在当今的人工智能领域,尤其是大语言模型(LLMs)迅速发展的背景下,如何有效地利用外部信息以提升模型的生成能力,成为了一个亟待解决的问题。本文将深入探讨一种新颖的框架——KV-Fusion(Key-Value Fusion),它旨在解决传统生成模型在处理输入上下文时所面临的「中间丢失」(Lost in the Middle)问题。我们将详细阐述其算法实现过程及其背后的细节。
🧩 背景与挑战
在检索增强生成(RAG)模型中,通常采用两步法:首先从知识库中提取相关信息,然后将提取的信息与模型的参数知识结合,生成最终的响应。然而,现有的解码器模型往往存在位置偏见,尤其是对输入序列中间部分的忽视,这导致在上下文信息被打乱时,模型生成的结果不一致。KV-Fusion通过引入一种新的解码器架构,旨在消除这种位置依赖性。
🔍 KV-Fusion 算法概述
KV-Fusion的核心思想是通过并行提取关键值缓存(Key-Value Caches),并在训练过程中注入统一的位置信息,从而实现对输入顺序的不敏感性。该框架主要由两个部分组成:预填充解码器(Prefill Decoder, Dp)和可训练解码器(Trainable Decoder, Dt)。
1. 预填充解码器(Dp)
预填充解码器的主要任务是从多个输入段落中并行提取关键值缓存。其具体过程如下:
- 输入表示:设输入段落集合为 $C = {c_1, c_2, \ldots, c_N}$,每个段落的固定令牌长度为 $n$。每个段落的关键值缓存由以下公式表示:
- 其中,$|H|$ 是关键值头的数量,$d_h$ 是每个头的维度,$L$ 是解码器的层数。
- 缓存重塑:将每层的关键值缓存沿着令牌轴连接,形成每层的单一缓存:
- 这里的 $RES$ 函数用于重塑缓存,以便后续训练使用。
2. 可训练解码器(Dt)
可训练解码器的输入包括重塑后的关键值缓存和目标令牌。其训练过程如下:
- 输入格式:可训练解码器接收两个输入:重塑的关键值缓存 ${K^l, V^l}_{l=1}^L$ 和目标令牌 $y$,目标令牌包含查询指令和答案,长度为 $m$。
- 训练过程:通过下一个令牌预测进行训练,条件是重塑的关键值缓存,而不是依赖于之前的令牌:
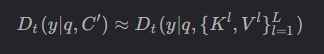
- 其中,$q$ 表示指令,$C』$ 是输入段落的令牌集合。
3. 算法实现
KV-Fusion的完整算法实现可以概括为以下步骤:
def Key_Value_Fusion(Dt, Dp, Training_Data):
for i in range(L. : # 遍历训练数据✅
KV_cache = Dp(Training_Data[i]) # 提取关键值缓存
K_l, V_l = RES(KV_cache) # 重塑缓存
Loss = LM_loss(y_i, Dt(q_i; {K_l, V_l})) # 计算损失
Update_parameters(Dt, Loss) # 更新可训练解码器的参数在此过程中,LM_loss 函数用于计算语言模型的损失,Update_parameters 函数则负责根据损失更新模型参数。
📊 实验设置与结果
KV-Fusion在多个开放域问答数据集上进行了实验,包括自然问题(NQ)、TriviaQA和POPQA。实验结果表明,KV-Fusion在处理打乱上下文顺序时,能够保持一致的准确性,相较于基线模型,准确性提升显著。
1. 数据集构建
为增强RAG的鲁棒性,KV-Fusion模型在训练时引入了无关上下文。每个训练实例由一个金标准上下文和19个负上下文组成,确保模型能够有效区分相关信息。
2. 性能评估
通过精确匹配(EM)准确性作为评估指标,KV-Fusion在不同上下文位置下均表现出色。尤其是在上下文被随机打乱的情况下,KV-Fusion模型的准确性显著高于传统模型。
🎯 结论与未来工作
KV-Fusion为解决位置偏见问题提供了一种有效的解决方案,通过并行提取关键值缓存并注入统一的位置信息,显著提升了模型在RAG管道中的鲁棒性和一致性。尽管本研究主要集中在单跳问答任务上,未来的工作可以扩展到多跳推理任务,以进一步验证KV-Fusion的有效性。
通过对KV-Fusion的深入分析,我们希望为未来的研究提供启示,尤其是在如何更好地利用关键值缓存来训练语言模型方面。
📚 参考文献
- Guu, K. , et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.✅
- Lewis, M. , et al. (2021). Retrieval-Augmented Generation for Knowledge-Intensive Tasks.✅
- Karpukhin, V. , et al. (2020). Dense Passage Retrieval for Open-Domain Question Answering.✅
- Liu, Y. , et al. (2023). Understanding the 「Lost in the Middle」 Problem in LLMs.✅
- Oh, P. , & Thorne, J. (2023). Robustness and Bias in RAG Pipeline.✅
通过以上分析,我们不仅揭示了KV-Fusion的实现细节,还为理解其在实际应用中的潜力提供了基础。希望这篇文章能为读者提供清晰的视角,理解这一前沿技术的复杂性与美妙之处。