

作者:Megan Ayers, Luke Sanford, Margaret E. Roberts, Eddie Yang✅
所属机构:1耶鲁大学, 2加州大学圣地亚哥分校
摘要
在社会科学中,实验方法常用于估计文本对人类评价的影响。然而,实验环境中的研究人员通常只限于测试少量预先指定的文本处理方法。这些处理方法往往是主观选择的,可能无效或缺乏外部效度。近年来,对未结构化文本进行挖掘以寻找因果影响特征的努力不断增加,但这些模型主要集中于文本的主题或特定词汇,而这些可能并不是效果的机制。我们将这些努力与自然语言处理(NLP)可解释性技术相结合,提出了一种方法,利用卷积神经网络(CNN)灵活地发现预测人类对文本反应的相似文本短语簇。在实验环境中,该方法可以在某些假设下识别文本处理及其效果。我们将该方法应用于两个数据集,第一个数据集验证了模型检测已知导致结果的短语的能力,第二个数据集展示了其灵活发现具有不同文本结构的文本处理的能力。在两种情况下,模型学习到的文本处理比基准方法更多样化,并且这些文本特征在预测结果方面定量上达到或超过了基准方法的能力。
引言
文本对许多领域的结果和决策产生影响。例如,研究人员已经调查了竞选信息对投票的影响(Arceneaux 和 Nickerson,2010),帖子内容对审查的影响(King 等人,2014),临床笔记对诊断和治疗的影响(Sheikhalishahi 等人,2019),以及书面简介对公民身份决定的影响(Hainmueller 和 Hangartner,2013)。大多数估计文本对人类评价影响的实验方法是随机分配一些受试者到由研究人员事先选择的少量处理文本。这些处理方法通常是主观选择的,可能无效或缺乏外部效度。最近的计算社会科学文献试图从未结构化文本中发现对感兴趣结果有影响的处理方法(Fong 和 Grimmer,2016;Pryzant 等人,2018)。
在这项工作中,我们将这些使用文本处理进行因果推断的努力与可解释机器学习领域相结合(Jacovi 等人,2018;Alvarez Melis 和 Jaakkola,2018)。以文本为处理方法的因果推断方法旨在识别对结果产生因果影响的低维文本特征表示。我们引入了一种新的应用,结合了上下文化的词嵌入、卷积神经网络(CNN)和可解释性方法,以检测和解释这些潜在的文本表示。与之前识别文本处理的方法不同,这些学习到的表示可以在长度和结构上变化,不受限于表示文档级别的一组主题或特定词汇。我们将该方法应用于两个数据集:微博上的社交媒体帖子,结果是帖子是否被审查,以及提交给消费者金融保护局的投诉,结果是投诉者是否及时收到回应。在这两种情况下,我们的方法提取了质量上不同的处理,并且在定量性能指标上达到或超过了基准方法。
相关工作
计算社会科学与因果推断
之前的工作生成了方法来同时发现处理并估计其效果(Fong 和 Grimmer,2016;Pryzant 等人,2018;Egami 等人,2018;Fong 和 Grimmer,2021;Feder 等人,2022)。这些模型通常集中于估计主题或单词作为处理。Fong 和 Grimmer(2016)应用监督的印度自助餐过程,既发现特征(主题),又在随机对照试验(RCT)设置中估计其对结果的影响。Pryzant 等人(2018)使用 n-gram 特征代替主题,并使用一种从网络权重中提取特征重要性的方法构建了神经架构。我们的模型扩展了这项工作,允许将一般相似的短语组(而不是主题或唯一单词)识别为处理。我们预计我们的方法在结果可能由灵活表达的概念(例如,可以用可互换同义词传达的情感)而非特定单词或文档的全部主题内容引起的情况下效果特别好。
可解释的 NLP
许多方法已经被提出用于解释和解释 NLP 模型,以及这些方法的元评估(Lei 等人,2016;Alvarez Melis 和 Jaakkola,2018;Rajagopal 等人,2021;Alangari 等人,2023;Crothers 等人,2023;Lyu 等人,2023)。这些方法大多集中于解释和解释个体样本级别的预测。相比之下,我们的方法旨在学习和解释在语料库级别发生的更广泛的模式。在这方面,Rajagopal 等人(2021)要求他们的模型使用「全局」概念解释预测,Jacovi 等人(2018)专门解释 CNN 学习到的潜在特征,最接近我们的工作。个别标记对人类来说不可解释或单独有说服力,因此如 Alvarez Melis 和 Jaakkola(2018)一样,我们要求网络在表示学习组件之后有一个可解释的最终层。与试图理解网络做出预测的原因不同,我们寻求的是科学家可以在后续实验中测试其效果的有影响力的语料库级特征的表示。例如,如果模型识别出日历日期的存在是确定及时回应投诉的全球性有影响力特征,研究人员可能设计两个文本,仅通过包括日期进行区分,并在受控实验中比较其效果。
