Embedding模型
Embedding模型模块构建了涵盖15+个主流向量化技术的完整语义表示生态,专注于文本、图像、音频等多模态数据的高质量向量化表示。该模块系统性地整理了OpenAI text-embedding-ada-002、Cohere Embed、Sentence-BERT、BGE系列、M3E系列等国际国内领先的文本嵌入模型,以及CLIP、ALIGN等多模态嵌入技术。技术特色涵盖了稠密检索、语义相似度计算、跨语言表示、领域适应等核心能力,详细解析了对比学习、掩码语言模型、双塔架构、交叉注意力等关键技术机制。模块深入介绍了向量数据库集成、相似度搜索、聚类分析、异常检测等典型应用场景,以及模型微调、量化压缩、推理加速、批处理优化等工程化实践技术。
内容包括MTEB评测基准、中文评测数据集、多语言支持、长文本处理等专业评估维度,以及Faiss、Pinecone、Weaviate、Chroma等向量数据库的集成方案。此外,还提供了RAG检索增强、推荐系统、文档搜索、知识图谱等下游应用的最佳实践,以及嵌入模型选型指南、性能优化策略、成本效益分析等实用指导,帮助开发者构建高效的语义搜索和智能推荐系统,实现大规模文本数据的精准理解和快速检索。+文本分块
-----------------------------------------------------------
- 2.Embedding模型+文本分块.md
- 1.BGE
- 1.GTE阿里
- 1.Jina Reranker+Segmenter
- 1.Seed1.5-Embedding 字节
- 1.cohere
- 1.openai-embeding
- 1.qwen3-embedding
- 2.E5 Embedding-微软
- 2.gritlm
- 2.mixedbread
- 3.Zilliz-milvus云原生
- 3.instructor-embedding港大
- 5.文本分块策略/1.Meta-chunking
- 5.文本分块策略/2.late-chunking
1.BGE
简介
本次分析涉及三个项目。FlagEmbedding专注于检索增强大语言模型领域,包含推理、微调、评估等多个项目,发布了如bge-en-icl、bge-multilingual-gemma2等多个模型,还推出了基于记忆启发的知识发现技术MemoRAG。MemoRAG是一个创新的RAG框架,基于高效的超长记忆模型,能实现对数据库的全局理解,增强证据检索和响应生成的准确性。FlagEmbedding的finetune示例文件夹包含embedder、reranker等相关文件。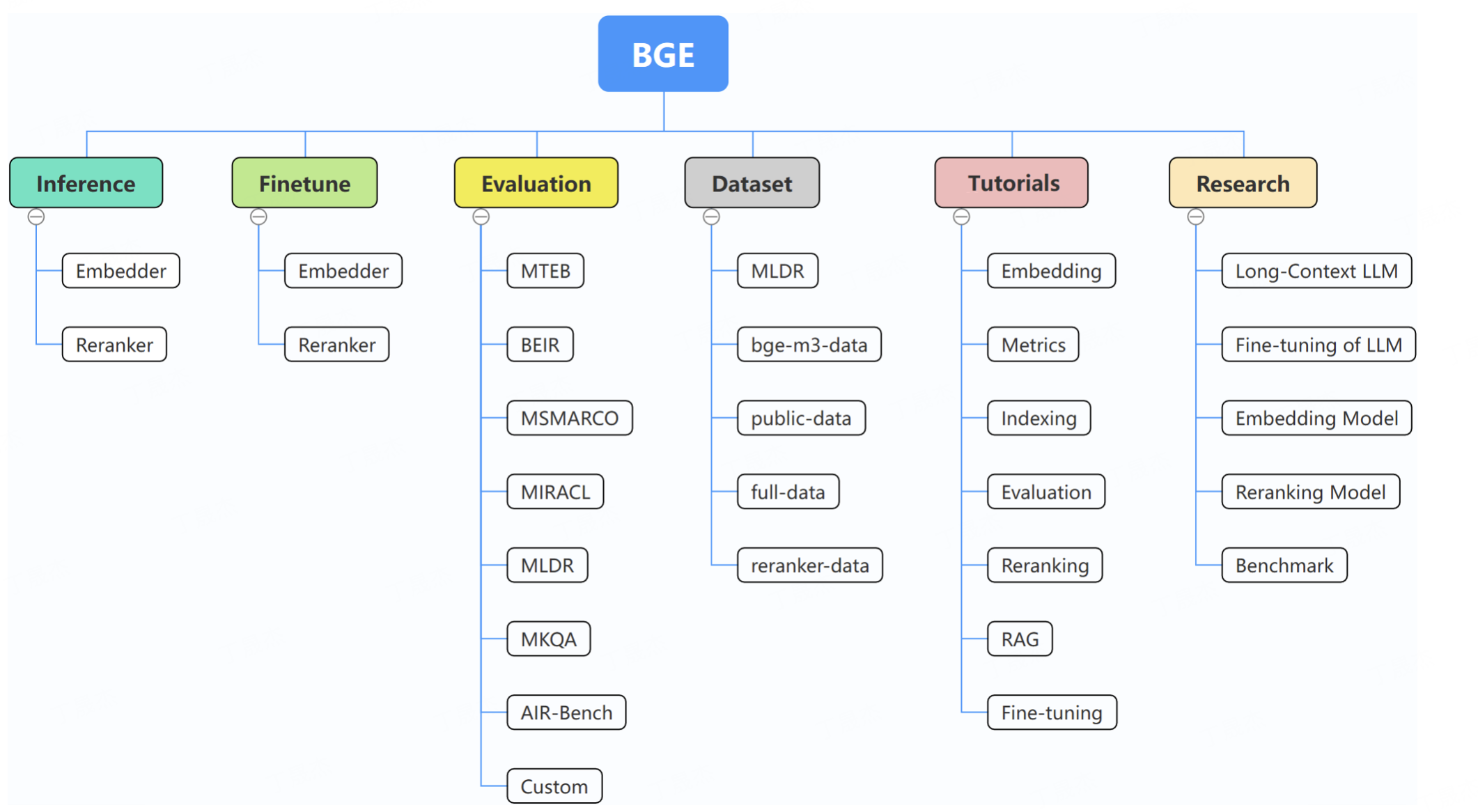
核心功能
- FlagEmbedding:提供多种语言和任务的向量模型与重排器,支持模型推理、微调,有上下文学习能力,可用于文本检索、相似度计算等。
- MemoRAG:具备全局记忆处理能力,能处理百万级令牌;可优化适配新任务;能从全局记忆中生成精确线索;有高效缓存和上下文重用机制,支持多种使用模式和任务,如问答、总结等。
技术原理
- FlagEmbedding:基于大型语言模型,通过训练使模型学习文本的语义信息,将文本转换为向量表示,在推理时通过内积计算向量相似度进行检索。微调时可通过添加指令、挖掘难负样本等方式优化模型性能。
- MemoRAG:依托高效的超长记忆模型对数据库进行全局理解,通过记忆模型召回特定线索,增强证据检索,再结合生成模型生成准确且上下文丰富的响应。
应用场景
- 信息检索:利用FlagEmbedding的向量模型和MemoRAG的记忆检索能力,在大规模文本数据中快速准确地找到相关信息。
- 问答系统:为问答系统提供更准确的答案,MemoRAG可结合上下文生成高质量回答。
- 文本总结:使用MemoRAG对长文本进行总结,提取关键信息。
- 多语言处理:FlagEmbedding的多语言模型可用于跨语言的信息检索和处理。
- FlagEmbedding/BGE BAAI-bge
- FlagEmbedding/examples/finetune at master · FlagOpen/FlagEmbedding
- BGE-MemoRAG: Empowering RAG with a memory-based data interface for all-purpose applications!
