✨ 引言
大型语言模型(LLMs)在各种自然语言处理任务中展现了惊人的推理能力,但仍面临过时知识、幻觉和不透明决策等挑战。相较之下,知识图谱(KGs)提供了明确且可编辑的知识,有助于缓解这些问题。然而,现有的KG增强LLM范式往往需要手动预定义探索空间的广度,并且在知识图谱中导航时缺乏灵活性。这种方法无法根据问题语义自适应地探索推理路径,也无法自我纠正错误的推理路径,导致效率和效果的瓶颈。为了解决这些问题,我们提出了一种新的自我纠正自适应规划范式,命名为「Plan-on-Graph」( PoG )。
🔍 PoG的基本原理
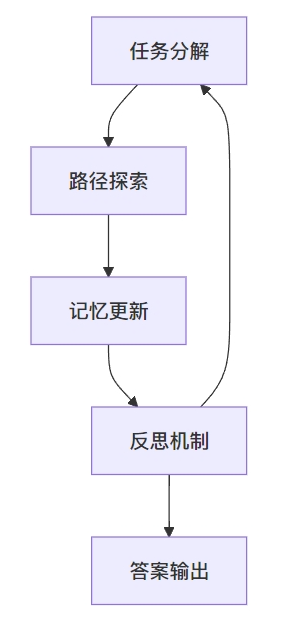
PoG的核心在于通过将问题分解为多个子目标,同时重复自适应探索推理路径、更新记忆和反思自我纠正的过程,直至达到答案。具体而言,PoG设计了三个重要机制:引导(Guidance)、记忆(Memory)和反思(Reflection),共同保障图推理的自适应自我纠正规划的广度。
📊 任务分解
在探索过程中,PoG首先通过语义分析将问题分解为多个子目标,以指导后续的路径探索。这些子目标不仅有助于识别与问题条件相关的路径,还有助于在探索过程中动态调整路径的广度。
🧩 记忆更新
在解决问题的过程中,PoG会更新存储在记忆中的信息,包括所检索的子图、推理路径和子目标状态。这一机制确保了模型在进行反思时能够回顾之前的推理过程,从而更有效地进行路径纠正。
🔁 反思机制
当LLM判断当前信息不足以回答问题时,PoG通过反思机制决定是否需要自我纠正推理路径。这一机制使得模型能够动态调整探索方向,避免陷入错误的推理路径。
📈 实验结果
在三个真实世界的KGQA数据集上进行的广泛实验表明,PoG在效果和效率上均优于现有的KG增强LLM方法。我们在CWQ、WebQSP和GrailQA数据集上的实验结果显示,PoG不仅在准确率上超越了所有基准方法,而且在计算效率上也显著提高。
🎉 结论
通过引入自我纠正和自适应探索机制,PoG显著提高了LLM的推理能力。实验结果证明了其在复杂问题解答中的有效性和高效性,标志着知识图谱与LLM集成的新进展。未来,我们将继续探讨如何进一步提高模型的自信度和效率,以应对更复杂的推理任务。
参考文献
- Chen, L. et al. (2024). Plan-on-Graph: Self-Correcting Adaptive Planning of Large Language Model on Knowledge Graphs. NeurIPS.✅
知识点: PoG系统的基本架构组件
题目: PoG系统由哪几个关键组件构成?
选项:
A. 任务分解、路径探索、内存更新、评估✅
B. 知识获取、推理分析、结果输出✅
C. 输入处理、图谱检索、答案生成✅
D. 问题分析、路径规划、知识整合✅
原文依据: 「As illustrated in Figure 2, PoG consists of four key components: Task Decomposition, Path Exploration, Memory Updating, and Evaluation.」(出自:第3节,第3页)
解析: PoG系统由四个关键组件构成:任务分解(Task Decomposition)、路径探索(Path Exploration)、内存更新(Memory Updating)和评估(Evaluation)。这些组件共同工作以实现自适应规划和自我纠错功能。
知识点: PoG的工作流程
题目: PoG系统的基本工作流程是怎样的?
