亲爱的读者,你是否曾经想过,我们能否让人工智能生成的图片更符合人类的审美呢?今天,我们就要带你探索这个问题的答案。我们将介绍如何使用DDPO(Denoising Diffusion Policy Optimization)通过TRL(Transformers Library)微调稳定扩散模型,从而使AI生成的图像更符合人类的审美。这是一场充满挑战与创新的神经网络冒险之旅,让我们一起启程吧!
一、DDPO与微调扩散模型的优势
首先,我们必须理解的是,DDPO不是微调扩散模型的唯一方法,但它的优势却是显而易见的。以计算效率和准确性为首的一系列特点,使得DDPO成为了扩散模型微调的理想选择。相比于之前的方法,DDPO将去噪步骤视为一个多步马尔可夫决策过程(MDP),并在最终获得奖励。这种全新的方法,使得代理策略能够成为一个各向同性的高斯分布,而不是一个复杂的分布。因此,DDPO不仅提高了计算效率,还减少了误差的堆积,为我们提供了更精准的结果。
二、DDPO算法简述
DDPO算法主要使用了一种策略梯度方法,即近端策略优化(PPO)。在使用PPO的过程中,我们注意到,DDPO算法的独特之处主要体现在轨迹收集部分。为了更好地理解这个过程,我们提供了一个简单的流程图,帮助你理解DDPO在动作中的运作方式。
三、DDPO与RLHF:增强审美性的混合
了解了DDPO的工作原理后,我们会发现,将DDPO与RLHF(Reinforcement Learning from Human Feedback)结合起来,可以更有效地让模型的输出符合人类的审美。在这个过程中,我们首先使用预训练的扩散模型,然后收集人类偏好的数据并使用它来训练奖励模型,最后使用DDPO和奖励模型进行微调。这个过程不仅高效,而且结果非常令人满意,得到的图像更符合人类审美。
四、使用DDPO训练稳定扩散模型
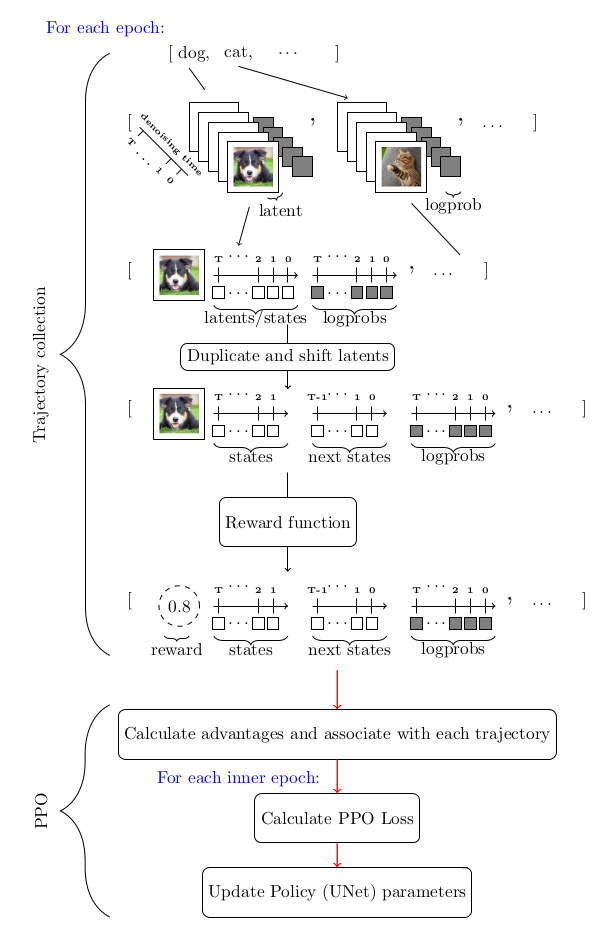
让我们深入了解一下如何使用DDPO训练稳定扩散模型。首先,你需要具备一定的硬件条件,例如拥有一台A100 NVIDIA GPU。然后,安装trl库和其他一些必要的依赖。在设置完硬件和软件环境后,你就可以开始实际的训练过程了。
我们的训练过程主要使用了trl库中的DDPOTrainer和DDPOConfig类。我们提供了一个示例训练脚本,该脚本利用这两个类和一些默认参数,对预训练的稳定扩散模型进行微调。在训练过程中,我们使用了一种审美奖励模型,该模型的权重是从公开的HuggingFace仓库中读取的。因此,你不需要自己收集数据和训练审美奖励模型。
最后,我们通过python命令启动训练脚本,然后就可以看到训练过程的实时输出了。这个过程可能需要一些时间,所以请耐心等待。完成训练后,你就可以使用微调后的模型生成新的图像了。
五、总结
今天,我们一起探讨了如何使用DDPO通过TRL微调稳定扩散模型。在这个过程中,我们深入了解了DDPO的优势和工作原理,以及如何将其与RLHF结合起来,以便更好地使模型的输出符合人类的审美。我们还详细介绍了使用DDPO训练稳定扩散模型的具体步骤。