其他现有的 NLP 技术可以适应这种方法。例如,说服性和非说服性文本之间的差异(Zhong 等人,2022)可以用来识别有说服力的概念。虽然任何能够学习有影响力文本特征的语料库级低维表示的方法都可以用于识别文本处理,但关键挑战是能够捕捉复杂的特征表示,同时保持人类可解释。这需要在表示学习中具备复杂性,但在理解所学的文本处理的效果的估计中保持清晰。在实验中,我们提出的模型有效地实现了这种平衡。
从潜在表示中提取有影响力的文本
我们的目标是提取代表潜在的、可概括的处理的短语簇,这些处理会影响特定结果。为此,我们想象 N 个文本(Ti)被随机分配到一个过程中,通过该过程它们被映射到一个结果(Yi)。让 i 也索引评估文本 i 的个体。我们寻求识别和估计这些文本的 m 维潜在表示(Zi)的效果,该表示总结了可能在反复实验中影响结果的短语或概念簇。我们将 Zi 称为文本 i 的「文本处理」。例如,Zi 的每个元素可以表示某个短语或语法结构的存在或不存在,Zi ∈ {0, 1}m。Zi 也可以包含表示连续文本特征的实值元素,如与某个词汇或概念一致的相似性。
为了模拟一个顺序实验设置,我们遵循 Egami 等人(2018)的做法,将样本分为训练集和测试集。我们首先训练模型,在训练集内使用交叉验证进行调整和模型选择。然后,我们使用测试数据集解释发现的潜在文本处理,并在附加假设下估计其对结果的影响。我们的主要贡献在于第一阶段:在文本数据和文本处理(Zi)之间发现映射的 CNN 模型的新颖使用。
Fong 和 Grimmer(2016,2021)概述了在处理为二进制的情况下,该一般过程识别文本处理对结果的因果效应的条件。他们假设:1)个体的处理仅取决于其分配的文本,2)任何非文本特征或不被模型捕获的潜在文本特征对评估者的反应(Yi)的影响是独立于模型捕获的潜在特征的,3)在给定未测量的文本特征的情况下,每个评估者接收任何可能的文本处理的概率是非零的,4)文本是随机分配的,5)潜在处理不是完全共线的。如果这些假设成立,我们的模型可以识别发现的潜在特征的处理效应。在连续处理变量的情况下,与连续处理变量的线性建模假设一起,可以使用线性回归估计这些效应。然而,由于很难评估这些假设是否成立—特别是假设2,我们建议在可能的情况下,实践者使用我们的方法建议在受控实验中研究的处理。
方法论
我们建议利用 CNN 的结构来识别有影响力的文本处理。卷积层中的滤波器将文本短语投影到低维表示空间,然后在每个样本的所有短语中进行最大池化,以预测结果(图1)。通过训练模型生成预测的最大池化表示,激励滤波器检测有影响力的 n-gram 模式(Jacovi 等人,2018)。这些模式可以对应于特定的关键词或具有相似词汇、语法结构或语调的关键词簇。例如,研究人员可以测试这些模式在文本中出现时对结果的影响。
上下文编码器
我们使用预训练的 BERT 模型(Devlin 等人,2019)对输入文本样本(Ti)进行标记,并获得上下文相关的词嵌入。我们将这些嵌入表示为 ei,j ∈ RD,其中 i 索引每个文本样本,j 索引标记(ui,j),D 表示嵌入维度。考虑到社会科学家的可访问性,我们使用了缩小版模型(Jiao 等人,2020),并且没有进行微调。对于计算预算较少的研究人员来说,使用更大或更复杂的模型并/或在其结果上微调这些模型可能会发现模型性能有所提高。任何提供文本嵌入的模型都可以替代 BERT。我们在创建训练-测试划分之前执行嵌入步骤,但选择微调其嵌入模型的研究人员应逆转这些步骤,以便仅在训练集上进行微调和训练。
模型架构
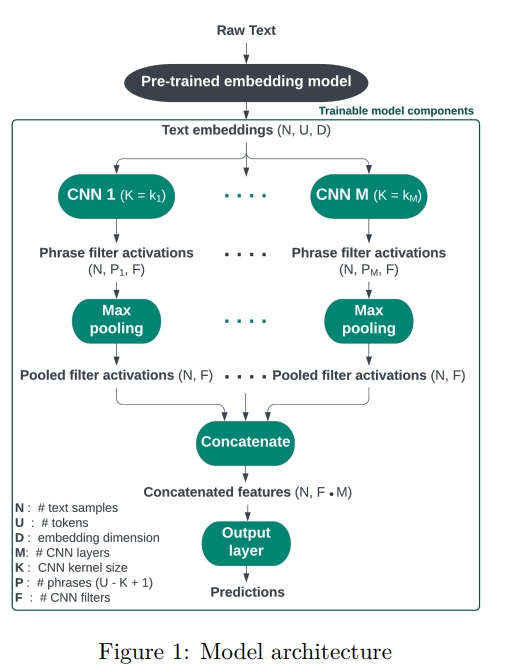
