

引言 🤓
在当今的深度学习领域,矩阵乘法(Matrix Multiplication,简称 MatMul)无疑是最受宠爱的操作之一。就像一位明星在颁奖典礼上闪耀的光芒,MatMul 操作在大多数神经网络中占据了主导地位,尤其是在大型语言模型(LLMs)中。然而,随着模型规模的不断扩大,这位明星的光芒也越来越刺眼,计算成本随之飙升。研究者们开始思考:是否有可能完全抛弃 MatMul,同时依然保持模型的高性能?
在这篇文章中,我们将深入探讨一项创新的研究,提出了一种 无 MatMul 的可扩展语言模型,旨在打破传统的计算限制,提升效率。
⚙️ 理论背景
矩阵乘法之所以如此普遍,是因为图形处理单元(GPUs)对其进行了优优化,能够高效地进行并行计算。正如 AlexNet 在 ILSVRC2012 比赛中大放异彩,GPU 的优化使得 MatMul 成为深度学习的「硬件彩票」。然而,正如每个明星都有其阴暗面,MatMul 的高计算成本却成为了制约语言模型发展的瓶颈。
MatMul 的替代方案
研究者们已经提出了几种替代方案来减轻这一负担。例如,AdderNet 通过用加法替代乘法来简化卷积神经网络的计算。然而这些方法大多仍依赖于某种形式的矩阵运算。最近的 BitNet 在语言建模中采用了二进制和三元量化技术,尽管在一定程度上减少了计算量,但仍未能完全摆脱 MatMul 的依赖。
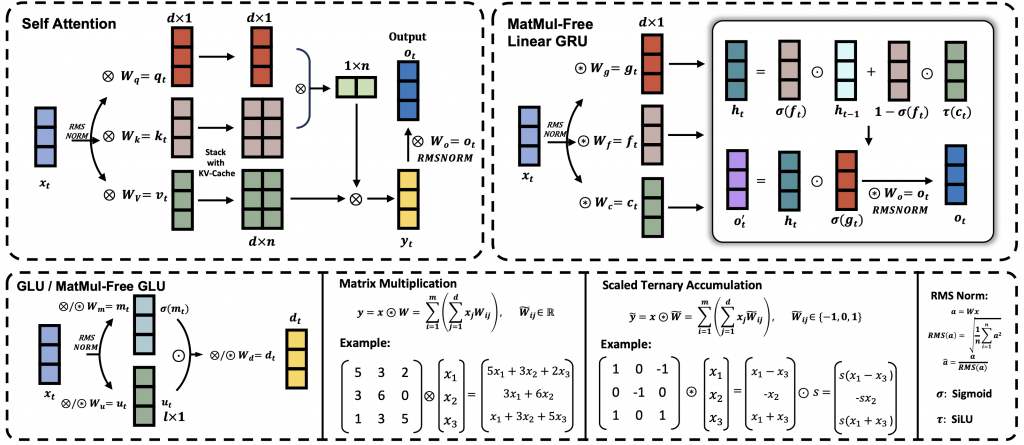
🛠️ 研究方法
本研究的核心在于 无 MatMul 模型(MatMul-free LM) 的构建。该模型通过使用加法操作和元素级的 Hadamard 乘积来替代传统的矩阵乘法。具体来说,模型采用三元权重(-1, 0, +1)来简化计算,从而去除了所有的矩阵乘法操作。
以下是模型的主要组成部分:
- MatMul-free Dense Layers:使用三元权重的 BitLinear 层替代标准的密集层,这样可以将矩阵乘法转换为简单的加法与累加操作。
- MatMul-free Token Mixer:采用优化的门控循环单元(GRU),通过元素级的乘法替代自注意力机制中的矩阵乘法。
- 硬件优化:研究团队提供了一种优化的 GPU 实现,以及基于 FPGA 的定制硬件解决方案,以进一步降低内存使用和计算需求。
📈 实验结果
在多个语言建模任务上的实验表明,无 MatMul 模型在性能上与当前最先进的 Transformer 模型相当。具体来说:
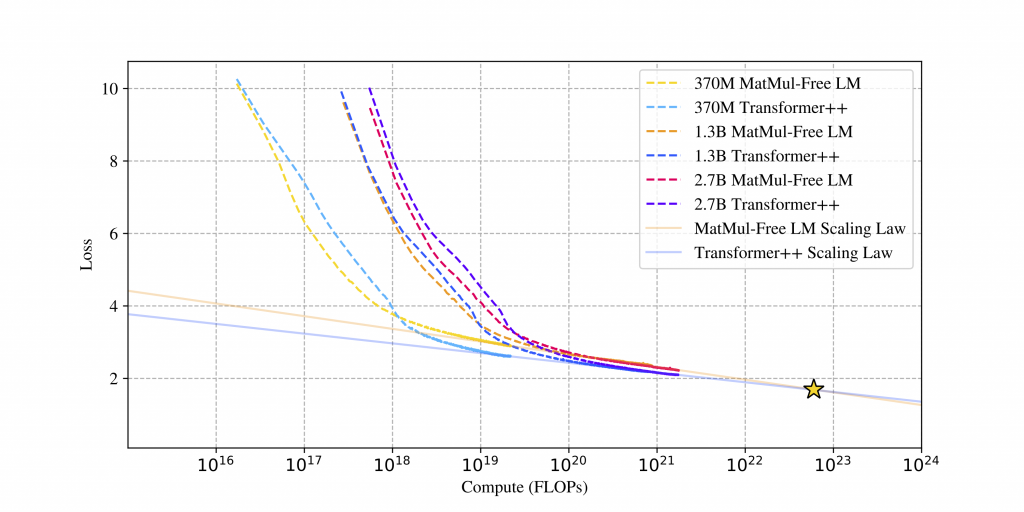
- 在 370M. ��1.3B 和 2.7B 参数规模下的实验,MatMul-free LM 在内存使用上减少了高达 61%,并且在推理速度上提高了 4.57 倍。✅
- 随着模型规模的增加,MatMul-free LM 的性能与传统 Transformer 模型之间的差距逐渐缩小,显示出更好的扩展性。
性能对比图
⚡ 未来的展望
这一研究不仅展示了在不牺牲性能的情况下,如何有效地去除 MatMul 操作,还为未来的轻量级语言模型提供了新的思路。随着对模型高效性和可持续性需求的日益增加,开发者们无疑应当将目光投向无 MatMul 架构的潜力。
结论 🏁
我们已经证明了无 MatMul 语言模型的可行性与有效性,并且为未来的研究指明了方向。随着对大型语言模型的需求不断增长,MatMul-free 语言模型可能成为下一代高效、可持续的语言处理架构的基石。
参考文献 📚
- Rui-Jie Zhu et al. “Scalable MatMul-free Language Modeling.” arXiv:2406.02528.
- 相关文献和算法优化研究。
- 量化技术在深度学习中的应用案例。
🌟 MatMul-Free LM:颠覆语言建模的创新架构
引言 🤖