选项:
A. 直接在知识图谱中搜索答案✅
B. 先分解问题,然后反复进行路径探索、更新记忆和反思,直到得到答案✅
C. 依靠大语言模型直接生成答案✅
D. 通过预定义规则进行推理✅
原文依据:「PoG first decomposes the question into several sub-objectives as guidance of planning exploration and then repeats the process of adaptively exploring reasoning paths to access relevant KG data, updating memory to provide historical retrieval and reasoning information for reflection, and reflecting on the need to self-correct reasoning paths until arriving at the answer.」(出自:第3节,第3页)
解析: PoG的工作流程是先将问题分解为子目标,然后通过不断重复探索路径、更新记忆和反思的过程来寻找答案。这种迭代式的工作方式能够实现自适应探索和自我纠错。
知识点: Guidance机制的作用
题目: PoG中的Guidance机制的主要功能是什么?
选项:
A. 直接生成最终答案✅
B. 将问题分解为包含条件的子目标,指导自适应探索✅
C. 存储历史检索信息✅
D. 评估答案的正确性✅
原文依据:「Guidance: To better guide adaptive exploration by harnessing conditions in the question, we employ the LLM to decompose the question into sub-objectives containing conditions, thereby benefiting the identification of relevant paths to each condition with flexible exploration breadth.」(出自:第2页)
解析: Guidance机制的主要作用是利用LLM将问题分解为包含具体条件的子目标,这些子目标可以更好地指导系统进行灵活的路径探索。
知识点: Memory机制的组成
题目: PoG中的Memory机制记录了哪些信息?
选项:
A. 仅记录最终答案✅
B. 仅记录子目标状态✅
C. 记录子图、推理路径和子目标状态✅
D. 仅记录原始问题✅
原文依据:「We record and update the subgraph to provide the LLM with all retrieved entities for initializing new exploration and self-correcting paths, reasoning paths to preserve the relationships between entities for LLM reasoning and allow for path correction, and sub-objective status」(出自:第2页)
解析: Memory机制记录三类信息:子图(用于新探索和路径自我纠错)、推理路径(保存实体间关系)和子目标状态。这些信息为系统的反思机制提供了必要的历史信息支持。
知识点: Reflection机制的功能
题目: PoG中Reflection机制的主要决策包括什么?
选项:
A. 仅决定是否继续探索✅
B. 仅决定回溯到哪个实体✅
C. 决定是否继续探索以及如何进行路径自我纠错✅
D. 仅生成最终答案✅
原文依据:「To determine whether to continue or self-correct current reasoning paths, we design a reflection mechanism to employ the LLM to reason whether to consider other entities into new exploration and decide which entities to backtrack to for self-correction based on information in memory.」(出自:第3页)
解析: Reflection机制主要负责两个决策:1)是否需要继续探索新的实体;2)如果需要自我纠错,应该回溯到哪个实体重新开始探索。这些决策都基于Memory中存储的历史信息。
知识点: PoG的创新点
题目: PoG相比现有方法的主要创新点是什么?
选项:
A. 首次引入知识图谱辅助LLM推理✅
B. 首次设计反思机制实现自我纠错和自适应探索✅
C. 首次使用LLM进行问答✅
D. 首次提出子目标分解方法✅
原文依据:「To the best of our knowledge, we are the first to design a reflection mechanism for self-correction and adaptive KG exploration into KG-augmented LLMs」(出自:第2页)
解析: PoG的主要创新点在于首次在KG增强的LLM中引入反思机制,实现了自我纠错能力和自适应的图谱探索。这是之前方法所不具备的特性。
知识点: Task Decomposition的作用
题目: Task Decomposition组件的主要目的是什么?