输入的文本嵌入序列 {ei,j}j 传递给一维卷积层 C. ��或者传递给平行的 M 个这种层(Cl),每个层具有灵活的核大小 Kl 和 F 个滤波器。唯一核大小的平行卷积层的数量决定了平行卷积层的数量。更高数量的滤波器 F 对应于学习更多潜在的文本特征。在我们的实现中,所有卷积层学习相同数量的滤波器。核大小 K 决定了滤波器窗口的大小,即每个卷积层考虑的短语长度。包括多种核大小的滤波器允许模型捕捉不同长度的模式。对于层 C 中核大小为 K = 5 的滤波器 f,卷积操作在输入文本的五个标记短语 pi,1, …, pi,P ∈ RK×D 上生成新特征 ai,f = g(Wf · pi + b),其中 Wf 和 b 是滤波器 f 的学习权重和偏差,g 是 sigmoid 激活函数。我们将这些特征称为「滤波器激活」,ai,f ∈ RP。通过最大池化层对每个文本样本进行汇总,仅保留每个滤波器在文本短语中的最高激活。然后将每个滤波器的最大池化激活 apooled✅
i,f ∈ R 连接在平行卷积层之间。然后将连接的最大池化激活传递到最终的全连接层。最终层的激活 ˆYi 对应于模型预测。
训练
模型使用 Adam 优化器(Kingma 和 Ba,2017)训练,损失函数如下:
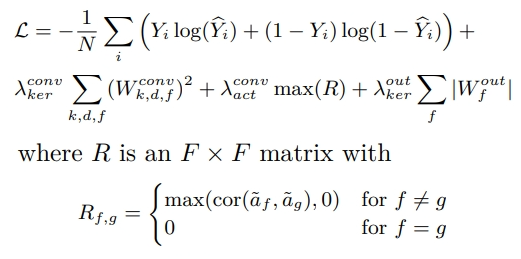
[
L = – \frac{1}{N} \sum_i \left( Y_i \log(\hat{Y_i}) + (1 – Y_i) \log(1 – \hat{Y_i}) \right) + \lambda_{\text{conv}} \sum_{\text{ker},k,d,f} (W_{\text{conv}}^{\text{ker}}){k,d,f}^2 + \lambda{\text{conv}} \sum_{\text{act}} \max(R. + \lambda_{\text{out}} \sum_{\text{ker}} |W_{\text{out}}^{\text{ker}}|✅
]
其中 R 是一个 F x F 矩阵,定义如下:
[
R_{f,g} = \begin{cases}
\max(\text{cor}(\tilde{a_f}, \tilde{a_g}), 0) & \text{for } f \neq g \
0 & \text{for } f = g
\end{cases}
]
其中 (\tilde{a_f} \in \mathbb{R}^{N \cdot P}) 表示滤波器 f 在所有 N 样本的 P 短语中的激活向量。第一个项是相对于模型预测的二进制交叉熵损失。我们选择了这个全局损失,因为在我们这里展示的两个应用中,结果都是二进制的,但可以很容易地替换为 RMSE 或者更适合连续结果的其他损失。第二项是应用于卷积层权重 (W_{\text{conv}} \in \mathbb{R}^{K \times D \times F}) 的 L2 正则化惩罚。第三项表示一个活动正则化,惩罚两个滤波器激活之间的最大非负相关性。这惩罚了学习冗余滤波器的模型(通过高相关性激活测量),鼓励卷积层识别更多不同的文本特征(附录 A. ��图 4)。对于 M > 1 的模型,第二和第三项在每个卷积层的和中重复。第四项是应用于最终全连接层权重 (W_{\text{out}} \in \mathbb{R}^{F \cdot M}) 的 L1 正则化惩罚。每个惩罚的强度由 (\lambda_{\text{conv}}, \lambda_{\text{act}}) 和 (\lambda_{\text{out}}) 控制。✅
这些惩罚强度和其他超参数是通过使用训练集的五折交叉验证程序确定的。由于这些模型的动机主要是解释学习到的特征,而不是预测性能,模型选择比简单地选择最高准确率的参数设置更为主观。我们根据准确率、特征冗余的相关性程度以及学习到的「有用」滤波器数量的组合选择模型。应用中选择的模型参数设置在附录中报告。然后使用整个训练集重新训练最终选择的模型,随机抽取的 20% 作为验证集,并使用未见的测试集进行评估。
识别和测试有影响力的文本特征
为了解释模型学习到的潜在表示并发现每个文本的文本处理(Zi),我们利用了三个模型组件:
- 每个滤波器 f 的每个文本样本短语的滤波器激活(ai,f);
- 输出层权重(W out ∈ RF ·M. ��;✅
- 输入文本样本(Ti)。