------------------------------------------------------------
1.GTE阿里
简介
链接主要围绕阿里巴巴通义实验室的GTE系列模型展开。该系列模型是通用文本向量模型,为RAG等检索场景提供领先检索能力。包括基于BERT架构、Qwen LLM系列训练的模型,以及最新的GTE - Multilingual系列(mGTE)。mGTE具备高性能、长文档支持、多语言处理等特性,有效提升RAG系统检索与排序效果。此外,还有如gte - Qwen2 - 7B - instruct等模型,在多语言任务评估中有出色表现。核心功能
- 文本表示:将输入文本转化为固定维度的连续向量,用于文本聚类、相似度计算、向量召回等下游任务。
- 排序:对召回的候选文档进行复杂排序,输出相关性分数,实现更精准排序。
- 多语言处理:支持多种语言,满足跨语言检索需求。
- 长文本处理:可处理较长文本,部分模型支持8k甚至32k token的文本长度。
- 弹性向量维度:支持输出不同维度的向量表示,平衡存储成本和模型效果。
- 稀疏向量表示:计算文本中每个单词的词权重,适用于精准匹配和长上下文检索场景。
技术原理
- 底座模型:基于双向注意力的Encoder - only结构,参考Decode - Only架构大语言模型训练技巧,对BERT架构改进,如采用旋转位置编码RoPE、GLU激活函数,使用XLM - Roberta词表。通过多阶段预训练,结合数据采样、unpadding技术提升训练效率。
- 文本表示模型:采用双阶段训练,先用大规模弱监督文本对数据训练,再用高质量标注文本对数据和难负样本数据训练。引入弹性维度表示和稀疏向量表示,计算对比学习损失。
- 排序模型:使用对比学习损失函数,仅用监督数据微调,以文本对为输入计算相关性分数。
应用场景
- 信息检索:在多语言、跨语言、长文本检索场景中,快速准确找到相关文档。
- 文本相似度计算:计算文本间的相似度,用于文本匹配、推荐等。
- 文本聚类:将相似文本聚为一类,便于信息整理和分析。
- 问答系统:为用户问题检索相关文档,提升回答的准确性和丰富性。
- 【算法精讲系列】MGTE系列模型,RAG实施中的重要模型-阿里云开发者社区
- GTE文本向量-中文-通用领域-large · 模型库
- 模型详情页 · 魔搭社区
- 魔搭社区
- 魔搭社区
------------------------------------------------------------
1.Jina Reranker+Segmenter
简介
链接涉及Jina相关工具与服务。Jina可用于构建多模态AI应用,借助云原生技术搭建服务与管道,支持多种通信协议,能实现模型部署、服务编排、流式处理等功能。Segmenter API则可将长文本进行分词和分块处理,帮助LLM管理输入、优化性能,支持超100种语言,且提供免费使用。核心功能
- Jina:构建多模态AI服务与管道,支持grpc、http和websockets通信;模型部署与服务编排,支持容器化和云部署;支持流式处理LLM输出;具备可扩展性和并发处理能力。
- Segmenter API:对长文本进行分词和分块;支持多语言;通过GET请求统计文本中的标记数量,POST请求提供更多功能,如返回标记、标记ID、前/后N个标记等;提供不同速率限制。
技术原理
- Jina:基于DocArray进行数据处理,使用Executor封装模型逻辑,通过Gateway连接执行器,利用Deployment和Flow实现服务编排和扩展,支持多种通信协议进行数据交互,结合云原生技术如Kubernetes和Docker Compose实现部署。
- Segmenter API:利用正则表达式模式和常见结构线索,将文本分割成标记或块,依据输入文本的语法特征(如句子结尾、段落分隔符、标点符号和某些连词)进行分割。
应用场景
- Jina:适用于构建各种多模态AI应用,如聊天机器人、智能助手、图像生成服务等;可用于处理和部署机器学习模型,实现模型的高效服务和扩展。
- Segmenter API:用于处理长文本数据,如文档处理、信息检索等;帮助LLM管理输入,优化模型性能;在多语言处理场景中,对不同语言的文本进行分词和分块。
- Jina AI - Your Search Foundation, Supercharged.
