板的 OS 版本添加了一个用于演示的字段。为了避免模型局限于特定的推理步骤,我们在 OS-CoT 中包含了一个占位符,模型应该在其中插入其推理。
任务描述
任务描述是给生成的假设评分的指令。Li 等人(2023 年)发现,对人类来说能引发某些情绪的 LLM 指令可以提高性能。受这一发现的启发,我们探索了在任务描述中使用「情绪提示」。这种方法主要提供了一种简单的改写策略,以扩大我们的网格搜索范围。此外,它还允许我们研究「情绪」对基于 LLM 的指标的影响。除了中性提示外,我们还包括了例如礼貌、威胁和怀疑的指令。我们自己创建了 11 个任务描述,并使用 CHATGPT (OpenAI, 2023) 创建了 13 个任务描述。
格式要求
格式要求描述了 LLM 在生成分数时应遵循的输出格式。例如,它包括输出分数应该在哪一范围内,以及应该是离散的还是连续的。此外,我们还包括要求 LLM 返回文本质量标签的提示。我们总共定义了 10 种格式要求。
单样本演示
最后,我们使用 RAG 构造可选的 OS 演示。我们从 WMT21 (Freitag 等人,2021 年) 中提取机器翻译的演示,从 ROSE (Liu 等人,2023b) 中提取摘要的演示。
基于 MQM 的方法
除了分层模板之外,我们还使用选定的开源 LLM 测试了 GEMBA-MQM (Kocmi 和 Federmann,2023a) 的提示。GEMBA-MQM 通常使用 GPT4,它根据出现的错误数量(按严重程度加权)来预测分数。我们将开源实现称为 LocalGemba。
数据集和阶段
我们的实验分两个阶段,使用不同的数据集。这样做是为了减轻大规模提示搜索带来的统计效应。此外,它还允许我们在完整的数据集上评估选定的提示(否则这项任务将非常耗费资源),并探索其泛化能力。
在第一阶段,我们使用 EVAL4NLP 2023 (Leiter 等人,2023 年) 的训练集进行评估;在第二阶段,我们使用其开发集和测试集进行评估。训练集和开发集是 WMT2022 指标共享任务 (Freitag 等人,2022 年) 和 SUMMEVAL (Fabbri 等人,2021 年) 的(无参考)分割。测试集由 Leiter 等人(2023 年)新标注。作为第二个测试集,我们使用了 WMT23 MQM 机器翻译标注 (Freitag 等人,2023 年) 和 Seahorse 多语言摘要标注 (Clark 等人,2023 年)。由于 OS 提示在其他数据集上的表现不佳,因此我们没有在 WMT23/SEAHORSE 上对其进行评估。
在第一阶段,我们评估了训练集上 720 个 ZS 提示的所有组合。由于这非常耗费资源,因此对于机器翻译,我们将每个语种对限制在第一阶段,我们评估了训练集上 720 个 ZS 提示的所有组合。由于这非常耗费资源,因此对于机器翻译,我们将每个语种对限制为 1,000 个样本。对于摘要,我们使用了 SUMMEVAL 中的所有样本。对于每个模型,我们选择 Kendall 的 τ 与人类判断的相关性最高的 10 个提示。在第二阶段,我们使用这些选定的提示来评估开发集和测试集,以及 WMT23/SEAHORSE。
模型
我们实验中使用的所有模型都可以在 HuggingFace Hub 上公开获取,并且可以在消费级硬件上运行。我们使用七个不同的模型: GPT2-XL (Radford 等人,2019 年)、OPT-IML-30B (Iyer 等人,2022 年)、BLOOM-7B1 (Scao 等人,2022 年)、Pythia-12B (Biderman 等人,2023 年)、StableLM-Base-Alpha-7B (Chiang 等人,2023 年)、OpenAssistant-Pythia-12B (Köpf 等人,2023 年) 和 PLATYPUS2-70B (Lee 等人,2023a)。我们选择这些模型是因为它们代表了不同大小、架构和训练数据集的开源 LLM 的多样化样本。
实验结果
RQ1:开源 LLM 的评估能力
为了回答关于开源 LLM 评估能力的第一个研究问题,我们分析了不同模型在不同数据集上的总体性能。图 2 显示了所有模型在所有数据集和任务上的平均 Kendall 的 τ。
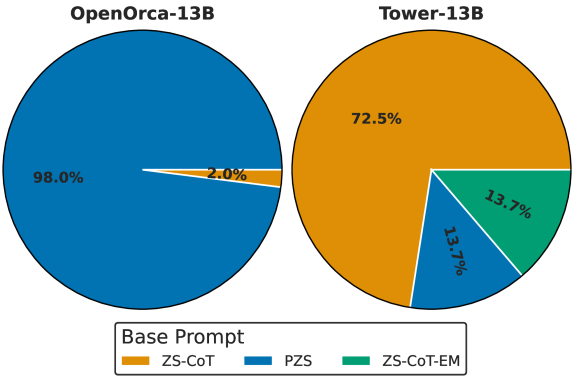
图2:不同模型在不同数据集上的平均 Kendall 的 τ。
总的来说,PLATYPUS2-70B 在所有数据集上都取得了最好的结果,这表明更大的模型更适合作为评估指标。然而,其他模型(如 OpenAssistant-Pythia-12B. ��在某些情况下也表现良好,这表明模型大小并不是性能的唯一决定因素。✅
RQ2:提示模式的稳定性为了研究不同提示模式的稳定性,我们分析了不同数据集、任务和模型之间 Kendall 的 τ 的变化。我们发现,某些提示模式(如要求模型返回文本标签而不是数字分数)对于某些模型(如 PLATYPUS2-70B. ��始终表现良好。然而,我们也发现,对于某些设置,即使是对输入提示进行微小的更改也会极大地影响性能。例如,将请求的输出格式从「0 到 100」更改为「-1 到 +1」会极大地影响我们评估中的排名。✅
RQ3:新评估场景的提示设计
根据我们的发现,我们为新评估场景的提示设计提出以下建议:
- 从简单的提示开始。 在许多情况下,简单的零样本提示就能获得良好的结果。
- 尝试不同的输出格式。 一些模型更喜欢返回文本标签,而另一些模型则在使用数字分数时表现更好。
- 考虑使用 CoT 提示。 CoT 提示可以帮助提高某些模型的性能,尤其是在评估复杂文本时。
- 在多个数据集上评估你的提示。 即使是表现良好的提示也可能无法很好地泛化到新数据集。
结论
在这项工作中,我们对不同提示方法对 LLM 评估指标的影响进行了大规模分析。我们的研究结果表明,某些提示模式是稳健的,并且可以很好地泛化到不同的任务和数据集。然而,我们也发现,对于某些设置,即使是对输入提示进行微小的更改也会极大地影响性能。根据我们的发现,我们为新评估场景的提示设计提出了一些建议。
参考文献
- Biderman, S. et al. (2023). Pythia: A suite for analyzing large language models across training and scaling. ✅arXiv preprint arXiv:2304.01355.
