引言
自从Transformer被引入以来(Vaswani et al., 2017),衍生的大型语言模型(LLMs)在多个自然语言处理(NLP)任务上不断提升了技术水平。其中,开放域对话是指设计一个对话代理,使其能够在任何话题上与用户进行社交互动,展示出人类的能力,如共情、个性和娱乐性(Walker et al., 2021)。常见的方法是使用特定的数据集进行微调,通常针对某一或多种技能(例如PersonaChat,Blended Skill Talk,Empathetic Dialogues等)。然而,这些数据集的构建成本高且通常仅限于一种语言。
在本研究中,我们探索了一种高效且成本低廉的解决方案:通过角色扮演零样本提示,利用具备多语言能力的大型语言模型(如Vicuna)来提升开放域对话能力。我们设计了一种提示系统,与指令跟随模型结合,能够在两项任务中与人类评估中的微调模型相媲美,甚至超越它们。
相关工作
开放域对话领域有很多发展,大多数解决方案主要集中在使用特定数据进行微调。例如BlenderBot系列,Meena,LaMDA等。这些模型展示了出色的对话技能,但除了对数据的依赖外,它们通常仅限于英语。基础模型是NLP领域的一个新趋势,它们展示了多语言能力并在多个基准上表现出色。其中,LLaMA模型是本研究的基础。
方法论
指令跟随 vs 对话技能
引用Reitz(2019)的话:「对话不仅仅是进行对话。真正的对话描述了一种相互、关系、专注和有意义的互动方式。」尽管指令跟随模型经过优化以进行对话,但它们在真正的对话中往往无法满足这些方面的要求。尤其是社交方面——相互性、关系性和专注性——表现得较差。
角色扮演提示
理解角色扮演提示不仅限于扮演特定角色。根据Shanahan等(2023)的模拟和模拟器框架,LLM是一个模拟器,在预训练期间吞噬了无数的模拟物。在每次模拟中,它会随机选择一个合适的模拟物进行展示。角色扮演提示通过使LLM倾向于适应特定对话任务的模拟物来增强对话技能。
提示结构
开放域对话属于复杂任务领域(Santu和Feng,2023),提示的微小变化可能会影响模型的表现。因此,定义一个通用的提示结构是必要的,以便可以针对不同的对话任务进行调整。我们保留以下部分作为提示工程模块的构建块:
- 系统指令:定义目标任务的规格和总体期望行为。
- 情境上下文:提供有助于模型更好地执行任务的背景信息。
- 响应指令:引导LLM生成符合写作风格、目标语言和创造性的响应。
- 对话历史:包含用户和LLM的先前消息,可根据需要进行摘要或更新。
实验
系统架构
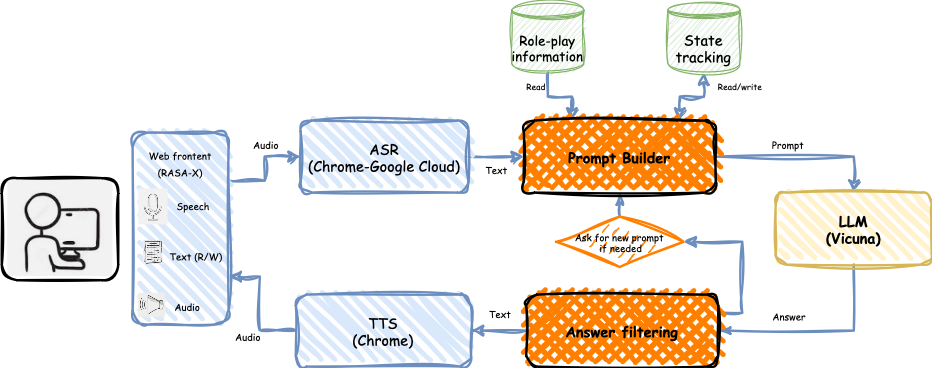
系统架构如图1所示,它包括多个模块,如基于Rasa X工具的Web界面、提示构建模块和过滤模块。用户可以通过语音或文本与代理进行交流。
具有人类能力的开放域对话:PersonaChat任务
此任务通过使用从PersonaChat数据集中提取的个性特征来增强LLM的对话能力。我们设计了浅层提示和高级提示两种方案进行比较。
模拟多模态对话:INT任务
此任务验证了模型在特定主题下进行对话的能力。对话系统旨在进行多模态对话,背景是神经科学实验。用户和代理需要讨论一张图片,并找出其推广目标。
人类评估
为了评估模型的性能,我们进行了自我聊天和人机聊天两种评估。评估标准包括一致性、互动性和人性化。此外,对于INT任务,还增加了任务完成度这一标准。
自我聊天评估
自我聊天评价通过比较不同设置下生成的对话进行。结果表明,模型尺寸越大、指令调优的模型表现越好。
人机聊天评估
在PersonaChat任务中,我们收集了用户与模型的对话,并与BlenderBot进行了比较。结果显示,高级提示在一致性和人性化上得分最高,而浅层提示在互动性上得分最低。
在INT任务中,Vicuna & Advanced Prompt系统在所有标准上表现最佳,除了人性化。实验表明,该系统在保持对话互动性方面表现出色。
统计分析
我们对收集的对话进行了统计分析,包括词汇量、每条消息的单词数等。结果显示,Vicuna模型在生成的对话中词汇量较大,但也存在过度冗长的问题。
过滤错误分析
我们评估了响应生成中的错误类型,包括内容不适当、消息过长或使用错误语言等。结果表明,通过适当的提示和过滤,可以减少这些错误的发生率。
结论
本文探讨了通过结构化角色扮演提示工程来提升LLM在开放域人机对话中的表现。实验结果表明,尽管语言模型仍存在一定的缺陷,如幻觉,但用户对这些代理的感知可以与高成本的微调模型相媲美。未来的工作可以通过全方位的强化学习来进一步优化提示生成过程。
参考文献
- Vaswani et al. (2017)
- Walker et al. (2021)
- Shanahan et al. (2023)
- Santu 和 Feng (2023)
- Zhang et al. (2018)
- Roller et al. (2021)