- jina-ai/jina: ☁️ Build multimodal AI applications with cloud-native stack
- Jina Segmenter API
------------------------------------------------------------
1.Seed1.5-Embedding 字节
ByteDance-Seed/Seed1.5-Embedding是字节跳动开发的一款嵌入式模型,托管于Hugging Face平台。该模型旨在通过提供API服务,实现人工智能领域的开放和普及,并支持在线试用和部署。
核心功能
- 向量嵌入服务:核心功能是将输入数据(如文本)转换为高维度的向量表示,即嵌入(embeddings)。
- API集成:提供API接口,方便开发者将其集成到各种AI应用中。
- 生产环境部署:支持快速部署,可用于构建生产级别的LLM(大型语言模型)应用,具备自动扩展和监控能力。
技术原理
Seed1.5-Embedding作为一种嵌入模型,其技术原理基于深度学习,旨在将复杂的非结构化数据(如文本、图像等)映射到低维或高维的连续向量空间中。在这个向量空间中,语义或结构上相似的数据点在空间中距离更近。具体而言,它可能采用了Transformer或其他神经网络架构,通过训练学习到数据的深层语义特征,并将这些特征编码为密集向量。这些向量捕获了原始数据的语义信息和上下文关系,使得计算机能够更好地理解和处理语言等复杂信息。应用场景
- 大型语言模型(LLM)部署:作为LLM应用的基础组件,用于文本理解、语义搜索、内容推荐等。
- 语义搜索:通过比较查询和文档的嵌入向量,实现高效且准确的语义相关性搜索。
- 信息检索与推荐系统:根据用户偏好或内容相似性生成个性化推荐。
- 数据聚类与分类:将相似的数据点聚类,或用于基于内容的自动分类任务。
- 问答系统:通过理解问题和答案的语义匹配,提升问答的准确性。
- ByteDance-Seed/Seed1.5-Embedding · Hugging Face
------------------------------------------------------------
1.cohere
简介
Cohere是一个为现代企业提供服务的安全AI平台,拥有前沿的多语言模型、先进的检索技术和AI工作区。其提供Command、Embed、Rerank三个系列的模型,可满足企业多样化需求。此外,还有Cohere Python SDK,能让用户在多个平台访问Cohere模型。核心功能
- 模型应用:提供生成文本、分析文档、构建AI助手等功能,支持高级搜索、智能数据检索与发现。
- 定制开发:可根据企业专有数据微调模型,提供低代码集成方案,支持与专家合作定制AI解决方案。
- 安全部署:有SaaS、云服务提供商、虚拟专用云、本地部署等多种安全部署选项。
- SDK功能:Cohere Python SDK支持在多平台访问Cohere模型,具备流式端点功能。
技术原理
- 模型家族:通过Command、Embed、Rerank三个系列模型,满足企业不同需求。
- 检索增强生成(RAG):内置RAG技术,基于企业数据微调模型,确保输出可验证。
- SDK实现:Cohere Python SDK借助编程方式,实现对不同平台Cohere模型的访问。
应用场景
- 复杂行业:适用于金融服务、医疗保健、制造业、能源、公共部门等行业。
- 应用开发:帮助开发者基于专有数据构建高影响力应用,从概念验证到全面生产。
- Cohere | The leading AI platform for enterprise
- cohere-ai/cohere-python: Python Library for Accessing the Cohere API
- Cohere Documentation — Cohere
------------------------------------------------------------
1.openai-embeding
简介
OpenAI发布新模型、降低GPT - 3.5 Turbo价格,并推出管理API密钥和了解API使用情况的新方式。新模型包括两个新嵌入模型、更新的GPT - 4 Turbo预览模型、更新的GPT - 3.5 Turbo模型和更新的文本审核模型。默认情况下,发送到OpenAI API的数据不会用于训练或改进其模型。核心功能