选项:
A. 直接生成答案✅
B. 探索知识图谱✅
C. 将问题分解为带条件的子目标以指导探索✅
D. 评估答案正确性✅
原文依据:「To harness conditions in the question to better guide the adaptive exploration process, PoG decomposes the task of answering the question into multiple sub-objectives containing conditions through semantic analysis of the LLM.」(出自:第4页)
解析: Task Decomposition的主要目的是通过LLM的语义分析,将原问题分解为多个包含具体条件的子目标,这些子目标可以更好地指导后续的自适应探索过程。
知识点: Memory机制的更新过程
题目: Memory机制在什么时候会更新其存储的信息?
选项:
A. 仅在得到最终答案时✅
B. 仅在开始新的问题时✅
C. 在每轮路径探索后✅
D. 仅在发现错误时✅
原文依据:「repeats the process of adaptively exploring reasoning paths to access relevant KG data, updating memory to provide dynamic evidence for reflection」(出自:第2页)
解析: Memory机制在每轮路径探索后都会更新信息,包括更新子图、推理路径和子目标状态,以便为下一轮的反思决策提供最新的动态证据。
知识点: Path Exploration的特点
题目: PoG中的路径探索(Path Exploration)具有什么特点?
选项:
A. 固定宽度的探索✅
B. 单向不可逆的探索✅
C. 自适应宽度且支持回溯的探索✅
D. 随机探索✅
原文依据:「we propose an adaptive exploration strategy that is not limited by the fixed number of relations and entities」(出自:第5页)
解析: PoG的路径探索具有自适应宽度的特点,不受固定关系和实体数量的限制,并且通过反思机制支持回溯和自我纠错,这与传统方法的固定宽度和单向探索有本质区别。
知识点: PoG的子目标特性
题目: PoG中的子目标(sub-objectives)具有什么特点?
选项:
A. 完全独立,互不关联✅
B. 可以相互依赖和引用✅
C. 只能线性执行✅
D. 必须按固定顺序完成✅
原文依据:「It is important to note that sub-objectives in O may refer to the results obtained from other sub-objectives in O, allowing for interdependencies in the reasoning process.」(出自:第4页)
解析: PoG中的子目标之间可以存在相互依赖关系,一个子目标可以引用其他子目标得到的结果,这种设计使得推理过程更加灵活和符合实际需求。
知识点: Memory中的子图功能
题目: Memory机制中存储的子图(subgraph)主要用于什么目的?
选项:
A. 仅用于存储最终答案✅
B. 为新的探索和路径自我纠错提供检索实体✅
C. 仅用于可视化显示✅
D. 存储原始问题✅
原文依据:「record and update the subgraph to provide the LLM with all retrieved entities for initializing new exploration and self-correcting paths」(出自:第2页)
解析: Memory中存储的子图主要用于为LLM提供已检索的实体信息,这些信息可用于初始化新的探索或进行路径自我纠错,是系统适应性探索的重要基础。
知识点: Reflection机制的决策依据
题目: Reflection机制在做决策时主要依据什么信息?
选项:
A. 仅依据原始问题✅
B. 仅依据当前探索路径✅
C. 依据Memory中存储的历史检索和推理信息✅
D. 随机决策✅
原文依据:「To determine whether to continue or self-correct current reasoning paths… based on information in memory」(出自:第3页)
解析: Reflection机制在决定是否继续探索或进行自我纠错时,主要依据Memory中存储的历史检索和推理信息,这确保了决策的合理性和连续性。
知识点: Guidance机制的实现方式
题目: PoG是如何实现Guidance机制的?
选项:
A. 使用预定义规则✅
B. 通过LLM进行语义分析和问题分解✅
C. 随机生成子目标✅
D. 直接复制原问题✅
原文依据:「we employ the LLM to decompose the question into sub-objectives containing conditions」(出自:第2页)
解析: PoG通过让LLM对问题进行语义分析,将其分解为包含具体条件的子目标,这种方式可以更好地理解和处理问题的语义信息。
知识点: Path Exploration的工作流程
题目: Path Exploration在每轮探索中的主要步骤是什么?