滤波器激活表示每个短语与每个滤波器学习到的表示的强度。为了便于解释并为每个滤波器分配手动标签,我们检查每个滤波器的最大激活短语。最终层权重确定每个文本表示如何对最终结果预测做出贡献。最后,原始输入文本样本为高激活的短语提供上下文。由于文本嵌入是上下文相关的,每个短语的嵌入包含比单个标记更多的信息,这些标记缺乏整个样本的上下文。然而,由于文本嵌入维度难以解释,人类读者在阅读整个样本时分配给短语的上下文无法确认与编码的上下文一致。
评估方法
我们通过将模型与两种基准方法进行比较来评估我们的模型。第一种是 Fong 和 Grimmer(2016)提出的方法,该方法使用主题建模方法发现和解释潜在的文本处理。我们将这种方法缩写为 F&G. ��第二种是对语料库中的 n-gram 词汇进行正则化逻辑回归,我们将其缩写为 RLR。通过评估线性模型使用每种方法识别的文本处理预测结果变量的调整 R 平方,以及评估这些线性模型在样本外文本上的均方误差,进行定量比较。我们通过计算数据的 1000 个自助样本的指标,使这些比较对采样变异性具有鲁棒性,固定训练好的模型(因此也固定了学习到的潜在特征)。为了更好地了解我们提出的模型和基准模型的训练过程的稳定性,我们重复了这个过程,但另外在训练数据的 150 个自助样本上重新训练模型(固定调整的参数设置)。通过评估学习到的文本特征的可解释性和多样性进行定性比较。在审查应用中,已知哪些短语导致审查的真实信息使我们能够通过其恢复已知因果效应的文本处理的能力来比较方法。基准方法的实现细节和完整的解释结果包括在附录 B 中。✅
实验
为了充分展示我们的方法能够实现的定性和实质性结果,我们集中在两个数据集上进行实验。第一个数据集因为稀有的真实信息而被选中,第二个数据集因为其在相关研究中的使用而被选中,以探索有影响力的文本特征可能表现出复杂和多样结构的设定。我们采用深度优先而不是广度优先的方法,但未来的工作应在更大范围的数据集上评估这种方法。虽然该方法可以推广到任何文本被认为会导致结果的数据集,但具有关于这种关系的真实信息的数据集是理想的(尽管罕见),因为它们可以展示成功识别因果关系和效应。
微博帖子审查
数据集和设置
对于我们的第一个应用,我们使用了28,386条来自Weibo-Cov数据集的微博帖子(Hu等人,2020)。这些是关于COVID的社交媒体帖子,发布于2020年2月的微博上。为了获取每个帖子的审查标签,我们使用了来自百度的内容审核API。该API是一个分类器,为每个帖子返回审查的概率。API仅在社交媒体帖子包含在百度黑名单上的单词或短语时返回概率1。由于API还返回标记的关键词和短语,这使我们能够验证我们的模型是否可以恢复导致审查的关键词和短语。
我们训练我们的模型来预测帖子是否被API标记为审查概率为1。尽管这个结果不是由直接的人类决策决定的,但我们可以将黑名单视为一个完美实现一组人类定义偏好的决策者(这些偏好可能或可能不代表更广泛的审查政策)。为了对这些文本进行标记和嵌入,我们使用了由哈尔滨工业大学和iFLYTEK联合实验室提供的预训练BERT中文语言模型MiniRBT-h288(Yao等人,2023)。该模型具有288维的嵌入维度和12.3M参数。我们使用BERT模型最后一个隐藏状态的嵌入作为我们模型架构的输入特征。数据集中帖子示例、其审查概率及其审查词(如适用)及其英文翻译见附录A表3。附录A表4显示了所有审查概率为1的样本中前10个审查词、其翻译及对应的审查样本比例。
结果
训练好的模型在测试集上获得了0.87的准确率。在模型重复训练在重新采样数据并重新评估的迭代中,模型分类准确率相对稳定(值在[0.84, 0.88]之间,平均为0.86)。这表明模型学习到了有用的表示,这些表示可以预测该时期的微博帖子是否会被审查。基于参数调优结果,该模型由两个卷积层组成,核大小分别设置为5和7个中文字符。我们在表1中重点解释了最相关的表示,所有表示的解释见附录A表7。我们发现,模型清晰地识别出了两种最常被审查的短语,「武汉病毒」(23.9%的被审查帖子)和「国家危机」(4.9%的被审查帖子),它们在模型的第一个和第二个滤波器中被识别出来。最大池化激活对这些滤波器的最大贡献见于表中的W out列。滤波器3和9的最高激活短语共同具有另外两个已知的审查短语,「省委书记」和「新天地教会」,滤波器10的最高激活短语完全集中在同一个短语上,该短语涉及第五个已知的审查短语「蒋超良」。完整的表示解释集显示了滤波器学习到的关键词存在某种冗余。在其他设置中,它们在句子结构和上下文中的差异可能具有启发性,尽管在这种情况下,已知这些短语的包含单独影响结果。作为概念验证,我们包括了通过对测试样本的最大池化滤波器激活进行回归获得的效应估计,尽管这种设置不符合典型的实验设计。尽管估计效应的大小与输出层权重不同(很大程度上因为输出层权重对应于sigmoid而不是线性激活),但它们在哪些文本处理被发现对审查最有影响方面相对一致。