- 嵌入模型:推出text - embedding - 3 - small和text - embedding - 3 - large两个新嵌入模型,性能提升且价格降低,支持缩短嵌入以平衡性能和成本。
- GPT - 3.5 Turbo:推出新模型gpt - 3.5 - turbo - 0125,输入和输出价格降低,有格式响应准确性提高等改进。
- GPT - 4 Turbo:发布更新的预览模型gpt - 4 - 0125 - preview,完成任务更彻底,修复非英语UTF - 8生成的错误。
- 文本审核模型:发布text - moderation - 007,更新相关别名指向该模型。
- API管理:可从API密钥页面分配权限,使用仪表板和导出功能可按API密钥级别查看使用指标。
技术原理
- 嵌入模型:采用Matryoshka Representation Learning技术训练,使开发者可通过传递维度API参数缩短嵌入,而不丢失概念表示属性。
- 其他模型:文档未详细提及具体技术原理,但涉及模型架构优化、参数调整等提升性能和修复错误。
应用场景
- 嵌入模型:用于ChatGPT和Assistants API的知识检索、检索增强生成(RAG)开发工具、多语言和英语任务的聚类或检索。
- GPT - 3.5 Turbo和GPT - 4 Turbo:适用于代码生成、文本对话、格式响应等多种自然语言处理任务。
- 文本审核模型:帮助开发者识别潜在有害文本,构建安全的AI系统。
- API管理:方便开发者在不同团队、产品或项目中管理API使用和控制权限。
- New embedding models and API updates | OpenAI
- 模型 - OpenAI API
------------------------------------------------------------
1.qwen3-embedding
简介
Qwen3 Embedding模型系列是Qwen家族的最新专有模型,专为文本嵌入和排序任务设计。它基于Qwen3系列的密集基础模型,提供多种大小(0.6B、4B和8B)的文本嵌入和重排序模型,继承了基础模型的多语言能力、长文本理解和推理技能,在多个文本嵌入和排序任务中取得显著进展。

核心功能
- 文本嵌入:将文本转换为向量表示,在下游应用评估中表现出色,8B大小的嵌入模型在MTEB多语言排行榜上排名第一。
- 文本重排序:在各种文本检索场景中表现优异,可对检索结果进行重新排序。
- 多语言支持:支持超100种语言,包括多种编程语言,具备强大的多语言、跨语言和代码检索能力。
- 灵活定制:提供全尺寸范围的嵌入和重排序模型,开发者可组合使用;嵌入模型允许灵活定义向量维度,两者都支持自定义指令以提升特定任务性能。
技术原理
文档未详细提及技术原理相关内容,推测基于Qwen3系列的基础架构,利用深度学习技术,通过训练学习文本的语义信息,将文本映射到低维向量空间,以实现文本嵌入和排序任务。应用场景
- 文本检索:包括网页搜索、文档检索等,提高检索准确性。
- 代码检索:帮助开发者快速找到相关代码。
- 文本分类:对文本进行分类,如新闻分类、情感分析等。
- 文本聚类:将相似文本聚集在一起。
- 双语挖掘:挖掘双语语料。
- Qwen3-Embedding合集详情-来自Qwen · 魔搭社区
- Qwen3-Reranker合集详情-来自Qwen · 魔搭社区
- QwenLM/Qwen3-Embedding
------------------------------------------------------------
2.E5 Embedding-微软
简介
E5(Embeddings from maRy's language models)是微软UNILM项目下推出的一系列文本嵌入模型。它旨在通过将文本(如句子、段落或文档)转换为密集向量(即嵌入),从而捕捉其语义信息。E5模型支持多语言,并提供不同大小的模型以平衡推理效率和嵌入质量,是文本表示和语义匹配任务中的重要工具。核心功能
E5模型的核心功能在于生成高质量的文本嵌入。这些嵌入能够有效捕获文本的语义含义和上下文关系,使得相似语义的文本在向量空间中距离相近,从而支持:- 语义搜索与匹配: 实现基于文本内容深层含义的搜索和文档匹配。
- 文本相似度计算: 精准衡量两段文本之间的语义相似性。