选项:
A. 直接获取答案✅
B. 先探索关系后探索实体✅
C. 随机选择路径✅
D. 仅探索实体✅
原文依据:「This strategy involves a two-step process of finding relevant relations and utilizing these selected relations to explore entities.」(出自:第5页)
解析: Path Exploration采用两步探索策略:首先探索相关关系,然后基于选定的关系来探索实体,这种方式可以更有效地控制探索空间。
知识点: Memory中的推理路径作用
题目: Memory机制中存储推理路径的主要作用是什么?
选项:
A. 仅用于显示✅
B. 保存实体间关系并支持路径纠错✅
C. 存储最终答案✅
D. 记录问题信息✅
原文依据:「reasoning paths to preserve the relationships between entities for LLM reasoning and allow for path correction」(出自:第2页)
解析: Memory中存储的推理路径用于保存实体之间的关系信息,这些信息既用于LLM的推理过程,也支持系统进行路径纠错。
知识点: PoG系统的自适应特性
题目: PoG系统的自适应特性主要体现在哪些方面?
选项:
A. 仅体现在路径宽度调整✅
B. 仅体现在答案生成✅
C. 体现在探索宽度和自我纠错能力✅
D. 仅体现在问题分解✅
原文依据:「propose a novel self-correcting adaptive planning paradigm… which first decomposes the question into several sub-objectives and then repeats the process of adaptively exploring reasoning paths」(出自:第2页)
解析: PoG的自适应特性主要体现在两个方面:能够根据需要调整探索的宽度,以及具有自我纠错的能力,这使得系统能够更灵活地处理复杂问题。
知识点: Memory中的子目标状态作用
题目: Memory机制中记录子目标状态的主要目的是什么?
选项:
A. 仅显示进度✅
B. 帮助LLM识别已知信息并避免遗忘✅
C. 存储最终答案✅
D. 记录原始问题✅
原文依据:「sub-objective status to make the LLM recognize the known information of each condition and mitigate its forgetting in reflection stage」(出自:第3页)
解析: 记录子目标状态的主要目的是帮助LLM识别每个条件的已知信息,并在反思阶段防止遗忘这些信息,这对于保持推理的连续性和完整性很重要。
知识点: Reflection机制的触发时机
题目: 在PoG中,Reflection机制在什么时候会被触发?
选项:
A. 仅在开始新问题时✅
B. 仅在得到答案时✅
C. 在每轮路径探索和记忆更新后✅
D. 仅在发现错误时✅
原文依据:「repeats the process of… reflecting on the need to self-correct reasoning paths until arriving at the answer」(出自:第2页)
解析: Reflection机制在每轮路径探索和记忆更新后都会被触发,用于决定是否需要继续探索或进行自我纠错,直到找到答案为止。
知识点: PoG的任务完成条件
题目: PoG系统在什么条件下会完成任务?
选项:
A. 完成固定轮次的探索✅
B. 耗尽所有可能的路径✅
C. 获得满足所有子目标条件的答案✅
D. 达到预设时间限制✅
原文依据:「repeats the process… until arriving at the answer」和「To determine whether to continue or self-correct current reasoning paths」(出自:第2-3页)
解析: PoG会持续进行探索、更新和反思,直到找到满足所有子目标条件的答案才会完成任务,这保证了答案的完整性和准确性。
知识点: 三个核心机制的协同工作
题目: PoG中的三个核心机制(Guidance、Memory、Reflection)是如何协同工作的?
选项:
A. 完全独立运行✅
B. 按固定顺序依次执行✅
C. 相互配合:Guidance指导探索,Memory提供信息支持,Reflection基于Memory决策✅
D. 随机配合✅
原文依据:「three mechanisms are designed to work together, to guarantee the adaptive breadth of self-correcting planning for graph reasoning」(出自:第2页)
解析: 三个机制通过紧密配合来工作:Guidance机制通过子目标分解来指导探索方向,Memory机制存储历史信息,Reflection机制则基于Memory中的信息来做出决策,三者共同确保了系统的自适应性和自我纠错能力。
非常有意思!
标准的还原论!
PoG
三个重要机制!
提升效果的核心
分解、探索、记忆、反思