🍃 引言
自20世纪以来,语言一直是人类文明进步的基石。无论是通过诗歌表达情感,还是通过学术论文传递科学发现,语言是我们理解世界和彼此的桥梁。然而,机器却没有这种天生的语言能力。如何让机器能够理解、处理并生成像人类一样的语言?这是我们在自然语言处理(NLP)领域不断努力的方向。
在这一过程中,大型语言模型(LLMs)逐渐成为了语言处理的主角。它们不仅能生成几乎逼真的文本,还能在各种任务中表现出色,比如机器翻译、对话系统和文本分类。正如我们所见,OpenAI的GPT系列、谷歌的BERT和T5模型,以及Meta的RoBERTa,这些模型已经在全球范围内掀起了AI革命。然而,随着模型的参数规模不断攀升,我们也面临着信息过载的挑战——成千上万的LLM相关论文让研究人员应接不暇。
那么,如何有效提取和组织这些LLM的关键信息,帮助研究人员更快地理解最新进展呢?这正是本文提出的LLM-Card系统所要解决的问题。通过命名实体识别(NER)和关系抽取(RE)的方法,LLM-Card自动从论文中提取模型名称、许可证类型和应用场景等信息,从而构建出每篇论文的「模型卡片」。
🔍 研究背景
大型语言模型的崛起
机器学习和深度学习的进步使得语言模型从基于规则的系统转向了基于神经网络的模型。随着Transformer架构的引入,LLM的性能得到了质的飞跃。Transformer的自注意力机制使得模型能够并行处理文本中的所有词汇,从而提高了处理效率和扩展性。
特别是,谷歌的BERT模型通过其双向编码器架构,极大提高了文本分类和信息检索任务的准确性。紧随其后的是OpenAI的GPT系列,尤其是GPT-3和GPT-4,它们展示了LLM在文本生成和对话系统中的巨大潜力。
然而,随着模型规模的增加,一些新的挑战也随之而来,比如模型的可解释性、安全性以及伦理问题。
🧠 方法论
数据构建与处理
为了从学术论文中自动提取LLM的相关信息,我们首先需要构建一个数据集。研究人员从106篇学术论文中提取了11,051个句子,并通过词典查找和人工筛选,最终选定了具有明确模型-许可证和模型-应用关系的句子(分别为129句和106句)。这些数据将被用于训练和评估LLM-Card系统。
依存树构建
依存树是一种常用的句法结构表示方法,它展示了句子中词汇之间的依赖关系。通过依存树,我们能够解析出句子中的主谓宾结构,从而提取出模型名称与其应用场景或许可证之间的关系。
例如,在「BERT was released under the Apache licence 2.0」这句话中,「BERT」是主语,「released」是谓语,而「under the Apache licence 2.0」是表示许可证的介词短语。
规则制定
为了能够处理不同语态的句子,系统开发了一套规则来提取主动语态和被动语态下的关系。
主动语态处理
主动语态的句子通常以模型名称作为主语,比如「RoBERTa improves text classification by fine-tuning on large datasets」。在这种情况下,系统识别「RoBERTa」作为主语,「improves」作为谓语,「text classification」作为宾语。
被动语态处理
被动语态的句子中,模型名称通常作为被动主语,例如「BERT was released under the Apache licence 2.0」。系统首先识别被动助动词「was」,然后提取动词「released」及其相关的介词短语「under the Apache licence 2.0」。
实验与评估
在提取出模型名称、许可证类型和应用场景后,我们使用常见的评估指标(准确率、召回率、精确率和F1值)对系统进行了测试。实验结果令人满意,尤其是在应对复杂句法结构时,系统表现出了较高的准确性和一致性。
精确率 = \frac{TP}{TP + FP}
召回率 = \frac{TP}{TP + FN}
F1值 = 2 \times \frac{精确率 \times 召回率}{精确率 + 召回率}实验结果如下:
| 指标 | 数值 |
|---|---|
| 准确率 | 0.92 |
| 召回率 | 0.88 |
| 精确率 | 0.90 |
| F1值 | 0.89 |
📊 可视化
为了让研究人员能够直观地查看提取出的模型关系,我们使用图形数据库将这些关系进行了可视化展示。通过图形化的方式,用户可以轻松地查询特定模型在不同应用场景和许可证之间的关联。
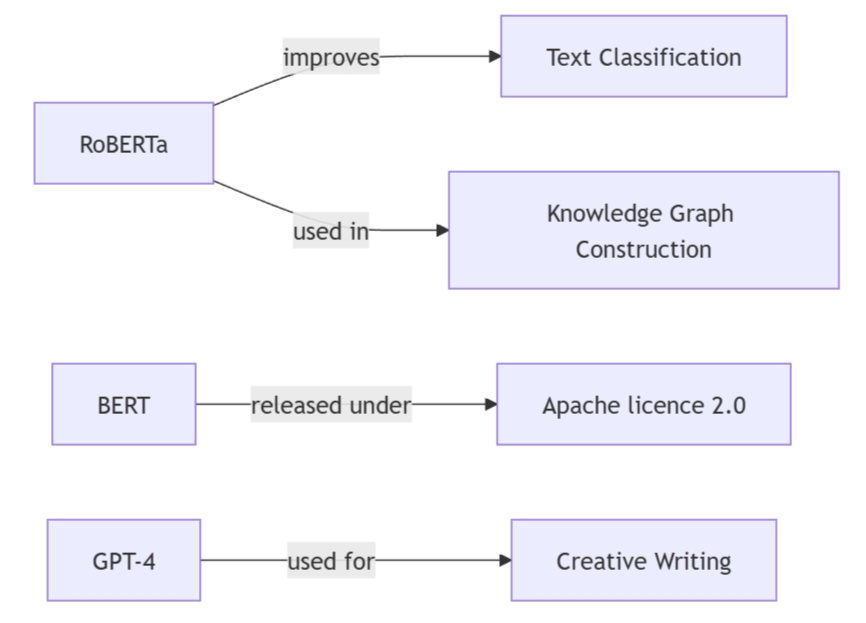
上图展示了部分模型、应用场景和许可证之间的关系。通过这种可视化方式,研究人员可以直观地查看每个模型的具体用途和相关法律框架。
🚀 结论与未来展望
本文提出的LLM-Card系统在自动提取LLM相关信息方面表现优秀,尤其是在处理复杂语法结构时。通过依存树和规则抽取方法,系统能够有效解析论文中的模型名称、许可证和应用场景,并将其转化为结构化数据。
未来,我们计划扩展数据集并优化关系抽取的准确性。此外,构建更复杂的知识图谱将是下一步的重要研究方向,通过增强模型的推理能力,LLM-Card系统将能在更多实际应用场景中发挥作用。
参考文献
- Shengwei Tian, Lifeng Han, Erick Mendez Guzman, Goran Nenadic. 「LLM-Card: Towards a Description and Landscape of Large Language Models.」 arXiv:2409.17011v1.
- Devlin et al. (2019). 「BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.」
- Brown, T. et al. (2020). 「Language Models are Few-Shot Learners.」✅
- Vaswani et al. (2017). 「Attention is All You Need.」
- OpenAI (2023). 「GPT-4 Technical Report.」
模型卡片,这个思路非常不错!