模型验证
我们发现这种方法成功恢复了导致最多帖子被审查的短语。在没有审查理由的情况下,我们相信研究人员可以使用这个模型确定至少五种最常见的审查短语。相比之下,我们发现F&G方法学习到的主题与任何最常见的审查短语都不清晰对齐(附录B. ��表12)。逻辑回归模型选择的n-gram词组部分对应于三个常见的审查短语:「武汉病毒」,「蒋超良」和「省委书记」(附录B:表13)。我们的模型在图2报告的两个指标上都优于基准方法,这表明我们模型学习到的特征解释审查结果的变异性显著更多,并且在预测能力方面比基准方法学习到的主题和关键词更好。✅
消费者金融保护局投诉响应
数据集和设置
对于我们的第二个应用,我们使用了Egami等人(2018)从2015年3月到2016年2月提交给消费者金融保护局(CFPB)的54,816个消费者投诉叙述的数据集。结果变量表示投诉者是否及时收到了公司的回应。由于结果变量严重不平衡,我们继续使用一个包含及时响应(5136个及时响应和1712个非及时响应)的子样本,并结合一个类别加权的损失函数。为了对投诉文本进行标记和嵌入,我们使用了由Google Research训练的预训练BERT英文语言模型bert-tiny(Turc等人,2019;Bhargava等人,2021)。该模型具有128维的嵌入维度和4M参数。
结果
训练好的模型在测试集上获得了0.76的准确率和0.33的F1分数。在模型重复训练在重新采样数据并重新评估的迭代中,模型分类准确率相对一致,值在[0.72, 0.79]之间,平均为0.75。F1分数观察到较大的变化,值在[0.12, 0.44]之间,平均为0.31。考虑到使用的数据集的有限规模、类别不平衡和这个学习任务的相对复杂性,模型获得较低的性能并不意外,但学习到的表示仍提供了关于数据集中文本处理的有意义的见解。
表2总结了模型学习到的前8个表示(根据最终层权重)的解释。所有滤波器的解释见附录A表10。该模型具有一个卷积层,核大小设置为5个标记,这是通过参数调优选择的。我们推断,提到信用纠纷和银行业务流程可能与及时响应正相关,而提到试图收债、电话或语音邮件、以前的互动或发薪日贷款可能与及时响应负相关。除了这些较广泛的主题之外,我们还发现,在描述争议行动时使用不定式动词可能会增加及时响应的可能性,而使用缩略形式可能会产生相反的效果。表2还包括测试集标签与文本的最大池化滤波器激活进行回归的效应估计。同样,我们认为这些效应的因果解释假设不太可能成立,但估计仍可以作为研究人员探索后续实验的文本处理的有用工具。
模型评估
在这个应用中,我们无法访问投诉收到或未收到及时响应的真实原因,并且设想各种文本特征可能会影响这个结果。两种基准方法都检测到某些金融主题似乎与及时响应相关(附录B. ��表15、16)。特别是,所有模型的结果都表明提到收债与及时响应负相关,而提到银行业务流程和信用问题与及时响应正相关,尽管估计的大小有所不同。除了这些共享的主题之外,我们的模型独特地学习到预测结果的语法文本特征。尽管所有模型在其识别的文本特征的样本外预测能力方面表现相似,我们的模型结果在R2 adj值方面比基准方法略高(图3)。✅
结论
参考文献
- Arceneaux, K. , & Nickerson, D. W. (2010). Comparing negative and positive campaign messages: Evidence from two field experiments. American Politics Research, 38(1), 54-83.✅
- King, G. , Pan, J., & Roberts, M. E. (2014). Reverse-engineering censorship in China: Randomized experimentation and participant observation. Science, 345(6199), 1-10.✅