- 文本聚类与分类: 根据文本的语义内容进行高效的聚类和分类。
- 跨语言文本理解: 利用其多语言能力,实现不同语言间文本的语义对齐和理解。
技术原理
E5模型的技术原理主要基于大规模自监督预训练和Transformer架构。- 自监督预训练: 模型通过在海量文本数据上进行自监督学习(如掩码语言模型、对比学习等),自动学习文本的深层语义表示,无需人工标注。
- Transformer架构: 继承了Transformer模型的强大编码能力,能够有效捕捉文本中的长距离依赖关系和复杂语义模式。
- 指令调优(Instruction Tuning): 通过在特定任务上进行指令调优,进一步优化模型生成嵌入的质量,使其性能达到或超越同类模型的先进水平。
- 多语言能力: 采用跨语言训练策略,使其能够处理和理解多种语言的文本。
- 模型大小与效率: 提供小型、基础型、大型等不同尺寸的模型,以满足不同应用场景对模型效率和性能的需求权衡。
应用场景
- 信息检索系统: 提升搜索引擎、问答系统和推荐系统的语义理解能力,提供更精准的搜索结果和推荐。
- 自然语言理解(NLU): 应用于情感分析、文本摘要、命名实体识别等任务,作为下游NLU任务的特征提取器。
- 数据挖掘与分析: 对大规模文本数据进行语义聚类、主题建模和异常检测。
- 智能客服与对话系统: 辅助理解用户意图,提升人机交互的自然性和准确性。
- 跨语言应用: 促进跨语言信息检索、机器翻译和国际化内容管理等领域的发展。
- unilm/e5 at master · microsoft/unilm
------------------------------------------------------------
2.gritlm
简介
GritLM(Generative Representational Instruction Tuning Language Model)是由Contextual AI、香港大学和微软公司等共同推出的创新性大型语言模型。它通过“生成式表征指令调优”(GRIT)这一新型训练范式,成功地将文本生成(Generation)与文本表征(Representation/Embedding)两种核心能力统一到一个单一模型中,旨在实现语言理解和生成的协同优化。核心功能
GritLM的核心功能在于其“双模态”能力,即在一个模型中同时提供:- 文本生成: 具备强大的语言生成能力,能够根据指令生成高质量、连贯的文本内容。
- 文本表征(Embedding): 能够将文本转换为高效、富有语义信息的向量表示(嵌入),用于检索、相似性匹配等任务。该模型在文本生成和表征任务上均达到了当前先进(state-of-the-art)的性能水平,并推出了不同规模的模型,例如GritLM-7B(基于Mistral 7B微调)和GritLM-8x7B(基于Mixtral 8x7B微调)。
技术原理
GritLM的关键技术在于生成式表征指令调优(GRIT)。这一方法论创新性地利用指令来训练语言模型,使其同时擅长表征和生成任务。传统上,生成模型和表征模型通常是分开训练的。GRIT通过统一的训练框架,使得模型能够学习到既能理解语义以生成文本,又能捕获文本深层含义以生成有效嵌入的能力。这使得模型在推理时能够高效地执行两种截然不同的任务,特别是在参数量适中的情况下,仍能保持高性能。应用场景
GritLM的独特双模态能力使其在多种自然语言处理应用场景中具有显著优势:- 检索增强生成(RAG): 作为核心组件,GritLM可以高效地生成高质量的文本嵌入以进行信息检索,随后利用其生成能力根据检索到的信息生成准确和连贯的答案,显著提升RAG系统的效率和效果。
- 智能问答系统: 结合检索和生成能力,实现更精准的问题理解和答案生成。
- 文本摘要与改写: 利用其生成能力进行文本处理。
- 语义搜索与推荐系统: 利用其表征能力进行高效的语义匹配和内容推荐。
- 多任务处理: 在需要同时进行文本理解和文本输出的复杂AI应用中,GritLM提供了一体化解决方案,简化了系统架构。
- ContextualAI/gritlm: Generative Representational Instruction Tuning
- GritLM/GritLM-7B · Hugging Face
- GritLM/GritLM-8x7B · Hugging Face
------------------------------------------------------------