- Chase, H. (2022). Langchain. ✅https://github.com/hwchase17/langchain.
- Chiang, W. -L. et al. (2023). Stablelm-alpha 7b: Small and mighty for research. ✅https://github.com/Stability-AI/stablelm.
- Clark, E. et al. (2023). Seahorse: A multilingual benchmark for factual correctness in summarization. ✅arXiv preprint arXiv:2306.05125.
- Fabbri, A. R. et al. (2021). Summeval: Re-evaluating summarization evaluation. ✅Transactions of the Association for Computational Linguistics, 9, 408–430.
- Fernandes, P. et al. (2023). AutoMQM: Automatic machine translation evaluation with large language models. In ✅Proceedings of the 17th Conference of the European Association for Machine Translation.
- Freitag, M. et al. (2021). Results of the WMT21 Metrics Shared Task: Evaluating metrics with explanations. In ✅Proceedings of the Sixth Conference on Machine Translation.
- Freitag, M. et al. (2022). Findings of the WMT22 Shared Task on Machine Translation Quality Estimation. In ✅Proceedings of the Seventh Conference on Machine Translation.
- Freitag, M. et al. (2023). Findings of the WMT23 Shared Task on Machine Translation Quality Estimation. In ✅Proceedings of the Eighth Conference on Machine Translation.
- Fu, Y. et al. (2023). From words to programs: Exploring the potential of large language models for abstract semantic parsing. ✅arXiv preprint arXiv:2305.17770.
- Gao, L. et al. (2024a). A survey of large language model based automatic metrics for natural language generation. ✅arXiv preprint arXiv:2404.14012.
- Gao, L. et al. (2024b). Retrieval augmentation for large language model based evaluation metrics. ✅arXiv preprint arXiv:2405.12504.
- Iyer, S. et al. (2022). OPT: Open pre-trained transformer language models. ✅arXiv preprint arXiv:2205.01068.
- Khattab, O. et al. (2023). DSPy: Towards general-purpose symbolic programming for composable program synthesis. ✅arXiv preprint arXiv:2305.15956.
- Kocmi, T. and Federmann, C. (2023a). Large language models are not fair judges: Exploring the intrinsic bias of dataset average as a metric. ✅arXiv preprint arXiv:2305.13400.
- Kocmi, T. and Federmann, C. (2023b). On the evaluation of machine translation systems trained with controlled simplification. In ✅Proceedings of the 17th Conference of the European Association for Machine Translation.
- Kojima, T. et al. (2022). Large language models are zero-shot reasoners. ✅arXiv preprint arXiv:2205.11916.
- Köpf, B. et al. (2023). OpenAssistant Conversations—democratizing large language model alignment. ✅arXiv preprint arXiv:2304.07327.
- Lee, H. Y. et al. (2023a). PLATYPUS: Quick, cheap, and accurate fine-tuning of large language models. ✅arXiv preprint arXiv:2310.11307.
- Leidinger, T. et al. (2023). Prompt surveillance: Tracking prompts that expose weaknesses in large language models. ✅arXiv preprint arXiv:2302.12177.
- Leiter, C. et al. (2023). Findings of the WMT 2023 Shared Task on Evaluating the Evaluation of Machine Translation and Summarization. In ✅Proceedings of the Eighth Conference on Machine Translation.
- Li, H. et al. (2023). Exploring the impact of emotion on large language models. ✅arXiv preprint arXiv:2305.14725.
- Li, S. et al. (2024a). Unbabel』s submission to the WMT23 metrics shared task: Prompting large language models for machine translation quality estimation. In ✅Proceedings of the Eighth Conference on Machine Translation.
- Li, Y. et al. (2024b). A survey of automatic metrics based on large language models for natural language generation. ✅arXiv preprint arXiv:2404.00774.
- Liu, P. et al. (2023a). Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ✅ACM Computing Surveys, 55(9), 1–35.