- Sheikhalishahi, S. , Miotto, R., & Weng, C. (2019). Natural language processing of clinical notes on chronic diseases: Systematic review. JMIR Medical Informatics, 7(2), e12239.✅
- Hainmueller, J. , & Hangartner, D. (2013). Who gets a Swiss passport? A natural experiment in immigrant discrimination. American Political Science Review, 107(1), 159-187.✅
- Fong, C. , & Grimmer, J. (2016). Discovery of treatments from text corpora. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1608-1617.✅
- Pryzant, R. , Diaz, M., & Liu, Y. (2018). Deconfounded lexicon induction for interpretable social science. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 1686-1695.✅
- Jacovi, A. , & Goldberg, Y. (2018). Towards faithfully interpretable NLP systems: How should we define and evaluate faithfulness? In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 4198-4208.✅
- Alvarez Melis, D. , & Jaakkola, T. S. (2018). Towards robust interpretability with self-explaining neural networks. In Advances in Neural Information Processing Systems, 7775-7784.✅
- Rajagopal, D. , & Mooney, R. (2021). Global explanations of neural networks: Mapping the landscape. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 124-131.✅
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在社会科学研究中,使用计算模型来发现和评估文本数据对人类评价影响的特征。具体来说,它关注以下几个方面:
- 文本对人类评价的影响:研究者们一直在探索文本(如竞选信息、社交媒体帖子、临床笔记等)如何影响人们的决策和评价。
- 实验方法的局限性:传统实验方法通常限制在测试研究者预先指定的少量文本处理(text treatments),这可能带来主观性,并且可能缺乏外部有效性。
- 文本特征的自动发现:近年来,计算社会科学领域的研究试图从未结构化的文本中挖掘出影响结果的特征,但这些模型主要集中在文本的主题或特定词汇上,这可能并不总是影响效果的机制。
- NLP解释性技术的结合:论文提出了一种新的方法,结合了自然语言处理(NLP)的解释性技术,使用卷积神经网络(CNN)来灵活地发现预测人类对文本反应的文本短语集群。
- 因果推断与文本处理:论文还探讨了如何使用文本作为处理手段来进行因果推断,目的是识别出影响结果的文本特征的低维表示。
- 模型的灵活性和多样性:与以往的方法相比,论文提出的方法能够学习到不同长度和结构的文本表示,不受文档级别的主题集或特定词汇集的限制。
- 实验设置中的应用:论文提出的方法在实验设置中可以识别文本处理及其在一定假设条件下的效果,这为研究者提供了一种新的工具,用于在后续的确认性分析中发现和测试文本处理。
总的来说,这篇论文试图通过结合计算社会科学和可解释机器学习的方法,提供一个能够自动发现并解释文本中影响人类评价特征的模型,以提高研究的客观性和外部有效性。
Q: 有哪些相关研究?