2.mixedbread
简介
Mixedbread是一个全托管式AI搜索引擎,提供从嵌入和重排模型到文档解析等一系列组件,可将原始数据转化为智能搜索体验,为AI代理、聊天机器人和知识系统提供支持,受全球开发者信赖,模型下载量超5000万。
核心功能
- 向量存储:让数据适配AI和代理,可快速构建生产级搜索引擎,支持超100种语言的多模态搜索。
- 嵌入与重排:提供MTEB排行榜模型,语义搜索和RAG准确性高,开源且性价比高。
- 文档解析:将文档转化为结构化数据,提取文本、表格和布局,无需手动预处理。
- 企业部署:支持多种部署方式,具备企业级安全,符合SOC 2、HIPAA和GDPR合规要求。
技术原理
运用在MTEB排行榜表现出色的嵌入与重排模型进行语义搜索和RAG,利用文档解析技术将各类文档转化为AI可用的结构化数据,通过向量存储技术让数据适配AI和代理,实现多语言多模态搜索。应用场景
- 构建生产级AI搜索和RAG应用。
- 为AI代理、聊天机器人和知识系统提供智能搜索体验。
- 处理企业财务等各类文档的搜索和分析。
- Mixedbread
------------------------------------------------------------
3.Zilliz-milvus云原生
简介
Zilliz 致力于打造性能出色、高度可扩展、性价比高的向量数据库。其产品包括 Zilliz Cloud(全托管 SaaS 及 BYOC 服务,提供深度优化、开箱即用的 Milvus 体验)和 Milvus(开源向量数据库)。网站还提供定价方案、开发者文档、场景解决方案等内容。第二个链接为 Zilliz Cloud 的登录页面。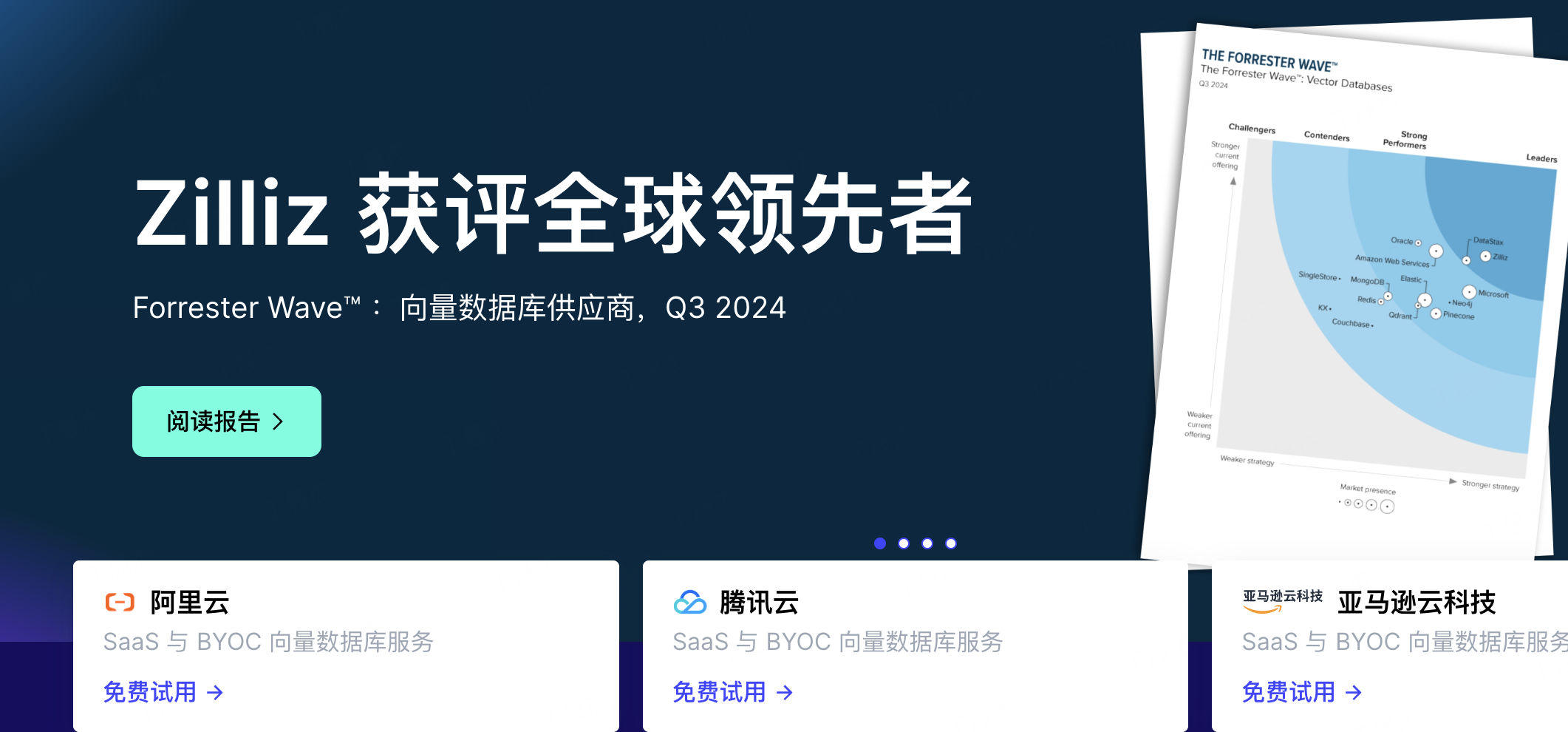
核心功能
- Zilliz Cloud:全托管向量数据库服务,易部署,适用于多种场景,具有高性能、高可用性、高扩展性、安全合规等特点,支持快速构建和扩展向量搜索服务。
- Milvus:开源向量数据库,专为可扩展的相似性搜索打造。
技术原理
- Zilliz Cloud:采用云原生分布式向量数据库架构,基于开源 Milvus 进行深度优化,对企业版向量数据库引擎进行软硬件双重优化。
- Milvus:专注于可扩展的相似性搜索技术实现。
应用场景
适用于检索增强生成(RAG)等场景,可用于需要进行向量相似性搜索的各类业务场景。------------------------------------------------------------
3.instructor-embedding港大
简介
该项目提供了 INSTRUCTOR 模型代码和预训练模型。INSTRUCTOR 是一种指令微调文本嵌入模型,能根据任务指令生成适用于任何任务和领域的文本嵌入,在70多个嵌入任务中取得了最优成绩。核心功能
- 生成文本嵌入:可根据自定义指令为文本生成嵌入向量。
- 计算文本相似度:利用生成的嵌入向量计算文本间的相似度。
- 信息检索:使用自定义嵌入进行信息检索。
- 文本聚类:将文本进行聚类处理。
技术原理
基于指令微调技术,利用 Multitask Embeddings Data with Instructions (MEDI) 数据集进行训练。MEDI 包含330个来自多个数据源的数据集,涵盖广泛领域和任务。训练时构建正、负样本对,确保同一训练批次的数据来自同一任务。应用场景
- 科学研究:为科学文献、标题等生成嵌入,用于信息检索和聚类。
- 金融领域:对金融报表、新闻等文本进行嵌入和相似度计算。
- 医疗行业:处理医学文献、病例等文本,实现信息检索和分类。
- 信息检索系统:如维基百科,根据问题检索相关文档。
- [xlang-ai/instructor-embedding: [ACL 2023] One Embedder, Any Task: Instruction-Finetuned Text Embeddings](https://github.com/xlang-ai/instructor-embedding)
------------------------------------------------------------
1.Meta-chunking
简介
