在这个充满惊喜的开源LLM(大语言模型)时代,各类模型百花齐放,就像是一个大型的模特秀,除了那些常见的基础模型和微调模型,还有一位默默无闻、却又才华横溢的选手——模型融合(Model Merging)。它像是那位总在后台默默支持的经纪人,虽然不在聚光灯下,却能帮助模特们在舞台上大放异彩。
📚 什么是模型融合?
模型融合,简单来说,就是将多个经过微调(SFT,Supervised Fine-Tuning)的模型在参数层面上进行合并,最终形成一个「融合模型」。这一过程不仅能让模型同时「学会」多种任务,甚至在某些情况下表现得比单个模型更为出色。想象一下,如果多个模特(模型)在一起排练,经过训练后,他们的合体表演自然会更加精彩。
而模型融合的魅力在于它的高效性:
- 省时省力:与传统训练相比,模型融合无需重新训练,这就像是通过一场精心准备的聚会,节省了大量的时间和资源。
- 数据隐私无忧:只需要模型参数,避免了数据隐私问题,简直是对现代社会一种温柔的保护。
🧩 模型融合的合理性
在探讨模型融合的合理性时,我们需要引入一个概念:Delta Parameters。直观上,Delta Parameters 就是指模型在微调前后参数的变化值。通过对这些参数的分析,我们发现它们的冗余性非常高,换句话说,很多参数是可以被「丢弃」的,犹如一场不必要的聚会中可以省略的闲聊。
根据一项研究(DARE),当我们随机丢弃90%-99%的Delta Parameters 时,其效果与原模型几乎没有区别。这意味着,冗余的Delta Parameters可以在模型融合前被大量去除,这样的操作不仅不会影响合并效果,反而能提升融合后的模型表现。
📊 Delta Parameters 的可视化
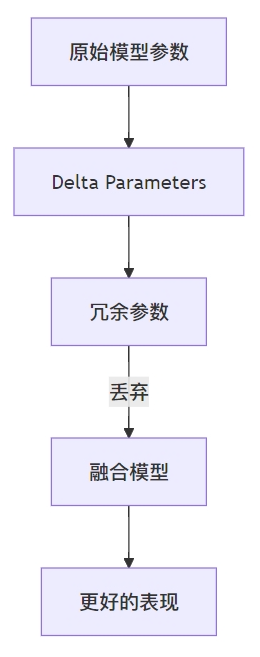
正如上述图表所示,冗余参数的丢弃不仅简化了模型的复杂性,还提升了其在多任务学习中的性能。
🔍 模型融合的常见技术
那么,模型融合到底有哪些常见的技术呢?让我们逐一揭开这些技术的神秘面纱。
1. 简单平均(Simple Averaging)
这一方法类似于我们在学校时的简单加法,直接将多个模型的参数平均。虽然简单,但在少量模型融合的情况下效果尚可,通常作为基准进行比较。
2. Fisher 加权平均(Fisher Averaging)
这一方法可谓是模型融合中的「学霸」。它通过对每个参数进行加权,来衡量各个任务中参数的重要性。公式如下:
其中,$w_i$ 是Fisher信息矩阵,用于衡量每个参数在任务中的重要性。通过这种方式,我们能更好地利用不同模型之间的差异性,实现更优的融合效果。
3. 任务算术(Task Arithmetic)
此方法核心在于将不同任务的参数进行加和,然后乘以一个缩放因子,与基础模型合并。公式如下:
其中,$\alpha$ 是从验证集中选择的缩放因子,通常取值范围在0.3到0.5之间。
4. RegMean 方法
RegMean 主要针对线性层的参数融合,其思想是尽量让合并后的模型输出与合并前的模型输出接近。通过设定目标函数,我们能在合并过程中保持输出的一致性。这个过程简直就像是在调和乐器,确保每个音符都能和谐共鸣。
5. TIES 合并
TIES(解决干扰的合并)则是模型融合中的「干扰消除专家」。它的核心思想在于减少冗余参数和方向干扰。其主要步骤包括:
- Trim:保留每个待合并模型中参数值最大的20%。
- Elect:确定每个参数的合并方向(+1、-1或0),类似于投票机制。
- Disjoint Merge:对每个参数进行直接平均,但不包括值为0的参数。
这就像是在一场激烈的辩论中,最终选出最具代表性的观点,形成一个最优决策。
🌟 模型融合的技术特性
1. In-Domain Performance
在相同任务上,融合后的模型通常表现得不如单个模型,但随着技术的发展,这种差距逐渐缩小。以TIES论文的结果为例,所有融合模型的效果仍然比单模型和多任务学习模型差,但随着技术的迭代,融合模型的潜力也逐渐被挖掘出来。
2. OOD Generalization
OOD(Out-Of-Distribution)泛化能力是模型在未见过的数据分布上的表现。TIES论文的实验表明,融合模型在一定程度上学到了鲁棒的任务解决能力,显示了其在新任务上的适应能力。
🏁 总结
通过对模型融合的探讨,我们看到这一技术的合理性和潜力。虽然模型融合在参数层面上的合并过程乍一看似乎不够科学,但其背后有Delta Parameters的冗余性和任务向量的正交性作为支撑,具备了一定的合理性。随着技术的进步,模型融合不仅可以帮助我们理解LLM如何「解锁」特定任务,还能为优化其适应能力提供重要的分析工具。
希望本文能为你在模型融合的探索之路上,提供一些有趣而有效的见解!继续关注,我们还有更精彩的内容等着你哦!
📚 参考文献
- Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch(DARE).
- Editing models with task arithmetic.
- Merging Models with Fisher-Weighted Averaging.
- Dataless Knowledge Fusion by Merging Weights of Language Models(RegMean).
- TIES-Merging: Resolving Interference When Merging Models.