A: 论文中提到了以下几类相关研究:
- 计算社会科学和因果推断:先前的研究集中在同时发现处理方法和估计其效果的方法。例如,Fong和Grimmer (2016) 应用监督的印度自助餐过程在随机对照试验(RCT)设置中发现特征(主题)并估计它们对结果的影响。Pryzant等人 (2018) 使用n-gram特征而不是主题,并使用一种神经架构来从网络权重中提取特征重要性。
- 可解释的NLP:许多方法被提出来解释和解释NLP模型,以及这些方法的元评估。这些方法主要集中在在个体样本层面上解释和理解预测。与此相反,本文提出的方法旨在学习和解释在语料库层面发生的更广泛的模式。
- 文本特征的发现和效果估计:以往的工作通常集中在估计主题或单个词作为处理的效果。例如,Fong和Grimmer (2016) 将监督的印度自助餐过程应用于发现特征(主题)并估计它们在RCT设置中对结果的影响。
- 文本的低维表示:因果推断方法旨在识别文本特征的低维表示,这些特征在因果上影响结果。本文通过使用上下文化的词嵌入、卷积神经网络(CNNs)和解释性方法,对这一设置进行了创新性的应用。
- 文本处理的模拟实验:本文提出的方法和它建立在之上的方法试图模拟针对特定潜在文本特征的因果效应的实验。然而,只有在满足强假设的情况下,才能直接识别效果。
- 文本特征的解释性:本文提出的方法使用解释性方法灵活地发现文本中的潜在处理方法。这与主要关注提高黑盒预测模型解释性的NLP工作形成对比。
- 文本特征的因果效应估计:尽管本文提出的方法和它建立的方法试图模拟实验以针对特定潜在文本特征的因果效应,但效果只能在满足强假设的情况下直接识别。
这些相关研究为本文提出的新方法提供了理论基础和对比,展示了在文本特征发现和因果推断方面的最新进展。
Q: 论文如何解决这个问题?
A: 论文通过提出一种基于卷积神经网络(CNN)的方法来解决发现和评估文本数据对人类评价影响的特征的问题。具体的解决步骤包括:
- 使用预训练的BERT模型:利用预训练的BERT模型对输入文本进行分词并获取上下文相关的词嵌入。
- 模型架构设计:设计一个包含一维卷积层的神经网络模型,这些卷积层可以并行工作,每个层具有不同的内核大小和数量,以便捕获不同长度的文本模式。
- 最大池化操作:通过最大池化层汇总每个文本样本中每个卷积核的最高激活值,以预测结果。
- 训练模型:使用Adam优化器和特定的损失函数来训练模型,包括二元交叉熵损失和正则化项,以鼓励模型学习到不同的文本特征。
- 解释模型学习到的表示:通过分析每个卷积核的激活情况,以及它们在最终预测中的贡献,来解释模型学习到的文本特征。
- 文本特征的发现和测试:利用模型的组件(如滤波器激活、输出层权重和原始文本样本)来识别和测试影响特定结果的文本特征。
- 评估方法:通过与两种基准方法(Fong和Grimmer (2016) 的主题建模方法和基于词汇表的n-gram的正则化逻辑回归)进行比较,量化评估模型预测结果的能力。
- 实验验证:在两个数据集上应用该方法,一个是Weibo社交媒体帖子的审查数据集,另一个是消费者金融保护局(CFPB)的投诉数据集,以展示模型发现文本处理的能力和与基准方法相比的性能。
- 结果解释和应用:根据模型结果,研究人员可以设计后续的实验来测试模型识别的文本特征,或者直接在强假设条件下估计文本处理的因果效应。
通过这种方法,论文提供了一种新的工具,使研究人员能够在不同的文本数据集中发现和评估影响人类评价的文本特征,同时保持了结果的可解释性。
Q: 论文做了哪些实验?