Meta - Chunking项目旨在通过逻辑感知学习高效的文本分割方法。它利用大语言模型(LLMs)将文档灵活划分为逻辑连贯、独立的块,动态调整粒度以维护内容逻辑完整性,提高文档检索相关性和内容清晰度。项目提出相关概念和两种实现策略,进行了广泛实验,并提供了快速启动和示例程序。核心功能
- 引入Meta - Chunking概念,在句子和段落粒度间进行文本分割。
- 提出Margin Sampling Chunking和Perplexity (PPL) Chunking两种实现策略。
- 采用动态组合策略的Meta - Chunking,平衡细粒度和粗粒度文本分割。
- 对四个基准的十一个数据集进行广泛实验。
- 提供Gradio chunking程序,可动态调整参数。
技术原理
Meta - Chunking基于大语言模型能力,允许块大小可变,以捕捉和维护内容逻辑完整性。通过Margin Sampling Chunking和Perplexity (PPL) Chunking两种策略,以及动态组合策略,在不同粒度间进行文本分割,避免逻辑链中断。在实验中,先将数据集分块,建立向量数据库,生成问题答案,再评估分割对相关指标的影响。应用场景
- 文档检索:提高文档检索的相关性。
- 文本处理:提升内容清晰度,便于文本分析和理解。
- IAAR-Shanghai/Meta-Chunking 位于 386dc29b9cfe87da691fd4b0bd4ba7c352f8e4ed
------------------------------------------------------------
2.late-chunking
简介
链接围绕“Late Chunking”(后期分块)展开。该方法用于长上下文嵌入模型,能在分块时保留上下文信息,生成上下文分块嵌入,提升检索和RAG性能。jina-embeddings-v3 API已支持此功能,且在多种数据集上验证了其相比传统分块方法的优势,文档越长效果越明显。核心功能
- 生成上下文分块嵌入:利用长上下文嵌入模型,先对长文本的所有令牌进行嵌入,在变压器模型处理后、均值池化前进行分块,使分块嵌入包含完整上下文信息。
- 提升检索性能:在RAG等检索任务中,改善文本分块嵌入效果,减少重要上下文信息的丢失,提高检索准确性。
- 适配多语言与多任务:如jina-embeddings-v3支持多语言,有特定任务的LoRA适配器,可用于查询文档检索、聚类、分类和文本匹配等任务。
技术原理
- 模型处理:借助长上下文嵌入模型(如支持8192个令牌的jina-embeddings-v2-base-en),先将整个文本或尽可能多的文本输入变压器层,生成包含全文信息的令牌向量序列。
- 分块操作:在获得令牌级嵌入后,使用边界线索进行分块,对分块后的令牌向量序列应用均值池化,得到考虑全文上下文的分块嵌入。
应用场景
- 检索增强生成(RAG):将文档分割成小块存储在向量数据库,通过后期分块生成的上下文分块嵌入,更精准地检索相关文本块,为大语言模型提供信息以生成查询响应。
- 多语言文本处理:适用于jina-embeddings-v3等多语言嵌入模型,在多语言数据和长上下文检索任务中发挥作用。
- 文本聚类、分类和匹配:通过生成高质量的上下文分块嵌入,提升这些任务的性能。
- jina-ai/late-chunking: Code for explaining and evaluating late chunking (chunked pooling)
- 长上下文嵌入模型中的后期分块 --- Late Chunking in Long-Context Embedding Models
- [[2409.04701] Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models](https://arxiv.org/abs/2409.04701)
- Jina Embedding v3:一个前沿的多语言嵌入模型 - 知乎
AntSK FileChunk – 开源AI文档切片工具
AntSK FileChunk是一款开源的智能文本切片工具,专注于对PDF、Word、TXT等长文档进行深度语义理解,实现文本的智能化分割与管理。它旨在解决传统文本切片方法(如基于固定字符或Token数量)导致的语义割裂问题,确保切片内容的语义完整性和连贯性,特别为RAG(检索增强生成)应用进行了优化。
核心功能