在深度学习的舞台上,矩阵乘法(MatMul)犹如那位光芒四射的巨星,主宰着大多数神经网络的计算。然而,随着模型规模的急剧扩大,MatMul 运算所需的计算成本也随之飙升,成为了语言模型发展的绊脚石。为了解决这一难题,MatMul-Free LM 项目应运而生,提出了一种全新的语言模型架构,旨在完全消除 MatMul 操作。
什么是 MatMul-Free LM? 🔍
MatMul-Free LM 是一种不再依赖矩阵乘法的语言模型架构。这种创新的设计使得模型在性能上不逊色于传统的 Transformer,同时在计算效率和内存使用上显著优化。通过采用三元权重和其他高效的计算策略,这一模型为未来的语言处理应用开辟了新的可能性。
📈 扩展性与性能
在不同规模的模型(370M. ��1.3B和2.7B参数)上进行的实验表明,MatMul-Free LM 在扩展性方面表现优异。研究发现,该模型在利用额外计算资源来提升性能时,表现出更陡峭的下降趋势,显示出其在效率上的优势。✅
安装指南 🛠️
要使用 MatMul-Free LM,您需要满足以下依赖项:
可以通过以下命令安装:
pip install -U git+https://github.com/ridgerchu/matmulfreellm使用示例 📚
预训练模型库
模型初始化
以下是如何使用 Hugging Face 的 AutoModel 初始化模型的示例代码:
from mmfreelm.models import HGRNBitConfig
from transformers import AutoModel
config = HGRNBitConfig()
model = AutoModel.from_config(config)文本生成示例
一旦成功预训练模型,您可以使用 🤗 文本生成 API 进行文本生成:
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
import mmfreelm
from transformers import AutoModelForCausalLM, AutoTokenizer
name = '您的模型名称'
tokenizer = AutoTokenizer.from_pretrained(name)
model = AutoModelForCausalLM.from_pretrained(name).cuda().half()
input_prompt = "在一个令人震惊的发现中,科学家们发现了一群独角兽生活在一个偏远的地方,"
input_ids = tokenizer(input_prompt, return_tensors="pt").input_ids.cuda()
outputs = model.generate(input_ids, max_length=32, do_sample=True, top_p=0.4, temperature=0.6)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])引用 📖
如果您在工作中使用此库,请引用我们的预印本:
@article{zhu2024scalable,
title={Scalable MatMul-free Language Modeling},
author={Zhu, Rui-Jie and Zhang, Yu and Sifferman, Ethan and Sheaves, Tyler and Wang, Yiqiao and Richmond, Dustin and Zhou, Peng and Eshraghian, Jason K},
journal={arXiv preprint arXiv:2406.02528},
year={2024}
}结论 🎉
MatMul-Free LM 的推出为语言建模领域带来了新的曙光,展现出在不依赖传统矩阵乘法的情况下,如何实现高效且强大的模型。这一创新架构不仅为研究者提供了新的工具,也为应用开发者打开了更广阔的可能性。希望更多的人能够参与到这一项目中来,共同推动语言模型技术的发展!