A: 论文进行了两个主要的实验来验证所提出方法的有效性:
- Weibo帖子审查实验:
- 数据集:使用了来自Weibo-Cov数据集的28,386条关于COVID-19主题的社交媒体帖子。
- 实验目的:预测帖子是否会被审查,以及识别导致审查的文本特征。
- 实验方法:使用百度的内容审查API来获取每个帖子的审查标签,并训练CNN模型来预测审查结果。
- 结果:模型能够以0.87的准确率预测帖子是否会被审查,并成功识别出与审查相关的关键词和短语。
- 消费者金融保护局(CFPB)投诉响应实验:
- 数据集:使用了54,816条提交给CFPB的消费者投诉叙述,时间范围从2015年3月到2016年2月。
- 实验目的:预测投诉者是否从被投诉公司那里获得了及时的回应。
- 实验方法:由于结果变量的严重不平衡,研究者选择了一个子样本,并使用类加权损失函数来训练CNN模型。
- 结果:模型在测试集上获得了0.76的准确率和0.33的F1分数,揭示了与及时回应相关的文本特征。
在这两个实验中,论文的方法不仅能够预测结果,还能够通过模型的解释性组件来识别和解释影响结果的文本特征。这些特征包括关键词、短语、语法结构等,它们在不同的实验设置中表现出了不同的影响力。
此外,论文还与两种基准方法进行了比较:
- Fong和Grimmer (2016) 提出的方法,使用主题建模来发现和解释潜在的文本处理。
- 正则化逻辑回归(RLR),使用词汇表中的n-gram作为特征。
通过这些实验,论文展示了其方法在不同数据集上的应用能力,并与现有方法进行了定量和定性的比较。
Q: 有什么可以进一步探索的点?
A: 论文在第6节「Conclusion」和第7节「Limitations」中提出了一些可以进一步探索的点,以下是几个关键的研究方向:
- 模型的可解释性评估:进行更严格的人类可解释性评估,以比较所提出方法与现有基准方法在定性方面的差异。
- 模型性能与计算成本的权衡:研究模型性能提升与计算成本(时间和内存)之间的权衡,特别是在使用更大或更高级的模型时。
- 实验成本与可解释性之间的权衡:探索在直接测试潜在文本处理与设计后续实验以测试明确文本特征之间的权衡。
- 模型不确定性的纳入:研究如何将识别潜在文本处理过程中的模型不确定性纳入因果效应估计。
- 实验文本的设计:研究如何设计实验文本以隔离感兴趣的处理,以及如何克服在不直接影响文本其他部分的情况下操纵特定文本特征的挑战。
- 跨模型运行的稳定性评估:开发方法来评估在不同模型运行中识别潜在文本处理的稳定性。
- 使用不同的BERT模型:研究使用不同大小、经过微调或更先进的BERT模型对模型性能的影响。
- 跨数据集的计算成本比较:在更广泛的数据集范围内比较所提出方法与现有方法的计算成本。
- 伦理和滥用风险:进一步探讨模型可能被滥用以提高操纵能力的风险,并权衡这些风险与开源模型的潜在益处。
- 模型的泛化能力:评估模型在不同类型的文本和不同领域中的泛化能力。
- 模型的可扩展性:研究模型在处理大规模数据集时的可扩展性和效率。
- 模型的健壮性:评估模型对于不同类型的噪声和异常值的健壮性。
这些点提供了对现有工作深入理解和未来研究方向的基础。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
- 问题背景:论文讨论了在社会科学中,文本如何影响人类评价和决策,并指出了传统实验方法在测试文本影响时的局限性。
- 研究目标:提出了一种新的方法,使用卷积神经网络(CNN)结合自然语言处理(NLP)的解释性技术,来发现和解释预测人类对文本反应的文本短语集群。
- 方法论:
- 使用预训练的BERT模型来获取文本的上下文相关嵌入。
- 设计了一种CNN模型架构,通过一维卷积层和最大池化层来捕捉文本中的模式。
- 通过训练模型来学习文本数据和文本处理(潜在的文本特征)之间的映射。
- 实验设计:
- 在Weibo帖子审查数据集上进行实验,验证模型预测帖子是否会被审查的能力。
- 在消费者金融保护局(CFPB)的投诉数据集上进行实验,预测消费者是否获得及时反馈。
- 结果分析:
- 模型在两个数据集上均取得了良好的预测性能,并能够识别出与结果相关的文本特征。
- 通过与现有方法的比较,展示了所提方法在解释性和预测性能方面的优势。
- 方法贡献:
- 提供了一种新的视角,将计算社会科学中的文本处理与可解释机器学习相结合。
- 允许研究人员发现文本中的潜在处理方法,并在后续实验中进行测试。
- 局限性和未来工作:
- 讨论了使用小BERT模型的局限性,以及未来可能的改进方向,如模型的可解释性评估、计算成本、实验设计等。
- 伦理考量:论文最后讨论了模型可能被滥用的风险,以及对社会有益应用的潜力。
整体而言,这篇论文提出了一种结合了深度学习和解释性NLP的方法,用于分析文本数据对人类行为的影响,并在两个不同的数据集上验证了其有效性。