- 智能文档切片: 能够处理PDF、Word、TXT等多种格式的文档,将其分割成语义完整且连贯的片段。
- 语义边界识别: 基于先进的语义分析技术,智能识别文本中的语义边界,避免内容割裂。
- RAG应用优化: 专门为检索增强生成(RAG)应用设计,提供高质量的文本块,提升检索效率和生成效果。
- 支持多语言: 兼容处理多种语言的文档内容。
- 动态切片调整: 具备根据需求动态调整切片策略的能力。
技术原理
AntSK FileChunk的核心技术原理是深度语义理解(Deep Semantic Understanding)与语义分析(Semantic Analysis)。它摒弃了传统的基于固定长度(如字符数或Token数)的机械式切分方法,转而利用自然语言处理(NLP)和机器学习(Machine Learning)技术,对文档内容进行上下文分析和语义解析。通过构建文档的语义模型,该工具能够识别段落、句子乃至更细粒度的语义单元之间的关联性,从而在不破坏语义完整性的前提下,进行智能的文本块划分。这包括但不限于利用词嵌入(Word Embeddings)、句嵌入(Sentence Embeddings)以及更复杂的神经网络模型(Neural Network Models)来捕捉文本的深层含义和逻辑结构。应用场景
- 大模型知识库构建: 作为大型语言模型(LLM)构建知识库的预处理工具,确保输入LLM的文档片段具有高语义质量,提升模型检索和生成答案的准确性。
- 智能问答系统: 优化问答系统中文档检索的精度,为用户提供更精准的答案来源。
- 文档内容管理: 协助企业或个人对大量文档进行结构化处理和内容提炼,便于快速检索和分析。
- 信息抽取与归纳: 在海量非结构化文本中高效地抽取关键信息并进行归纳总结。
- 学术研究与文献分析: 帮助研究人员对学术论文、报告等进行精细化切分,便于交叉引用和深度分析。
- 项目官网:https://filechunk.antsk.cn/
- GitHub仓库:https://github.com/xuzeyu91/AntSK-FileChunk
Youtu-Embedding – 腾讯文本嵌入模型
Youtu-Embedding是由腾讯优图实验室开发的一款业界领先的通用文本表示模型。该模型旨在将文本转化为高质量的嵌入向量(Embedding),从而在多种自然语言处理(NLP)任务中展现出卓越的性能和广泛的适用性。
核心功能
- 文本表示与嵌入: 将文本数据转换为高维向量,捕捉文本的语义信息。
- 信息检索(IR): 支持高效的文本搜索和匹配,通过语义相似度进行检索。
- 语义文本相似度(STS): 准确衡量不同文本片段之间的语义关联程度。
- 聚类与分类: 基于文本嵌入进行无监督的文本分组和有监督的文本类别预测。
- 重排序(Reranking): 在搜索或推荐系统中对结果进行重新排序,提升相关性。
技术原理
Youtu-Embedding 基于深度学习模型架构,通过大规模语料库的预训练,学习文本的上下文信息和语义特征,从而生成具有丰富语义的密集向量表示。其核心技术可能包括:- Transformer架构: 利用自注意力机制有效捕获长距离依赖关系。
- 对比学习(Contrastive Learning): 通过正负样本对的学习,优化嵌入空间,使相似文本的嵌入距离更近,不相似文本的距离更远。
- 大规模预训练: 在海量文本数据上进行训练,以泛化到多种下游任务。
- 多任务学习: 可能结合多种NLP任务的监督信号进行训练,提升模型通用性。
- 量化感知训练/模型蒸馏: 可能采用轻量化技术,优化模型大小和推理速度,以适应工业级应用。
应用场景
- 智能搜索与推荐: 提高搜索引擎和推荐系统的相关性,理解用户查询和内容之间的语义匹配。
- 内容理解与分析: 对海量文本内容进行自动化分类、聚类和情感分析。
- 问答系统与聊天机器人: 提升理解用户意图的能力,匹配更准确的答案或回复。
- 文档管理与知识图谱构建: 通过文本嵌入实现文档的智能组织、关联和检索。
- 机器翻译与跨语言理解: 辅助理解不同语言文本的语义,提高翻译质量。
- GitHub仓库:https://github.com/TencentCloudADP/youtu-embedding
- HuggingFace模型库:https://huggingface.co/tencent/Youtu-Embedding
- arXiv技术论文:https://arxiv.org/pdf/2508.11442